
ICML 2026 | FR3D:解耦自车运动的未来动态三维重建世界模型
自动驾驶和机器人真正需要的世界模型,不只是生成看起来逼真的未来视频,而是能预测未来场景的几何结构、相机轨迹和动态物体运动。二维视频生成模型已经能产生高保真画面,但它们通常把自车运动和环境运动混在图像平面里建模。时间一长,物体可能变形、消失,深度和运动视差也会失去物理一致性。 ICML 2026 论文《Future Dynamic 3D Reconstruction: A 3D World Model with Disentangled Ego-Motion》提出 FR3D,将世界模型从二维像素或图像特征推进到持久的三维潜空间。它面向一个新任务:给定单目历史图像,预测未来动态场景的 3D 重建和自车相机位姿。 FR3D 的关键是解耦。模型不把“相机自己在动”和“世界中物体在动”混成同一个图像变化,而是在统一 3D 坐标系中分别预测场景结构演化和自车轨迹,并把推断出的 ego-motion 当作隐式动作代理。这使它能够在 1 到 2 秒未来范围内保持更稳定的几何一致性。
1. 为什么需要三维世界模型
世界模型的核心能力,是根据历史观测和可能动作估计未来状态。近年来,生成式视频模型在画面质量上进展很快,但自动驾驶和机器人需要的不只是“像真的视频”。如果模型不知道场景的三维结构,就很难稳定地区分相机运动、物体运动、深度变化和遮挡关系。 二维视频世界模型的问题在于,它们通常只在图像平面中预测未来。自车向前行驶、车辆横穿道路、行人转弯、相机视角变化,都会表现为像素移动。若模型没有显式 3D 归纳偏置,就容易把这些不同原因混在一起,出现物体形变、突然消失、深度漂移和不合理运动。 FR3D 的出发点是:对物理世界的交互而言,几何一致性比像素级照片真实更重要。尤其在自动驾驶中,未来道路布局、车辆相对位置和自车轨迹才是规划与安全决策的基础。

2. 任务定义:未来动态三维重建
传统三维重建多是回看式任务:给定一段已经发生的视频或多视角图像,重建当前或过去的几何。传统世界模型则更多预测未来 RGB 帧、视频特征、占据栅格或传感器数据。FR3D 把两者连接起来:它要求模型在未来时间步生成统一三维场景重建,同时给出未来 ego-camera pose。 输入是一段单目图像上下文,输出是从下一时刻开始的未来三维场景状态和相机位姿。模型不能访问未来图像,只能根据上下文推断。与 2D 视频预测相比,这一任务更强调持久三维表示;与普通 3D 重建相比,它必须面向未来、处理动态物体,并在长时间滚动中保持几何连贯。 论文把这种任务命名为 future dynamic 3D reconstruction。它可以看作一种面向行动智能体的三维世界模型:场景不是一张张图,而是随时间演化的 3D 潜在世界。
3. 方法概览:在统一三维潜空间里预测未来
