摘要——后训练已成为将广泛预训练的大语言模型(LLMs)转化为对齐、胜任特定任务且具备部署能力的系统的核心阶段。近期研究进展涵盖了监督微调(SFT)、偏好优化、强化学习(RL)、过程监督、验证器引导方法、知识蒸馏以及日益复杂的逻辑多阶段流水线。然而,这些方法通常仍以碎片化的方式被讨论,即根据历史标签或目标函数家族进行分类,而非基于其所解决的底层行为瓶颈。
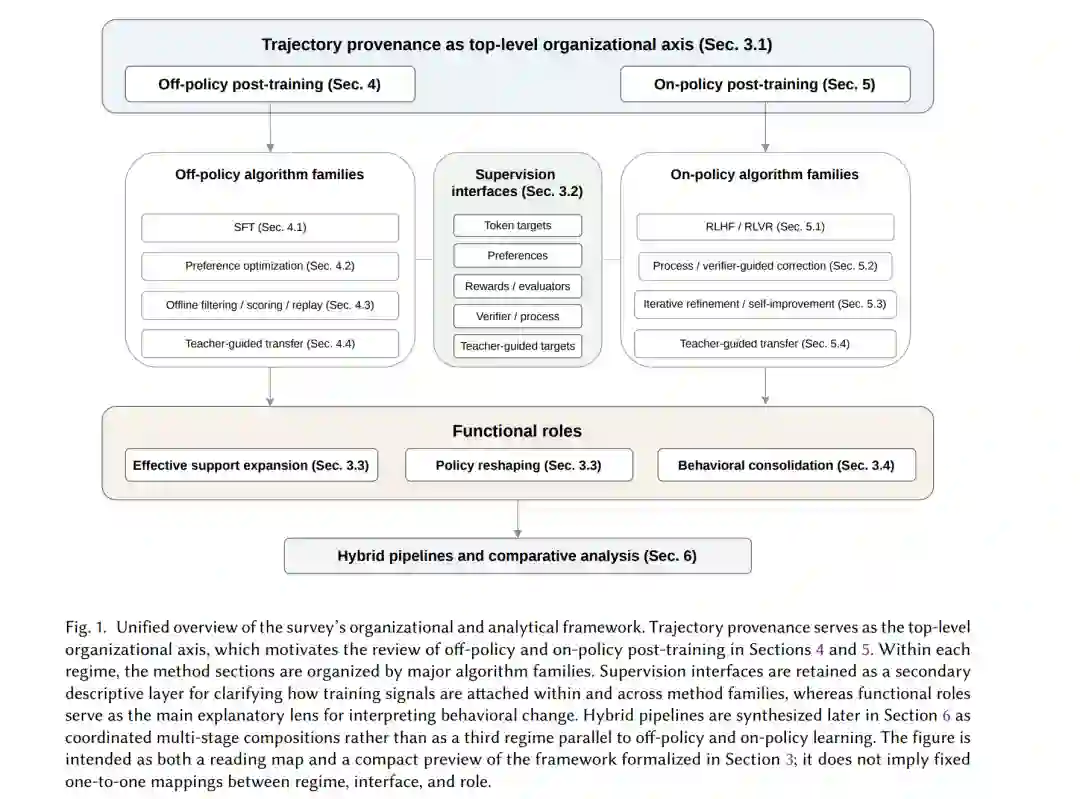
本综述认为,LLM 后训练应被理解为对模型行为的结构化干预。我们首先根据轨迹来源对该领域进行组织,由此定义了两种主要的学习范式:离策学习(利用外部提供的轨迹改进模型)和在策学习(利用学习器生成的采样序列改进模型)。随后,我们通过两种反复出现的分布级角色来诠释主流方法——有效支撑集扩张(使有用行为更可靠地触达)和策略重塑(在已触达区域内改进行为)——以及一种互补的系统级角色,即行为巩固(在后训练阶段和模型迁移过程中保留、转移并摊销有用行为)。
这一视角为主要的后训练范式提供了统一的解读。在此视角下,SFT 既可以服务于支撑集扩张,也可以服务于策略重塑;而基于偏好的方法通常属于离策重塑。在策 RL 通常改进学习器生成状态下的行为,但在强引导下,它也能使先前难以触达的推理路径变得有效触达。蒸馏通常被理解为一种巩固机制而非仅仅是压缩,而混合流水线则不再是随机的目标函数堆叠,而是协同的多阶段组合。
总体而言,该框架有助于诊断后训练瓶颈并推导阶段间的组合逻辑,这表明 LLM 后训练的进展将日益依赖于跨范式、角色和阶段的协同系统设计,而非单一的主导目标函数。
1 引言
在现代大语言模型(LLM)体系中,仅靠预训练已不足够:后训练已成为将广泛预训练的模型转化为对齐、胜任任务且具备部署能力系统的核心阶段。在实践中,这一阶段通过多种技术实现,包括监督微调(SFT)、偏好优化、强化学习(RL)、过程监督与验证器引导方法、知识蒸馏以及日益复杂的逻辑多阶段流水线 [1–7]。这些方法塑造了模型的指令遵循、推理、安全对齐、可控性及部署效率。近期的系统报告进一步表明,后训练设计已成为前沿系统间能力差异的核心来源 [7–10]。 尽管进展迅速,但对后训练的概念理解仍显碎片化。大量文献仍按历史标签或目标函数家族进行组织:指令微调与偏好优化被分开讨论;来自人类反馈的强化学习(RLHF)及相关对齐导向的方法,往往与带可验证奖励的强化学习(RLVR)及推理导向的方法割裂;而蒸馏通常主要被视为压缩手段,而非更广泛后训练过程的一部分 [11–15]。这种碎片化掩盖了一个日益重要的事实:这些方法并非孤立的替代方案,而是对同一底层对象——由轨迹分布诱导的模型行为——进行干预的不同方式。因此,现有的比较往往停留在目标函数形式层面,而忽略了更深层的行为问题:一种方法能引入何种行为,它能直接观察到哪些失败,以及为什么强大的系统通常结合多种范式而非依赖单一范式。 随着后训练从相对简单的指令微调流水线转向显式的多阶段系统,这些问题变得愈发紧迫。早期的指令微调模型通常被界定为在精选的“指令-回复”示例上进行的监督适配 [1, 16–21]。而近期的系统越来越多地结合了离线监督、偏好优化、在线强化学习、过程或验证器引导的反馈、经验回放增强的策略优化,以及后期阶段的教师引导迁移 [2, 3, 7, 22–24]。因此,该领域看起来不再是一系列孤立目标函数的菜单,而更像是一个系统工程问题:如何建立有用行为,在学习器生成状态下对其进行精炼,并在阶段转换间对其进行保留。 