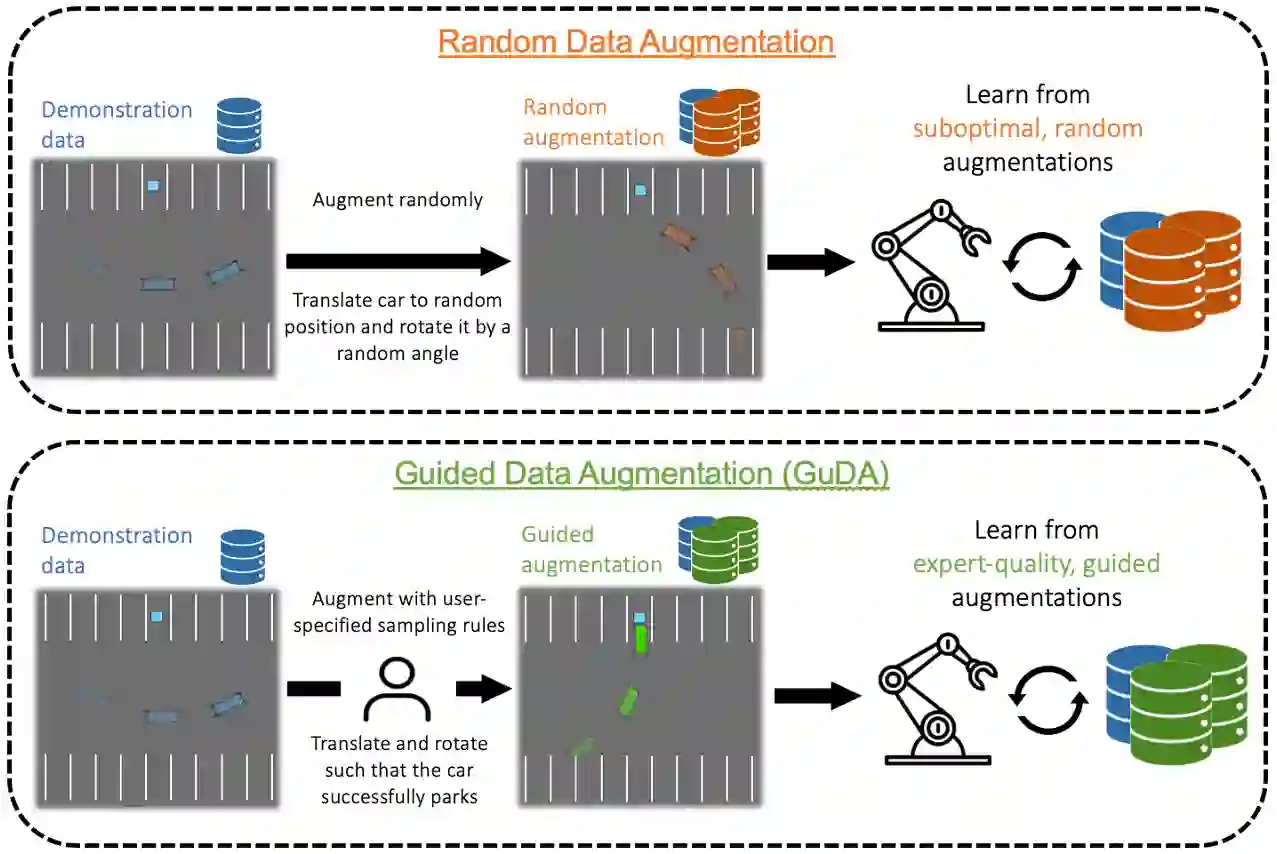
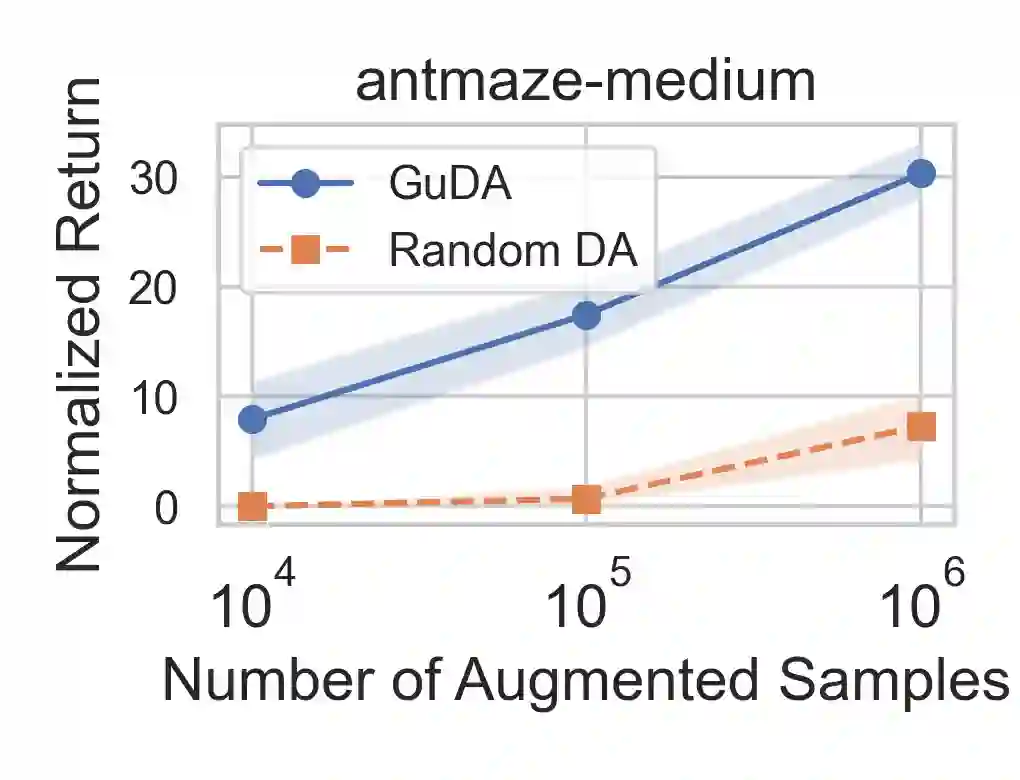
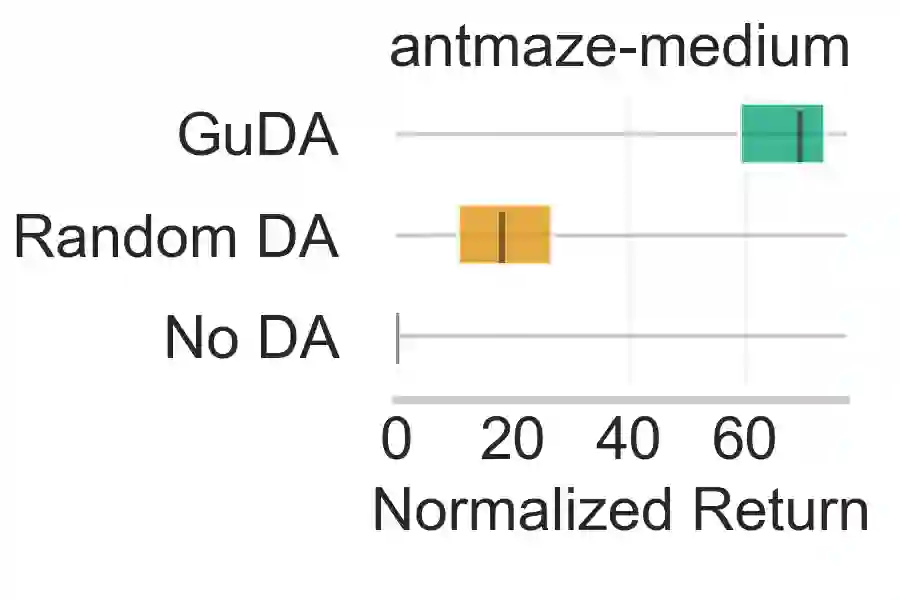
Learning from demonstration (LfD) is a popular technique that uses expert demonstrations to learn robot control policies. However, the difficulty in acquiring expert-quality demonstrations limits the applicability of LfD methods: real-world data collection is often costly, and the quality of the demonstrations depends greatly on the demonstrator's abilities and safety concerns. A number of works have leveraged data augmentation (DA) to inexpensively generate additional demonstration data, but most DA works generate augmented data in a random fashion and ultimately produce highly suboptimal data. In this work, we propose Guided Data Augmentation (GuDA), a human-guided DA framework that generates expert-quality augmented data. The key insight of GuDA is that while it may be difficult to demonstrate the sequence of actions required to produce expert data, a user can often easily identify when an augmented trajectory