摘要——人工智能生成内容(AIGC)的飞速发展彻底改变了视频生成领域。从以 OpenAI 的 Sora、Google 的 Veo3 和字节跳动的 Seedance 为代表的封闭源代码先驱,到以 Wan 和混元视频(HunyuanVideo)为代表的强大开源竞争者,这些系统已能够合成时序连贯且语义丰富的视频。这些进步为构建模拟现实世界动态的“世界模型”铺平了道路,其应用涵盖娱乐、教育及虚拟现实等多个领域。然而,现有的视频生成综述往往聚焦于狭窄的技术领域(如生成对抗网络 GAN 或扩散模型)或特定任务(如视频编辑),缺乏对该领域演进过程的全面视角,尤其是在自回归(AR)模型及多模态信息整合方面。 为填补这些空白,本综述首先对视频生成技术的发展进行了系统性回顾,追踪了其从早期的 GAN 演进到主流的扩散模型,并进一步向新兴的基于自回归及多模态技术发展的历程。我们对底层原理、关键进展以及各自的优劣势进行了深入分析。随后,我们探讨了多模态视频生成的新兴趋势,强调了通过整合多样化数据类型以增强上下文感知能力。最后,通过衔接历史发展与当代创新,本综述提出了相关见解,旨在指导视频生成及其应用(包括虚拟/增强现实、个性化教育、自动驾驶仿真、数字娱乐及高级世界模型)在这一快速演进领域的未来研究。更多细节请参阅项目页面:https://github.com/sjtuplayer/Awesome-Video-Foundations。 索引词——视频生成,生成对抗网络 (GAN),扩散模型,自回归模型,多模态生成
1 引言
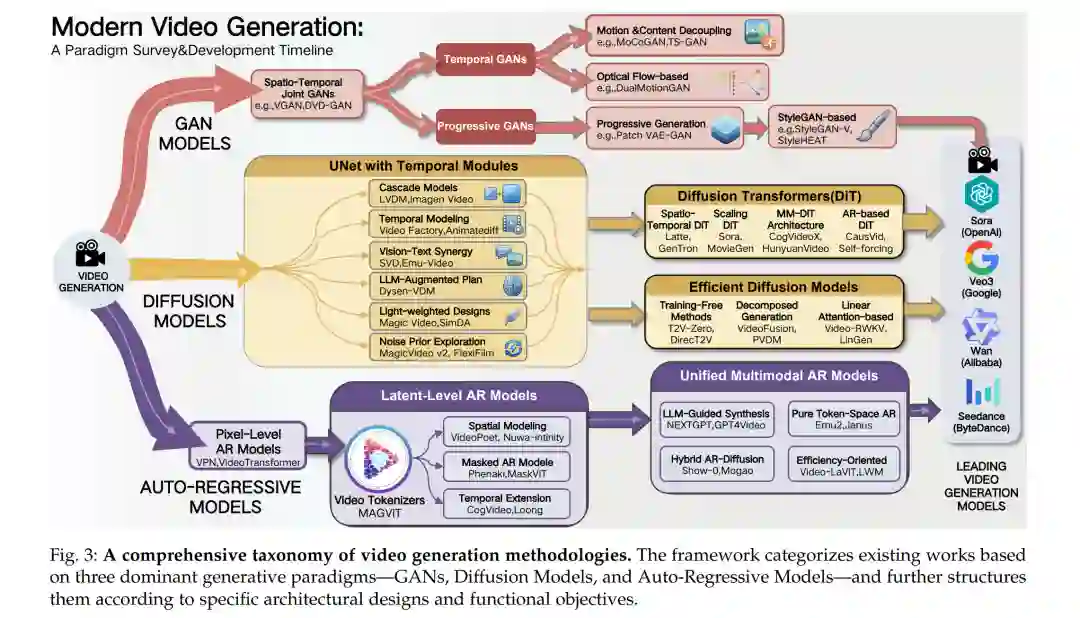
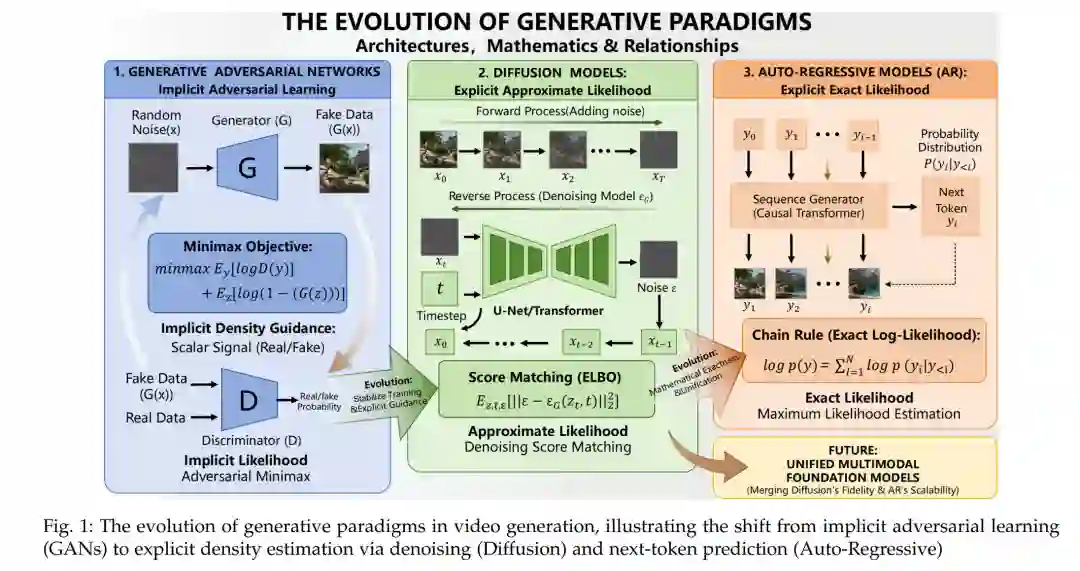
人工智能生成内容(AIGC)的迅猛发展与广泛普及,在扩散模型 [1]–[3] 的主要驱动下,显著改变了视频生成的格局。当代闭源系统如 OpenAI 的 Sora [4]、Google 的 Veo3 [5] 和字节跳动的 Seedance [6],以及具有影响力的开源模型如 Wan [7] 和混元视频(HunyuanVideo)[8],在合成时序连贯且语义丰富的视频方面展现了前所未有的能力。这些多元化的进展预示着构建可交互“世界模型”(world models)的宏伟前景——即通过对环境的全面表征,使机器能够以类似于人类认知的方式理解、预测并与世界互动。这些进步不仅重新定义了内容创作的工作流,还为视频生成中物理与社会动力学的模拟提供了新范式,为世界建模开辟了新路径,并为以卓越的精度和创造力创作及操控视频内容提供了前所未有的机遇。这些进展的影响是深远的,它们不仅增强了内容创作者的能力,还为娱乐、教育和虚拟现实等多个领域的研究与应用开辟了新途径。 