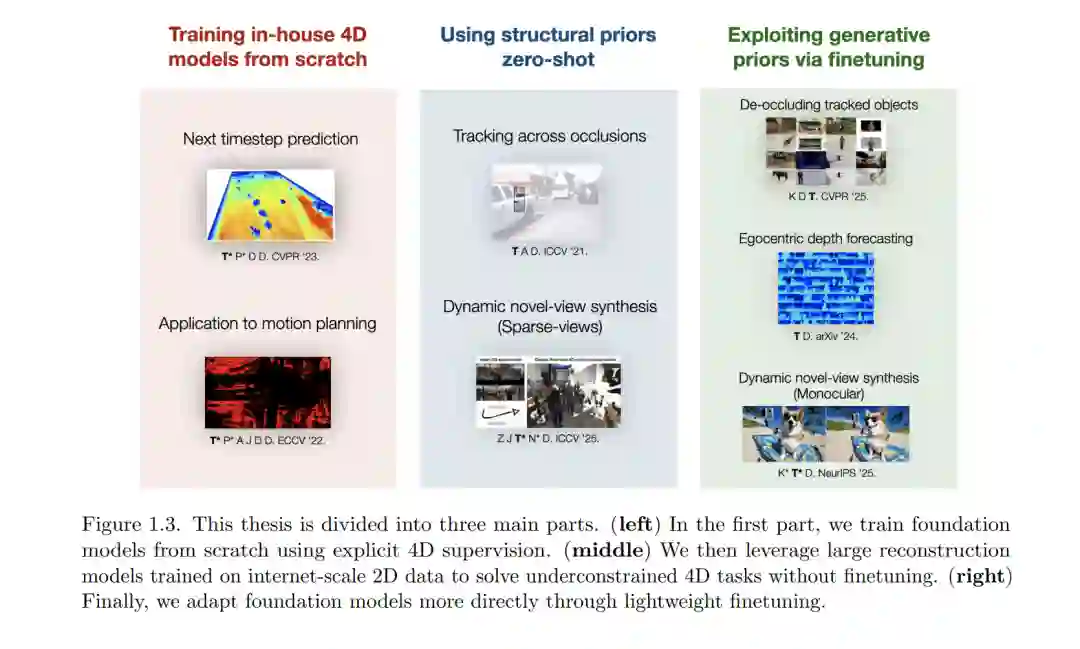
作为人类,我们无时无刻不在与一个三维的动态世界进行交互并对其进行观察。然而,在视觉算法中构建这种时空(Spatiotemporal)或 4D 理解并非易事,因为 4D 数据的规模比 2D 图像和视频少几个数量级。这凸显了寻找有效方法利用 2D 数据来实现 4D 任务的必要性。 近期,构建“基础模型(Foundation Models)”方面的进展——即通过互联网级数据以数据驱动的方式学习生成式或结构化先验——使我们能够“免费”获得这些丰富的现实世界先验。在本论文中,我们研究了如何针对 非全貌跟踪与补全(Amodal Tracking and Completion)、动态重建(Dynamic Reconstruction)以及 下一时刻预测(Next-timestep Prediction)等 4D 感知任务,对这些先验进行调整(Tuning)。 我们从三个互补的方向展开研究:
首先,在缺乏基础先验的情况下,我们通过自监督方式自行构建先验。 具体而言,我们利用动态场景的 3D LiDAR 扫描序列执行下一时刻预测任务。重要的是,我们证明了利用 4D 表征(4D Representation)作为下一时刻预测的瓶颈(Bottlenecking)至关重要。研究发现,此类预测模型可用于自动驾驶的下游运动规划,有助于大幅降低碰撞率。
其次,我们以零样本(Zero-shot)方式利用基础先验。 我们转向能够预测图像和视频像素级深度的大型重建模型。我们利用这些模型解决了两个欠定(Underconstrained)任务:(1) 在 2.5D 空间中跨越遮挡进行目标跟踪;(2) 基于稀疏视角进行动态场景重建。在两种场景下,我们均发现通过引入数据驱动的深度先验作为额外的场景线索,可以取得远超现有最先进技术(SOTA)的效果。
第三,我们通过微调(Finetuning)来挖掘基础先验。 我们专门研究了视频扩散模型(Video Diffusion Models),并将非全貌感知(Amodal Perception)和动态新视角合成(Dynamic Novel-view Synthesis)重新表述为视频模型所擅长的自监督任务,即图像补全(Inpainting)。我们发现,微调视频扩散模型在数据和计算量方面都惊人地轻量化。这表明基础模型中已经嵌入了类似于人类视觉感知的概念,只需对其进行“控制”即可执行其他任务。
综上所述,这些贡献突出了如何以可扩展(Scalable)的方式构建、利用和适配基础先验以实现时空感知——这种可扩展性是通过日益依赖互联网规模的 2D 数据,并精心设计自监督学习目标而实现的。