segment represents task progress. Thus, the user can impose a series of simple rules on the DA process to automatically generate augmented samples that approximate expert behavior. To extract a policy from GuDA, we use off-the-shelf offline reinforcement learning and behavior cloning algorithms. We evaluate GuDA on a physical robot soccer task as well as simulated D4RL navigation tasks, a simulated autonomous driving task, and a simulated soccer task. Empirically, we find that GuDA enables learning from a small set of potentially suboptimal demonstrations and substantially outperforms a DA strategy that samples augmented data randomly.
翻译:从演示中学习是一种利用专家演示来学习机器人控制策略的流行技术。然而,获取专家级演示的难度限制了该方法的应用:真实世界的数据收集往往成本高昂,且演示质量极大依赖于演示者的能力及安全性考量。已有研究利用数据增强廉价生成额外演示数据,但多数方法以随机方式生成增强数据,最终产生高度次优的数据。本研究提出引导式数据增强框架,这是一种人类引导的数据增强方法,可生成专家质量的增强数据。GuDA的核心洞见在于:尽管生成专家数据所需的动作序列难以演示,但用户通常能轻易识别增强轨迹片段是否代表任务进展。因此,用户可在数据增强过程中施加一系列简单规则,自动生成近似专家行为的增强样本。为从GuDA提取策略,我们使用现成的离线强化学习和行为克隆算法。我们在物理机器人足球任务、模拟D4RL导航任务、模拟自动驾驶任务及模拟足球任务上评估GuDA。实验表明,GuDA能基于少量可能次优的演示进行学习,且性能显著优于随机采样增强数据的策略。