
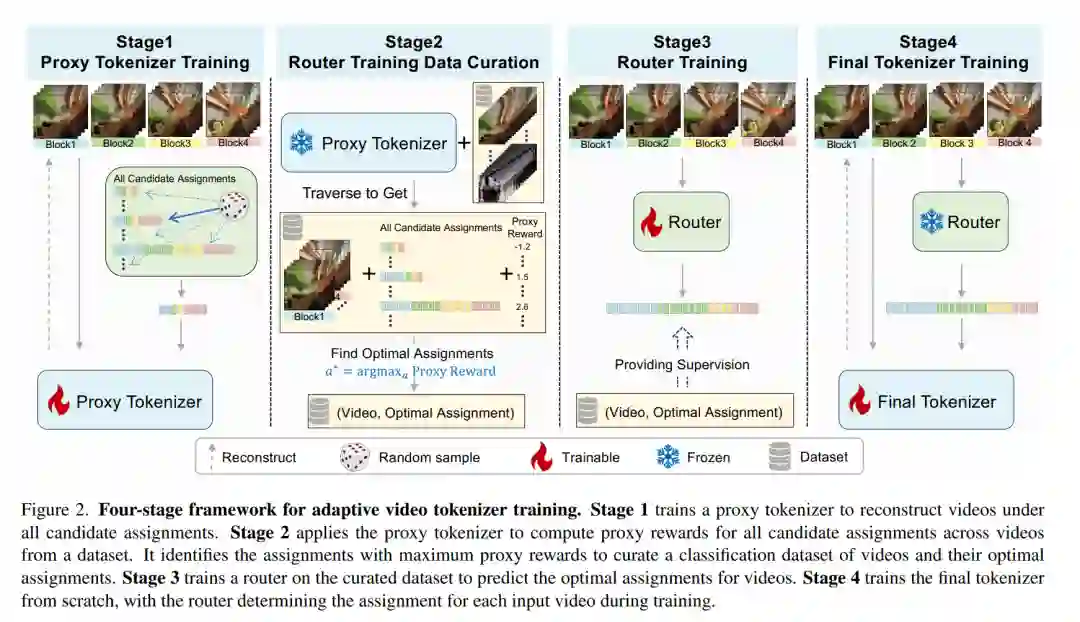
摘要——自回归(AR)视频生成模型依赖于视频标记器将像素压缩为离散标记序列。这些标记序列的长度对于平衡重建质量与下游生成的计算成本至关重要。传统的视频标记器在不同视频的时域块上采用均匀的标记分配方案,这往往导致在简单、静态或重复的片段上浪费标记,而对动态或复杂片段的采样则显不足。为了解决这一低效问题,我们引入了 EVATok,这是一个用于构建**高效视频自适应标记器(Efficient Video Adaptive Tokenizers)**的框架。我们的框架首先估计每个视频的最优标记分配方案,以实现最佳的质量-成本权衡;随后开发了轻量级路由器以快速预测这些最优分配;并训练自适应标记器根据路由器预测的分配方案对视频进行编码。我们证明了 EVATok 在视频重建及下游自回归生成任务中,均能显著提升效率与整体质量。得益于整合了视频语义编码器的高级训练方案,EVATok 在 UCF-101 数据集上实现了卓越的重建效果和最先进的(SOTA)类别到视频生成表现。与先前的 SOTA 模型 LARP 以及我们的固定长度基准模型相比,EVATok 节省了至少 24.4% 的平均标记使用量。
成为VIP会员查看完整内容
相关内容

最新内容
相关VIP内容
相关资讯