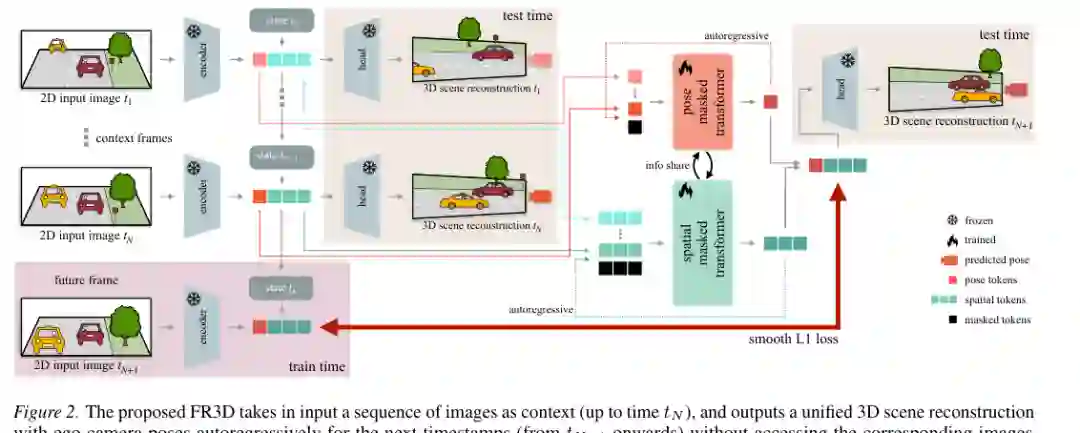
FR3D 的总体流程分为三个阶段。 第一,使用一个预训练前馈式 3D 重建模型作为编码器和解码器,将输入单目图像转成状态增强的 3D scene tokens。论文利用 CUT3R 这类离线三维重建模型的空间先验,把它当作教师和可解释的重建接口。 第二,模型在 latent token 空间中预测未来。它包含两个 masked transformer:一个预测空间 scene tokens,一个预测相机 pose tokens。二者并不是完全独立,而是通过双向 cross-attention 共享信息,使得未来几何结构和未来自车轨迹可以相互约束。 第三,预测出的 tokens 经过 frozen reconstruction head 解码为未来三维重建。训练时,模型看得到未来帧对应的教师 tokens,以 smooth L1 loss 做 token 蒸馏;推理时则自回归滚动,不再访问未来图像。
4. 解耦 ego-motion 与 world-motion
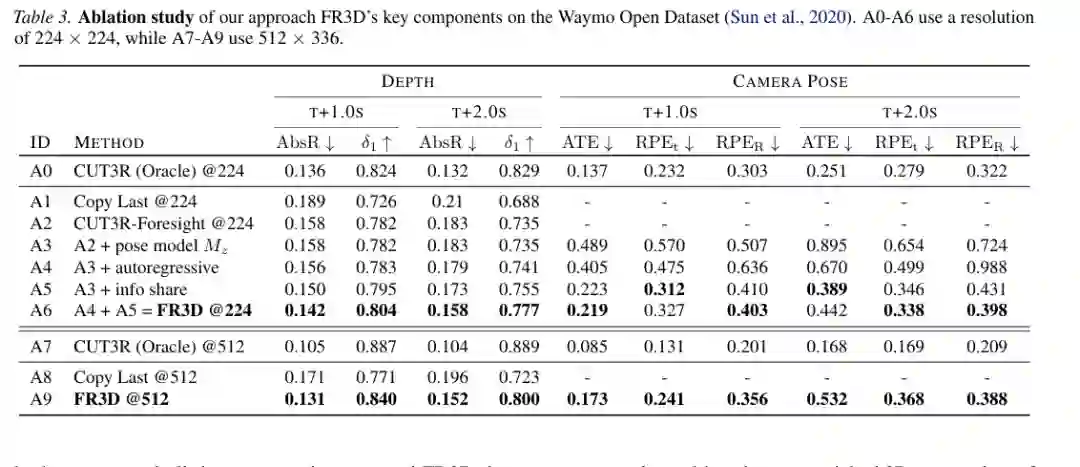
FR3D 最关键的建模选择,是显式区分相机运动和场景运动。在驾驶场景中,图像变化可以来自自车前进、转弯或刹车,也可以来自其他车辆、行人和动态物体。若这两类变化被同一个二维特征预测器混合处理,模型很难判断一个像素变化到底是相机造成的,还是物体自己造成的。 论文把自车运动作为隐式动作代理。虽然模型没有显式接收控制动作,但它从历史相机位姿与视觉上下文中推断未来 ego-motion,再让空间预测模块根据 pose tokens 条件化预测未来 scene tokens。这样,静态场景的表观变化可以由相机运动解释,动态物体的变化则由环境动态解释。 这不仅改善未来深度预测,也改善未来位姿估计。论文消融表明,单独加入 pose model、autoregressive training、spatial-pose information sharing 都有帮助,但组合起来才形成最终 FR3D,在 1 秒和 2 秒预测中同时提升深度和相机位姿。
5. 训练策略:用教师模型把空间常识蒸馏到未来
直接训练大规模 3D 世界模型成本很高。论文没有走大规模视频生成路线,而是采用 teacher-student distillation。教师是离线的三维重建模型,能够从当前帧和上下文中产生可靠 3D tokens。学生 FR3D 学习在只给历史上下文时预测未来 tokens。 这个设计有两个好处。首先,它把训练目标从像素生成转为潜空间预测,减少对照片真实感的追逐,聚焦几何结构。其次,它继承了现成 foundation reconstruction model 的空间常识,不需要像大视频模型那样依赖极端规模的数据和算力。 训练中还使用了自回归 token 预测。模型不仅预测下一步,也逐步处理越来越多由自己预测的 tokens,缩小训练和测试之间的分布差异。这对于长时间未来预测很关键,因为 2 秒以后任何小误差都可能在滚动中放大。
