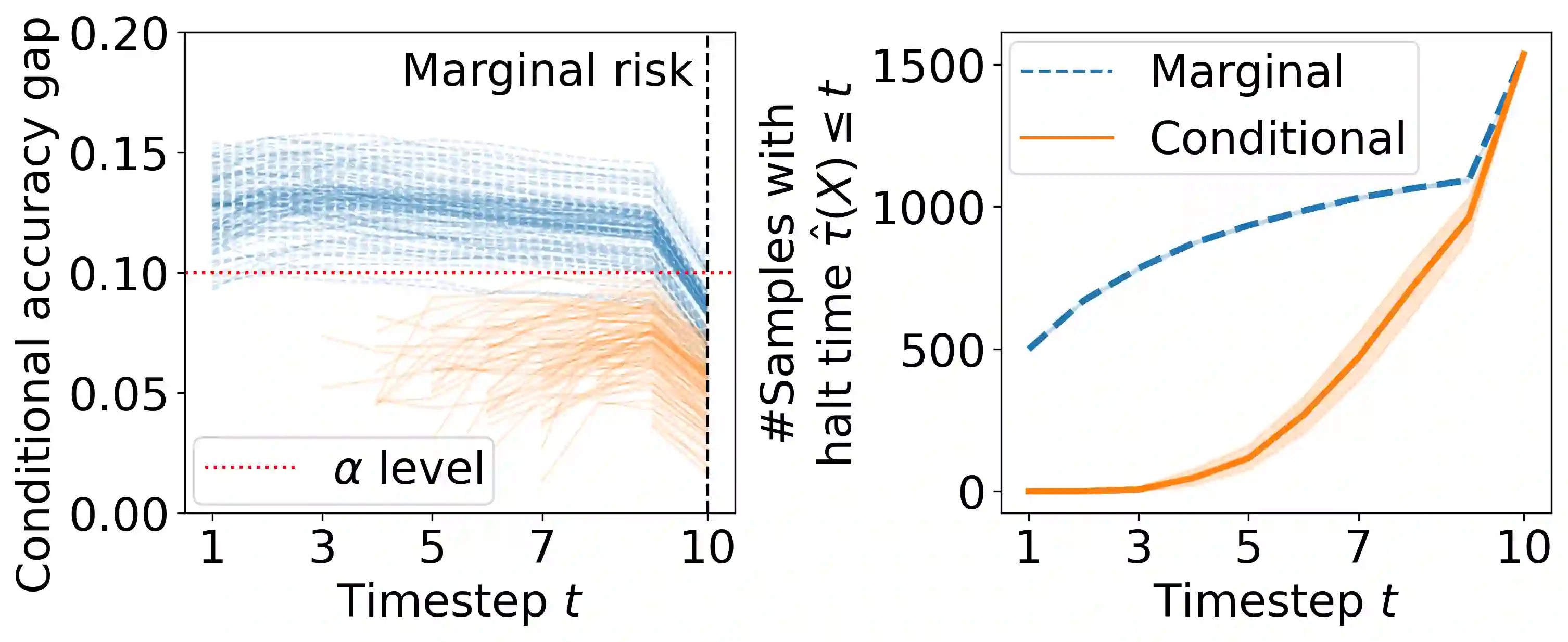
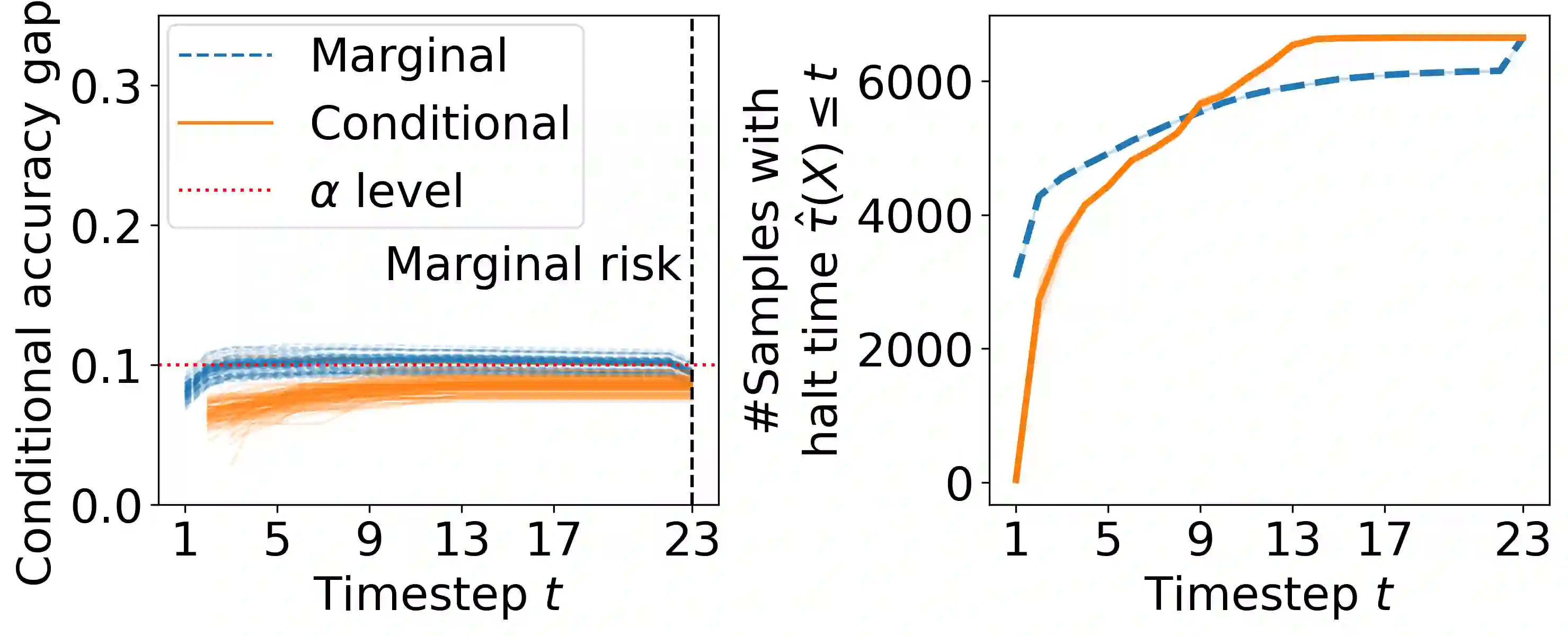
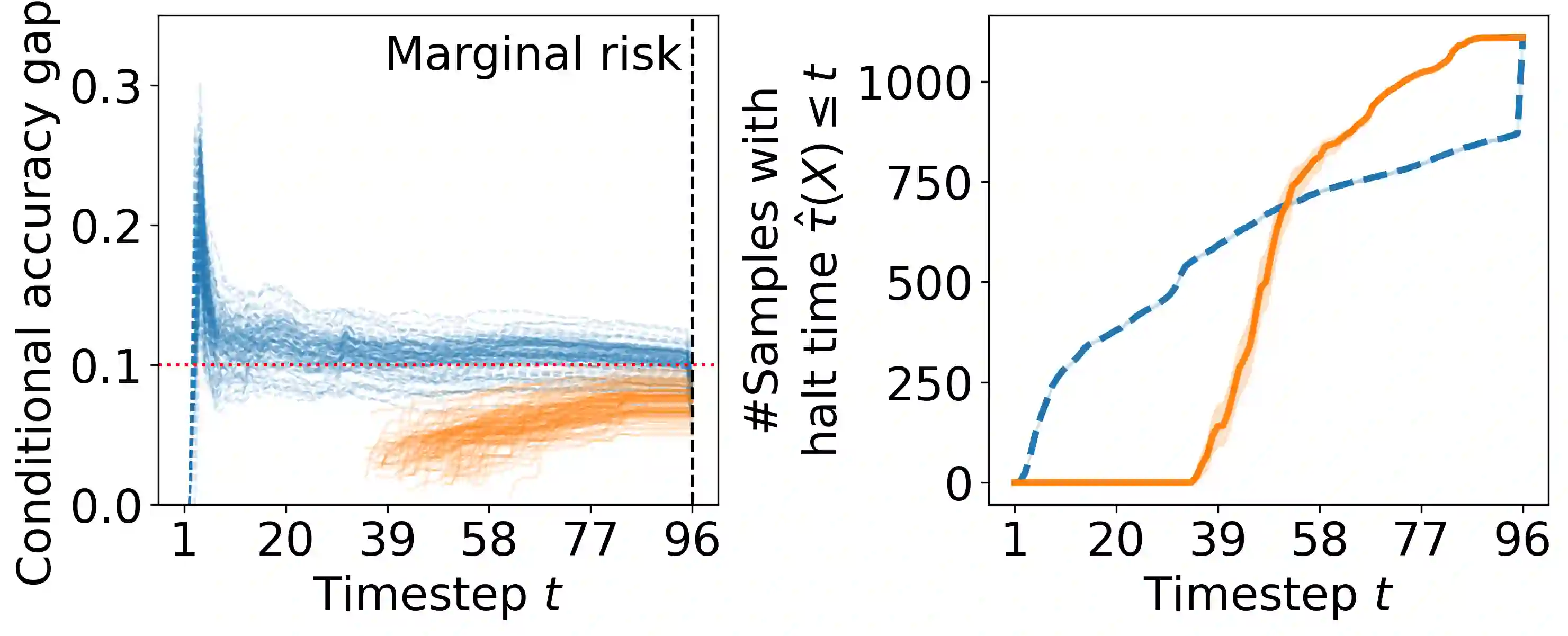
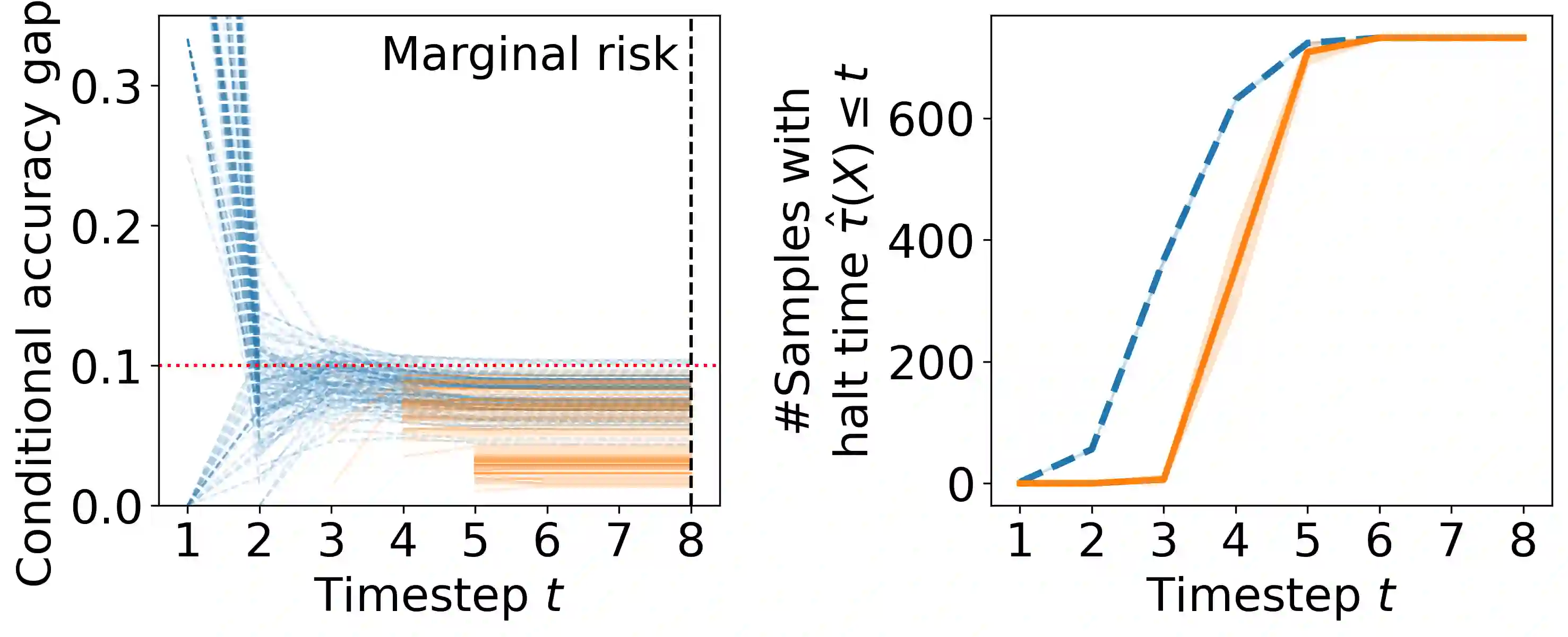
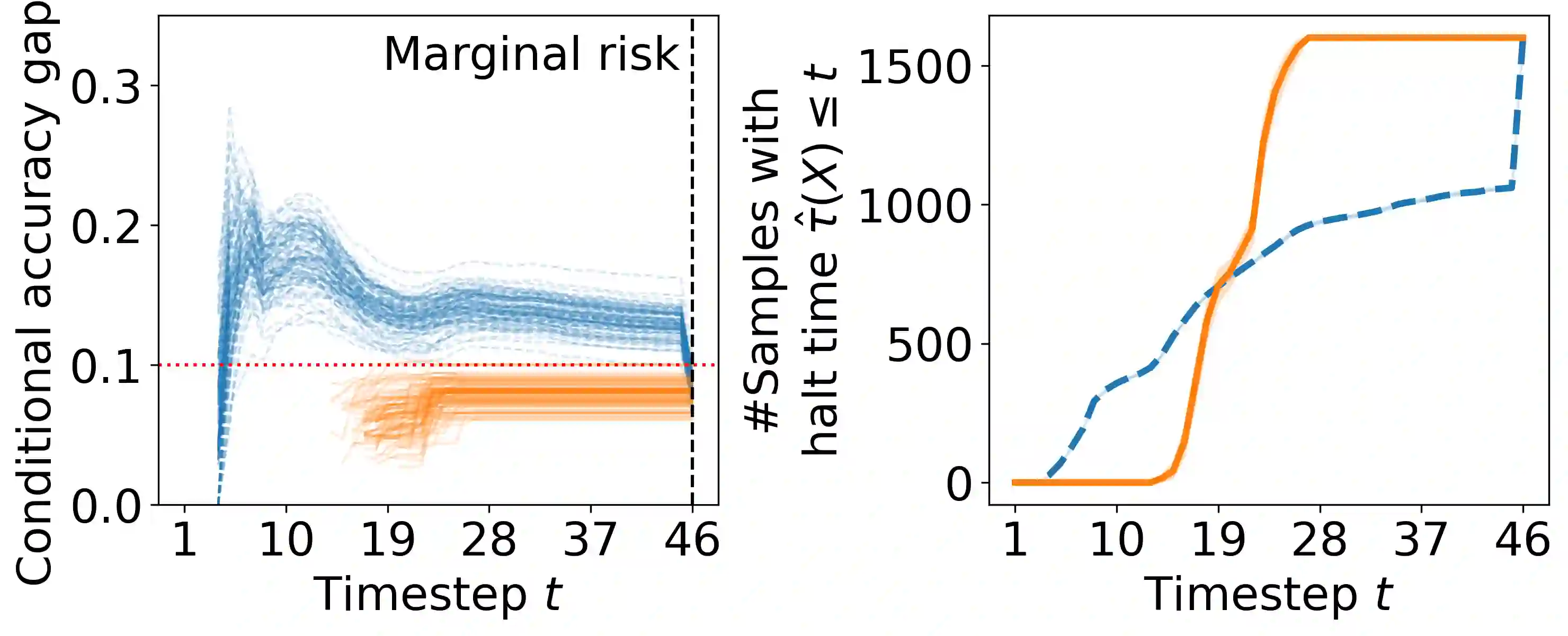
Early time classification algorithms aim to label a stream of features without processing the full input stream, while maintaining accuracy comparable to that achieved by applying the classifier to the entire input. In this