
导读
视觉语言模型(VLM)近两年的后训练越来越强调“长链思考”:让模型在视觉问题上写出更长的推理过程,希望通过多步推导提升答案准确率。但这篇 ICML 2026 论文提出了一个很关键的反问:如果模型一开始就看错了图,再长的思考链真的有用吗?作者通过视觉数学任务分析发现,在 Qwen3-VL-8B 的错误回答中,86.9% 的根因来自视觉感知错误,而不是后续推理能力不足。也就是说,许多失败并不是“想错了”,而是“看错了”。 论文《From Seeing to Thinking》围绕这一观察,提出将 VLM 后训练从常见的“所有数据混在一起训练”,改为按能力拆分的分阶段训练:先训练视觉感知,再训练文本推理,最后训练视觉推理。这个顺序对应从 seeing 到 thinking 的能力链路:先确保模型能稳定识别图中的数量、位置、几何关系和细节,再让它学习纯文本推理,最后把两者结合到视觉推理任务中。 这项工作的价值不只是提出一个训练流程,而是给 VLM 后训练提供了更清晰的诊断框架。它说明后训练不应只追求更长的 reasoning trace,也不应默认把感知、推理、视觉问答数据混在一起就能得到最优模型。实验显示,分阶段训练不仅提升准确率,还能让模型用更短的推理链得到答案:在 Qwen3-VL-8B 上,相比混合训练,分阶段训练的视觉数学平均准确率更高,同时响应长度缩短 20.8%。这对追求高准确率、低推理成本和更可靠多模态推理的研究与应用都很有参考价值。
论文基本信息
英文标题 From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models 作者 Juncheng Wu, Hardy Chen, Haoqin Tu, Xianfeng Tang, Freda Shi, Hui Liu, Hanqing Lu, Cihang Xie, Yuyin Zhou 机构 Amazon, UC Santa Cruz, University of Waterloo, Vector Institute, Canada CIFAR AI Chair arXiv ID 2605.20177 类别 cs.CL, cs.CV 接收信息 Accepted to ICML 2026 项目主页 https://ucsc-vlaa.github.io/VLM-CapCurriculum/ 原文链接 http://arxiv.org/abs/2605.20177v1
摘要
本文研究视觉语言模型后训练中视觉感知与推理能力的关系。作者指出,近期 VLM 通常强调长链思考,但在许多视觉任务中,性能瓶颈主要来自视觉感知不足,而非推理本身。为此,论文将 VLM 后训练解耦为三个阶段:视觉感知、视觉推理和文本推理,并为不同阶段构建专门训练数据。实验表明,视觉感知需要目标明确的数据与训练目标;它是后续视觉推理的基础;并且使用可验证奖励的强化学习训练感知,比基于描述的监督微调更有效。跨多个 VLM 的结果显示,分阶段训练相比混合训练能同时提升视觉感知与视觉推理表现。进一步结合基于难度的课程学习后,模型性能还能继续提升。最终,作者在多个视觉数学和感知任务上取得强结果,并观察到模型推理轨迹平均缩短 20.8%,说明更强感知能够减少不必要的反复检查与长链推理。
