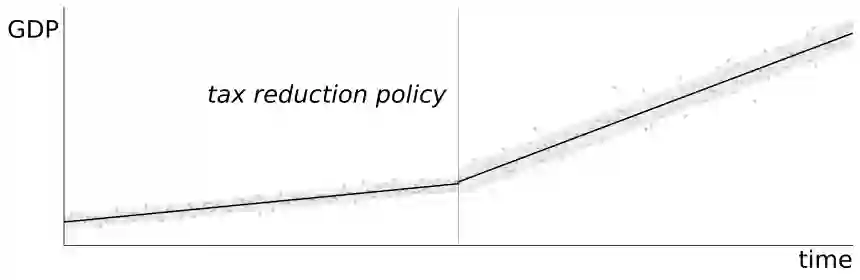
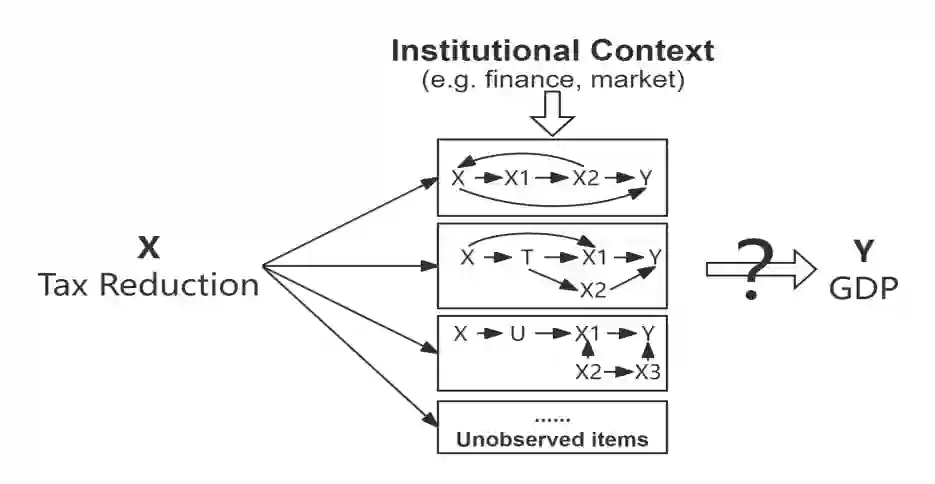
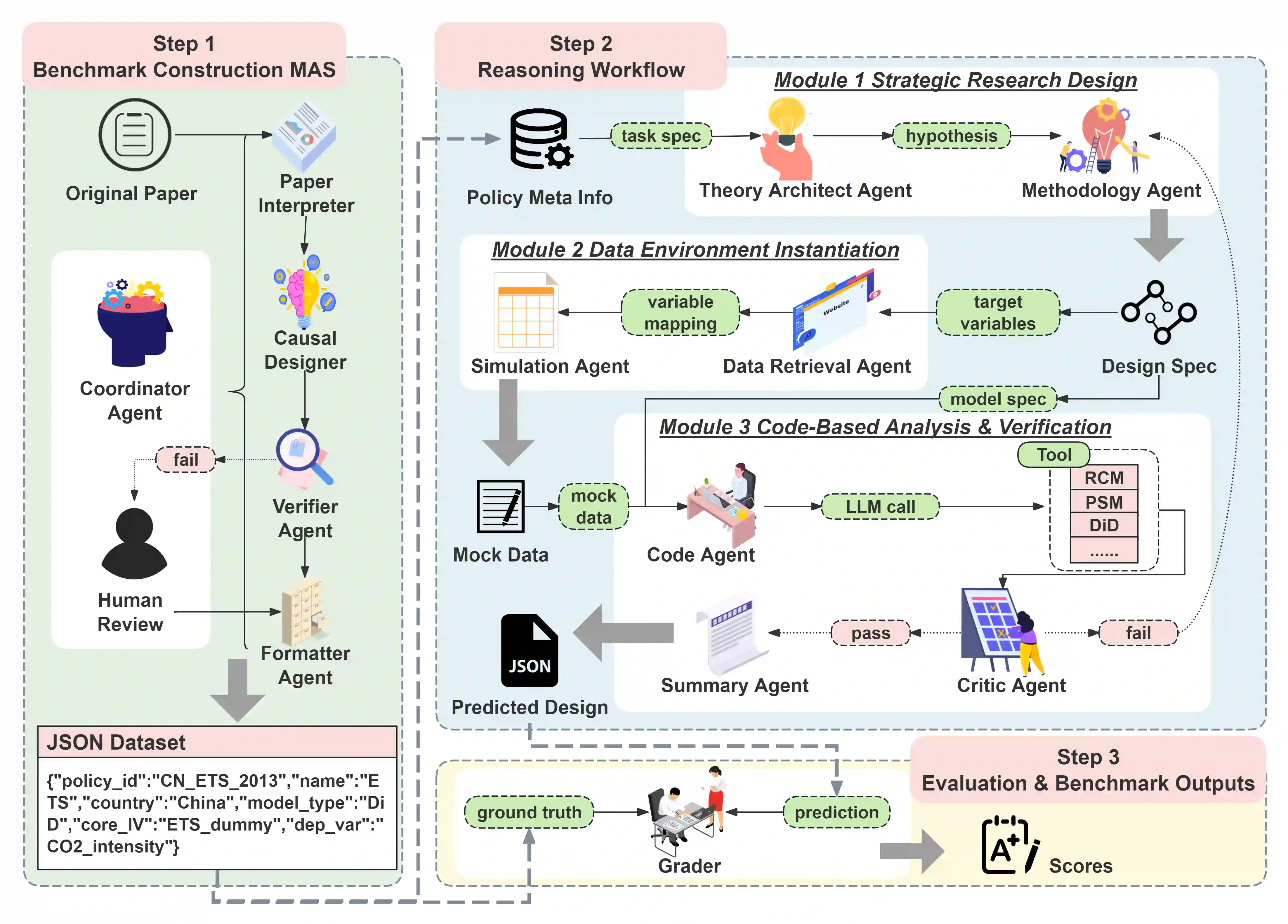
Causal inference in social science relies on end-to-end, intervention-centered research-design reasoning grounded in real-world policy interventions, but current benchmarks fail to evaluate this capability of large language models (LLMs). We present InterveneBench, a benchmark designed to assess such reasoning in realistic social settings. Each instance in InterveneBench is derived from an empirical social science study and requires models to reason about policy interventions and identification assumptions without access to predefined causal graphs or structural equations. InterveneBench comprises 744 peer-reviewed studies across diverse policy domains. Experimental results show that state-of-the-art LLMs struggle under this setting. To address this limitation, we further propose a multi-agent framework, STRIDES. It achieves significant performance improvements over state-of-the-art reasoning models. Our code and data are available at https://github.com/Sii-yuning/STRIDES.
翻译:社会科学中的因果推断依赖于基于现实政策干预的端到端、以干预为中心的研究设计推理,然而现有基准未能评估大语言模型(LLMs)的此项能力。我们提出InterveneBench,一个为评估真实社会场景中此类推理能力而设计的基准。InterveneBench中的每个实例均源自实证社会科学研究,要求模型在无法获取预定义因果图或结构方程的条件下,对政策干预与识别假设进行推理。该基准涵盖多个政策领域的744项同行评议研究。实验结果表明,当前最先进的大语言模型在此设定下表现欠佳。为应对这一局限,我们进一步提出一个多智能体框架STRIDES,其在性能上显著超越了现有最先进的推理模型。我们的代码与数据公开于https://github.com/Sii-yuning/STRIDES。