现有的视频生成综述主要集中于特定方面或应用 [9], [10],缺乏对视频生成领域的全面且长期的视角。虽然部分研究 [11]–[13] 孤立地探讨了基于 GAN 或基于扩散的方法,但其他研究则侧重于特定任务,如视频编辑 [14]、人物视频生成 [10] 以及长视频生成 [9]。这些工作通常未能分析视频生成技术的宏观演进,也忽略了对不同方法论(如 GANs [15]、扩散模型 [1] 和自回归 (AR) 方法)随时间推移的优劣势对比。此外,针对基于 AR 的视频生成,特别是其在多模态潜力背景下的深入探索仍显著缺失。随着多模态方法日益凸显,视觉生成与理解的整合变得愈发重要,然而这种融合在现有文献中尚未得到充分探讨。因此,一份能够衔接历史发展与新兴趋势,并批判性地评估不同技术范式间相互作用的全面综述,对于引导这一快速发展领域的未来研究与应用至关重要。 针对上述空白,我们提出了一项全面的综述,追踪视频生成从 GANs [15], [16] 到当前主流的扩散模型 [1]–[3],再到极具前景的基于 AR 和多模态生成技术 [17], [18] 的演进历程。本综述旨在对视频生成的过去、现在和未来进行深入分析,比较各种架构的发展轨迹与优势。通过这种方式,我们力求为不同视频生成方法论的相对优势和局限性提供有价值的见解。我们的综述将涵盖每种方法的基础原理,阐述关键进展,并讨论这些技术对未来研究和应用的深远影响。我们还将探讨多模态生成的潜力,即通过多种数据类型和感官输入的整合,实现更复杂且具上下文感知能力的视频生成系统。通过这一全面分析,我们旨在弥补现有文献的不足,提供对视频生成格局的透彻理解,并为这一充满活力且快速发展的领域提供未来研发指南。
研究范围:本综述聚焦于三种主流的视频生成范式——基于 GAN、基于扩散和基于自回归(AR)的方法,并对每种方法论的基础原理、关键进展以及相对优劣势进行了深入分析。此外,我们探讨了多模态视频生成的新兴趋势,强调整合多种数据类型和感官输入以提升视频生成模型的上下文感知能力和复杂程度。不同于以往常聚焦于特定层面 [11]–[13] 或应用 [9], [14] 的综述,本研究涵盖了更广泛的技术模型和方法论,特别是重点介绍了强有力的基于扩散的方法和极具前景的基于 AR 的方法。通过衔接历史轨迹与当代创新,本综述旨在为不断发展的视频生成领域提供宝贵的见解和研究指南。 * 综述框架:在第 2 节中,我们涵盖了基础视频生成模型的主要背景知识。随后,在第 3 节中,我们概述了视频生成领域开发的方法。在第 4 节中,我们介绍了当前领先的视频生成模型及主要基准测试(benchmarks)。最后,在第 5 节中,我们深入探讨了视频生成下游任务的相关主要研究。