引言:论文要解决什么问题
当前 VLM 后训练的主流思路,是把视觉问答、推理题、数学题、图表理解等数据混合起来进行统一优化,或者重点增强模型的长链推理能力。这一思路的隐含假设是:如果模型能更会推理,那么视觉任务上的答案也会更好。但论文认为,这个假设在很多视觉任务上并不成立,因为视觉推理的第一步不是“想”,而是“看”。 作者用 Figure 1 展示了一个典型几何题案例:当模型错误感知到线段和角之间的对应关系时,即便它在后续推理中多次回看图片、反复计算,也只是在错误前提上继续推导,最终无法得到正确答案。相反,如果模型一开始准确识别几何关系,后续推理会非常短,几步就能得到答案。这个例子说明,长链思考并不能自动纠正最初的视觉误读。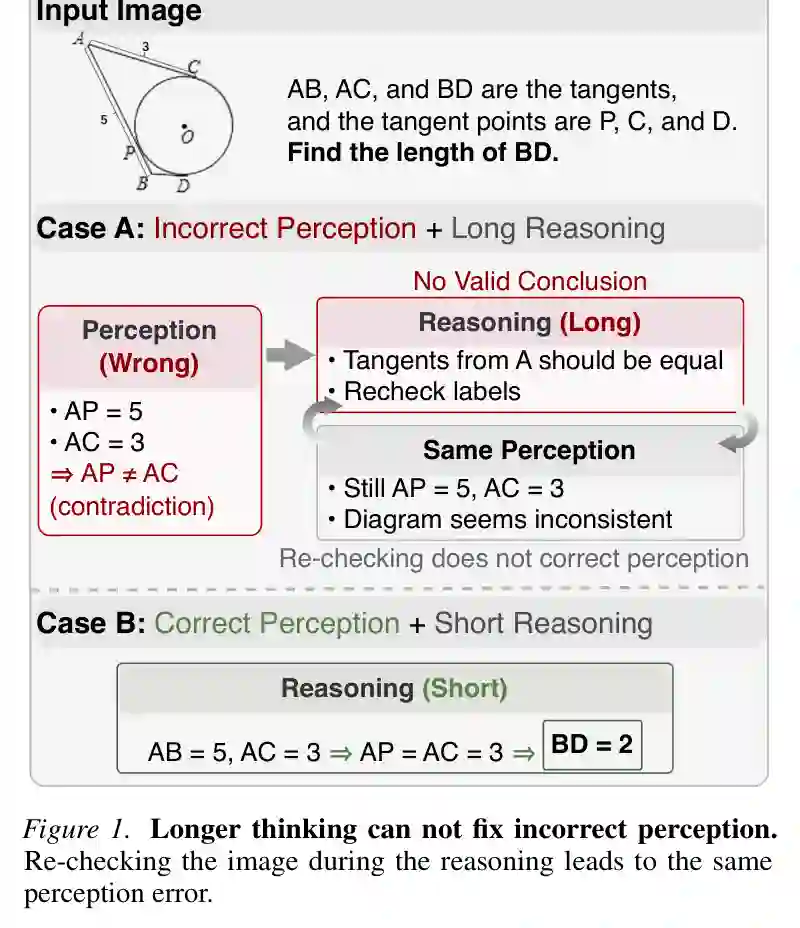
方法:核心思路与技术路线
论文的核心方法是 capability-based staged training,即基于能力的分阶段后训练。不同于把所有数据混合成一个训练集,作者把 VLM 后训练拆成三个能力阶段,并为每个阶段构造专门的数据与优化目标。三个阶段分别是视觉感知、文本推理和视觉推理,整体顺序为: 视觉感知 → 文本推理 → 视觉推理 这个设计体现了一个非常直接的逻辑:视觉推理依赖两个前提,一是模型能正确从图像中提取事实,二是模型具备把事实转化为结论的推理能力。因此,先训练视觉感知,再训练文本推理,最后训练视觉推理,比直接混合训练更符合任务因果结构。
视觉感知阶段
第一阶段的目标是让模型更准确地“看见”图像内容,包括数量、位置、空间关系、局部属性和几何结构等。作者没有简单使用传统图像描述数据进行监督微调,而是构造更适合感知训练的问答形式数据。 具体来说,作者从公开图像-描述数据出发,将图像 caption 转换成以视觉细节为核心的问题-答案对。例如,对一张几何图或复杂场景图,不是让模型泛泛描述图片,而是要求它回答“图中某个点位于哪条边上”“有几个对象满足某个条件”“两个对象之间是什么空间关系”等问题。这样的数据迫使模型关注图像中的可验证事实,而不是生成流畅但宽泛的描述。 为了避免模型只根据文字描述猜答案,作者进一步设计了感知难度过滤机制。对每个候选问题,分别让基础 VLM 基于“问题+图像”和“问题+caption”回答。如果只看 caption 就能答对,说明这个样本对视觉感知训练价值有限;作者保留的是 caption 可答对、图像回答出错的样本,因为它们能暴露基础 VLM 在真实视觉输入上的感知弱点。
文本推理阶段
第二阶段训练纯文本推理能力。该阶段不输入图像,而是让模型学习数学、逻辑、自然语言推理等文本任务。这样做的意义在于,把“如何推理”从“如何看图”中解耦出来,避免模型在视觉感知仍不稳时就被迫学习复杂视觉推理,从而把感知错误和推理错误混在一起。 从训练目标上看,论文采用 GRPO(Group Relative Policy Optimization)增强模型推理能力。对于每个输入,模型采样一组回答,通过准确率奖励与格式奖励构成复合 reward,再用组内相对优势进行策略优化。这样既能鼓励最终答案正确,也能约束模型输出符合训练格式。