6. 实验设置与零样本泛化
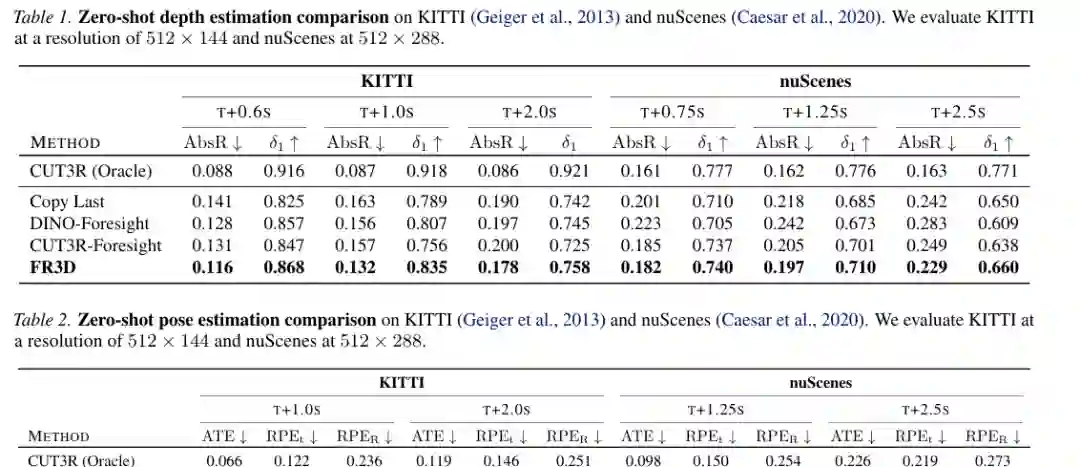
FR3D 在 Waymo Open Dataset 上训练,并在 KITTI、nuScenes 和 Waymo 上评估。论文特别强调 zero-shot:模型没有在 KITTI 和 nuScenes 上训练,却需要在这些不同域中预测未来深度和相机位姿。 对比基线包括 Copy Last、DINO-Foresight、CUT3R-Foresight,以及 CUT3R Oracle。CUT3R Oracle 可以访问完整上下文或未来信息,更像上界参考;Copy Last 是简单复用最后一帧;DINO-Foresight 和 CUT3R-Foresight 则代表基于特征预测或 3D tokens 预测的强基线。 零样本结果显示,FR3D 在 KITTI 和 nuScenes 的未来深度预测上普遍优于 Copy Last、DINO-Foresight 和 CUT3R-Foresight,在更长预测时距上优势更明显。姿态估计方面,FR3D 在 KITTI 和 nuScenes 上也明显优于只依赖 CUT3R-Foresight 的方案,说明联合预测 3D 场景和自车位姿确实带来互补信息。
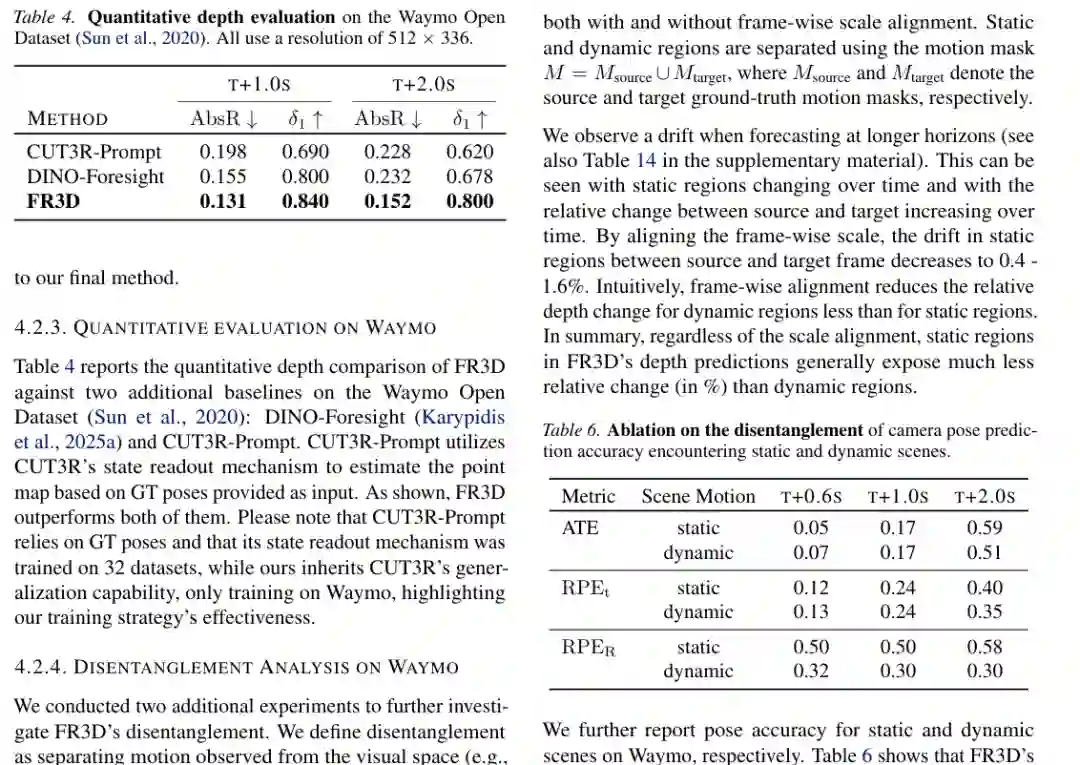
7. Waymo 结果:动态与静态区域都更稳定
在 Waymo 上,论文进一步比较 FR3D、DINO-Foresight 和 CUT3R-Prompt 的深度预测。FR3D 在 1 秒和 2 秒未来预测中均取得更低 AbsR 和更高 δ1,说明其几何预测更准确。 更重要的是解耦分析。作者把场景分成静态区域和动态区域,考察 frame-wise scale alignment 对相对深度变化的影响。结果显示,FR3D 在静态和动态区域都能减少相对深度变化,表明它不是简单复制当前帧,而是在固定相机设置下更好地区分了 ego-motion 和 world-motion。 姿态预测消融也支持这一点。在静态和动态场景中,FR3D 的姿态误差保持相对一致;到 2 秒时动态场景误差略有改善,说明动态物体并没有严重干扰自车位姿估计。
8. 定性结果:未来三维场景能保持连贯
