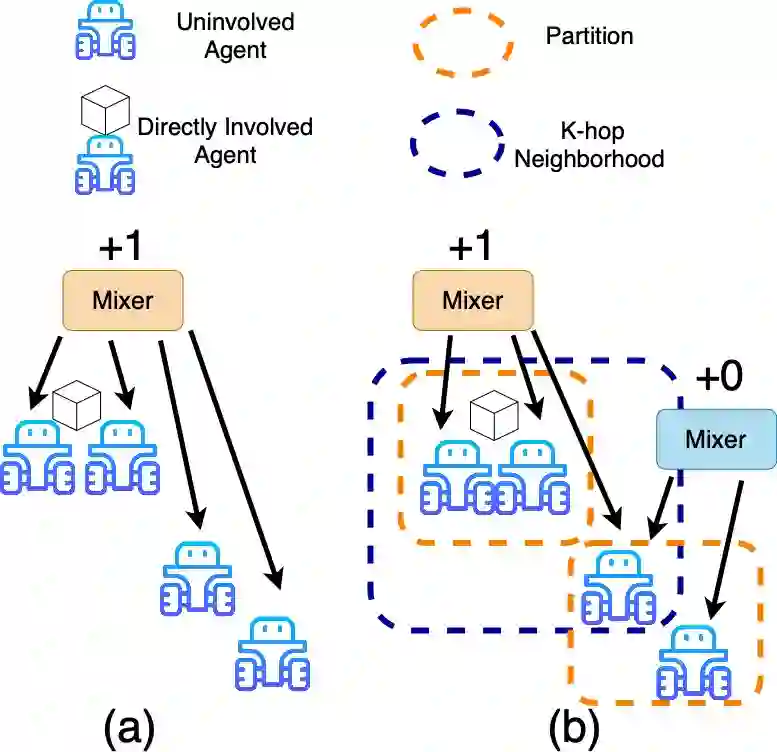
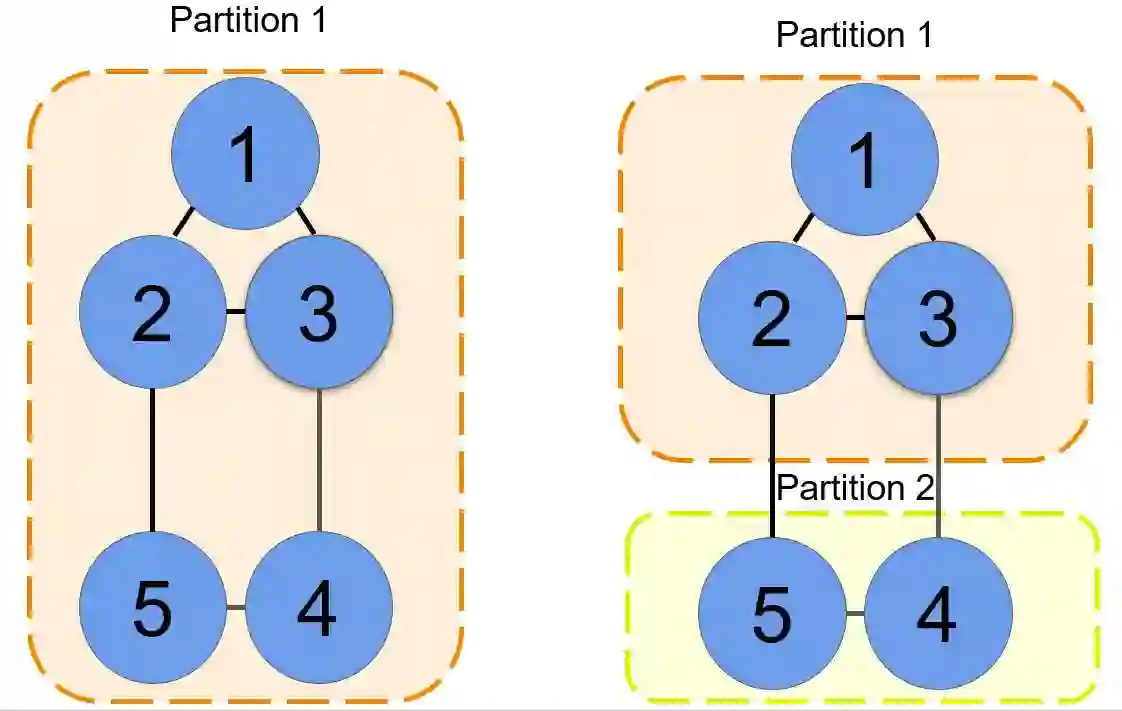
In this work, we present a novel cooperative multi-agent reinforcement learning method called \textbf{Loc}ality based \textbf{Fac}torized \textbf{M}ulti-Agent \textbf{A}ctor-\textbf{C}ritic (Loc-FACMAC). Existing state-of-the-art algorithms, such as FACMAC, rely on global reward information, which may not accurately reflect the quality of individual robots' actions in decentralized systems. We integrate the concept of locality into critic learning, where strongly related robots form partitions during training. Robots within the same partition have a greater impact on each other, leading to more precise policy evaluation. Additionally, we construct a dependency graph to capture the relationships between robots, facilitating the partitioning process. This approach mitigates the curse of dimensionality and prevents robots from using irrelevant information. Our method improves existing algorithms by focusing on local rewards and leveraging partition-based learning to enhance training efficiency and performance. We evaluate the performance of Loc-FACMAC in three environments: Hallway, Multi-cartpole, and Bounded-Cooperative-Navigation. We explore the impact of partition sizes on the performance and compare the result with baseline MARL algorithms such as LOMAQ, FACMAC, and QMIX. The experiments reveal that, if the locality structure is defined properly, Loc-FACMAC outperforms these baseline algorithms up to 108\%, indicating that exploiting the locality structure in the actor-critic framework improves the MARL performance.
翻译:本文提出了一种新颖的协作式多智能体强化学习方法,称为**基于局部性的因子化多智能体演员-评论家算法**。现有的最先进算法,例如FACMAC,依赖于全局奖励信息,这可能无法准确反映去中心化系统中单个机器人动作的质量。我们将局部性概念整合到评论家学习中,其中强相关的机器人在训练期间形成分区。同一分区内的机器人彼此影响更大,从而带来更精确的策略评估。此外,我们构建了一个依赖图来捕获机器人之间的关系,以促进分区过程。这种方法缓解了维度灾难,并防止机器人使用无关信息。我们的方法通过关注局部奖励并利用基于分区的学习来提高训练效率和性能,从而改进了现有算法。我们在三个环境中评估了Loc-FACMAC的性能:走廊、多倒立摆和有界协作导航。我们探讨了分区大小对性能的影响,并将结果与基线MARL算法(如LOMAQ、FACMAC和QMIX)进行了比较。实验表明,如果局部性结构定义得当,Loc-FACMAC的性能最高可超越这些基线算法108%,这表明在演员-评论家框架中利用局部性结构可以提高MARL性能。