paper, we introduce a statistical framework that can be applied to any sequential classifier, formulating a calibrated stopping rule. This data-driven rule attains finite-sample, distribution-free control of the accuracy gap between full and early-time classification. We start by presenting a novel method that builds on the Learn-then-Test calibration framework to control this gap marginally, on average over i.i.d. instances. As this algorithm tends to yield an excessively high accuracy gap for early halt times, our main contribution is the proposal of a framework that controls a stronger notion of error, where the accuracy gap is controlled conditionally on the accumulated halt times. Numerical experiments demonstrate the effectiveness, applicability, and usefulness of our method. We show that our proposed early stopping mechanism reduces up to 94% of timesteps used for classification while achieving rigorous accuracy gap control.
翻译:早期时间分类算法旨在在不处理完整输入特征流的情况下对数据进行标签分类,同时保持与使用完整输入分类器相当的准确率。本文提出了一种可应用于任何序列分类器的统计框架,并构建了校准的停止规则。该数据驱动的规则能够在有限样本且无分布假设的前提下,控制完整分类与早期时间分类之间的准确率差距。我们首先提出了一种基于"先学习后测试"校准框架的新方法,以在独立同分布实例的平均水平上边际控制这一差距。由于该算法在早期停止时间下易导致过高的准确率差距,我们的主要贡献是提出了一种控制更强误差概念的框架,该框架能基于累积停止时间条件性地控制准确率差距。数值实验证明了该方法的有效性、适用性和实用性。结果表明,我们提出的早期停止机制在实现严格准确率差距控制的同时,可减少高达94%的分类时间步长。