论文给出了 nuScenes、KITTI 和 Waymo 上的定性预测。FR3D 能处理多个挑战场景:对向车流、转弯、自车轻微转向、骑行者转弯、车辆超车、卡车接近静止、前车跟随等。 与 oracle 重建相比,FR3D 预测的三维结构和相机轨迹在多个场景中保持较好一致。尤其在转弯场景中,模型能够预测平滑的自车轨迹,并让点云随轨迹合理展开,而不是简单把最后一帧复制到未来。 需要注意的是,FR3D 不直接预测 RGB。因此论文为了可视化,将预测点云与 RGB 帧结合展示。它的主要目标不是生成漂亮视频,而是让未来 3D 结构、深度和相机运动在几何上自洽。

9. 局限:横向运动和尺度漂移
论文也诚实讨论了局限。由于训练数据存在纵向驾驶运动偏置,FR3D 对横向运动仍较敏感。某些 Waymo 场景中,当动态物体出现横向运动时,模型会把横向和纵向运动混合,导致车辆预测轨迹不够准确。 另一个问题是 scale drift。FR3D 的深度预测会随 rollout 发生尺度漂移,因此作者称其是一个“up to scale”的持久 3D 世界模型。更丰富的数据、更强几何约束和显式尺度校准,有望进一步改善这一问题。

10. 为什么这篇论文值得关注
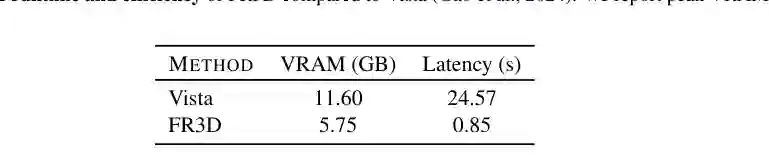
FR3D 的意义在于,它把世界模型讨论从“未来视频生成”推进到“未来三维状态预测”。对自动驾驶和机器人来说,这个转向很重要。真实交互需要的是可用于规划、碰撞判断和几何推理的未来世界,而不是只在视觉上连贯的像素序列。 它还提供了一种务实路线:不从零训练超大视频模型,而是利用已有 3D foundation reconstruction model 的空间先验,通过 latent distillation 学习未来演化。这让模型在较低训练成本下获得跨数据集零样本泛化能力。 效率结果也说明这一点。与 2D 驾驶视频世界模型 Vista 相比,FR3D 在推理显存和延迟上都更轻:论文报告 Vista 峰值显存 11.60GB、延迟 24.57 秒,而 FR3D 为 5.75GB、0.85 秒。虽然任务和输出形式不同,但这显示 latent 3D 预测路线具备较好的工程潜力。
11. 小结
FR3D 提出未来动态三维重建任务,并给出一个解耦自车运动的 3D 世界模型。它从单目历史图像中预测未来三维场景和 ego-camera pose,在统一 3D 潜空间中传播状态,使用教师-学生蒸馏继承现成三维重建模型的空间常识。 实验表明,FR3D 在 KITTI、nuScenes 和 Waymo 上具备较强零样本与长时距预测能力,尤其在 1 到 2 秒未来范围内比二维特征预测和简单 3D token 预测更稳定。它的不足也清楚:横向动态、尺度漂移和更复杂分布仍需进一步解决。 总体来看,这篇论文给 3D 世界模型提供了一个清晰方向:未来智能体不应只想象下一帧图像,而应维护一个可滚动、可解释、几何一致的未来三维世界。 论文地址:https://arxiv.org/abs/2606.18250

