
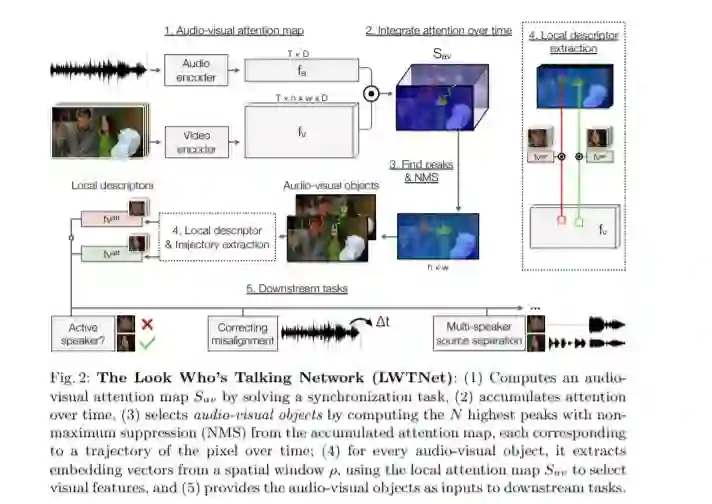
我们的目标是利用自监督学习将视频转换成一组离散的视听对象。为此,我们介绍了一个模型,它使用注意力来定位和分组声源,以及光流来随时间聚合信息。我们通过使用我们的模型学习的视听对象嵌入四个下游的面向语音的任务(a)多说话人的声源分离,(b)定位和跟踪说话人,(c)纠正不正确的视听数据,和(d)主动说话人检测的有效性。利用我们的表示法,这些任务完全可以通过训练未标记的视频来解决,而不需要物体检测器的帮助。我们还通过将我们的方法应用于非人类演讲者,包括卡通和木偶,来展示我们方法的普遍性。我们的模型显著优于其他自监督方法,并获得与使用监督人脸检测方法竞争的性能。
Self-Supervised Learning of Audio-Visual Objects from Video
成为VIP会员查看完整内容
相关内容

专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月12日
最新内容
相关VIP内容
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
36+阅读 · 2020年3月12日
相关资讯