本综述认为,组织这一领域的一种有效方式是首先区分由轨迹来源定义的两种学习范式:离策学习(在外部提供的轨迹上改进模型)和在策学习(在学习器生成的采样序列上改进模型)。这一顶层区分构成了本综述主要方法章节的组织架构。在每个特定范式的章节中,方法按主要算法家族进一步分组以利于阅读和比较。监督接口被保留作为次要描述层,而功能性角色则作为本文的主要解释视角。正式定义将在第 3 节展开;图 1 提供了该组织架构的简明概览。 综述范围。本综述聚焦于通用预训练后的 LLM 后训练方法,特别是旨在提升指令遵循、对齐、推理及其他部署相关能力的方法。我们涵盖了监督微调、基于偏好的学习、RLHF 和 RLVR 式方法、过程监督与验证器引导方法、蒸馏与教师引导迁移,以及混合后训练系统。在必要时,我们也参考了与部署相关的设置(如红队对抗、检索增强推理、工具使用及智能体系统报告),前提是它们能为后训练设计或后训练行为的迁移提供证据 [7, 25–28]。我们不打算对预训练、检索增强、推理时扩展或工具使用作为独立课题进行全面综述,尽管当它们实质性影响后训练设计时,有时会进入讨论。 文献覆盖与筛选说明。本综述是一项具有代表性的、概念驱动的综述,而非穷尽式的系统评价。我们优先考虑对理解后训练设计最有帮助的论文和系统报告,包括基础方法、广泛使用的目标函数、重要的推理与对齐变体、迁移导向的方法以及前沿的多阶段流水线。存档论文构成了本综述概念主张的支柱,而近期的系统报告和精选预印本则被更有选择性地用于说明实践中新兴的设计模式。在本综述中,“离策”与“在策”或“支撑集扩张”与“策略重塑”等分类应被理解为本框架下的主导性分析分配,而非不可更改的标签。
本综述的贡献。除了提供更清晰的分类学,本综述还为组织、比较和解释 LLM 后训练提供了一个统一框架。本综述不再将主要范式视为孤立的目标函数家族,而是通过一组共同问题进行分析:学习发生在何处、监督信号如何挂载,以及一个阶段主要承担何种行为改变或系统角色。从实践角度看,这一视角旨在帮助诊断:何时最适合通过外部监督引入有用行为,何时应在学习器生成状态下对其进行纠正,以及何时必须跨阶段边界对其进行保留或迁移。 本综述的主要贡献有四:
提出了轨迹来源作为 LLM 后训练的统一顶层组织轴,利用离策学习与在策学习的区别,根据优化实际发生的地点来构建领域版图。 1. 保留了监督接口作为次要描述层,使标记目标(token targets)、偏好、奖励衍生信号、基于验证器或过程的反馈以及教师引导目标,能在跨后训练范式的共享词汇表中进行比较。 1. 引入了以有效支撑集扩张、策略重塑和行为巩固为核心的功能角色分析,从而为刻画后训练阶段的主导行为效应或系统角色提供了共同的解释性词汇。 1. 利用这一分层框架在单一分析语言下比较主要范式,解释了为何混合流水线会自然地作为协同的多阶段系统出现,并揭示了关于学习器状态纠正、支撑集损耗、巩固及阶段组合的开放问题。
与现有综述的关系。表 1 将本综述与以往关于后训练文献主要分支的综述进行了对比。本框架与以往综述的主要区别在于组织方式而非评价标准。以往的许多综述是围绕特定方法族或应用领域构建的;相比之下,本综述以轨迹来源为顶层轴,利用功能角色分析来比较阶段内的行为变化与跨阶段的保留,将蒸馏视为跨阶段迁移而非仅是压缩,并显式地合成多阶段后训练组合。 综述结构。第 2 节介绍最基本的正式与概念背景。第 3 节将统一框架形式化。第 4 节和第 5 节分别回顾离策与在策后训练。第 6 节合成混合流水线并进行范式比较。第 7 节讨论新兴方向与悬而未决的开放问题,第 8 节总结。