视觉推理阶段
第三阶段将前两阶段能力整合到视觉推理任务中。此时模型已经具备更稳定的视觉感知基础和纯文本推理能力,再面对视觉数学、图表推理、几何问答等任务时,就能更可靠地把图像事实转化为推理结论。 这一阶段不是简单地“再训一遍视觉问答”,而是将视觉推理放在感知和文本推理之后进行。论文的关键判断是:视觉推理应当是后训练链条中的后置能力,而不是所有能力一起混合优化时自然涌现的副产品。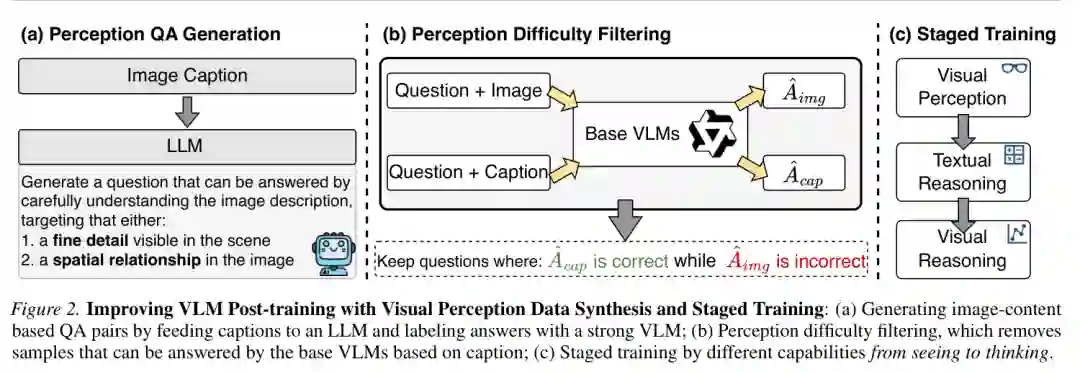
与混合训练的区别
混合训练把视觉感知、文本推理和视觉推理数据合并成一个数据集,用相同超参数统一训练。它的优点是简单,但缺点是不同能力之间的学习目标相互干扰:模型可能在视觉感知还没有学稳时,就被长链视觉推理任务牵引;也可能通过更长回答掩盖感知不准的问题。 分阶段训练的核心优势在于明确能力边界。它先把基础感知补齐,再训练推理,最后训练跨模态综合能力。论文的实验显示,这种顺序并不是形式上的 curriculum,而是真正影响最终准确率、感知能力和响应长度。
与难度课程学习的关系
作者还强调,基于能力的分阶段训练与传统基于难度的课程学习是正交的。能力分阶段回答的是“先训练哪类能力”,难度课程回答的是“每类任务从易到难如何排序”。实验显示,两者可以叠加使用:单独使用能力分阶段或难度分阶段都能提升性能,而组合后能得到更大增益。
实验:设置、指标与结果
实验设置
论文主要在 Qwen2.5-VL-7B 和 Qwen3-VL-8B 两个开源 VLM 基座上验证方法,并与多个代表性开源 VLM 比较,包括 GThinker、MMR1、OpenVLThinker、R1-OneVision-RL、WeThink、OneThinker 等。评测覆盖视觉数学与通用感知两大类能力。 视觉数学基准包括 MathVista、MathVision、MVerse (VI) 和 WeMath。感知基准包括 A-OKVQA、RealWorldQA、MMStar 和 POPE。论文报告单项准确率,也报告 Visual Math AVG、Perception AVG 和 Overall AVG。 训练方面,分阶段模型使用相同训练步数控制比较公平性。视觉感知、文本推理、视觉推理三个阶段分别训练,主实验中的训练步数为 90、375 和 465。混合训练基线则将所有阶段数据合并后统一训练,总训练步数保持一致。
与开源 VLM 的对比
主结果见图 3。对于 Qwen2.5-VL-7B,分阶段训练后的模型在视觉数学平均分上达到 42.26%,感知平均分达到 77.24%,总体平均分达到 59.75%。相比基础模型的总体平均 56.68%,分阶段训练带来明显提升;相比混合训练的 58.34%,分阶段训练也更优。 对于 Qwen3-VL-8B,分阶段训练的视觉数学平均分达到 51.10%,感知平均分达到 80.44%,总体平均分达到 65.77%。相比基础模型总体 62.19% 和混合训练 64.67%,分阶段训练继续取得最优结果。特别是在 WeMath 上,Qwen3-VL-8B 分阶段训练达到 56.10%,明显高于基础模型的 50.86% 和混合训练的 55.43%。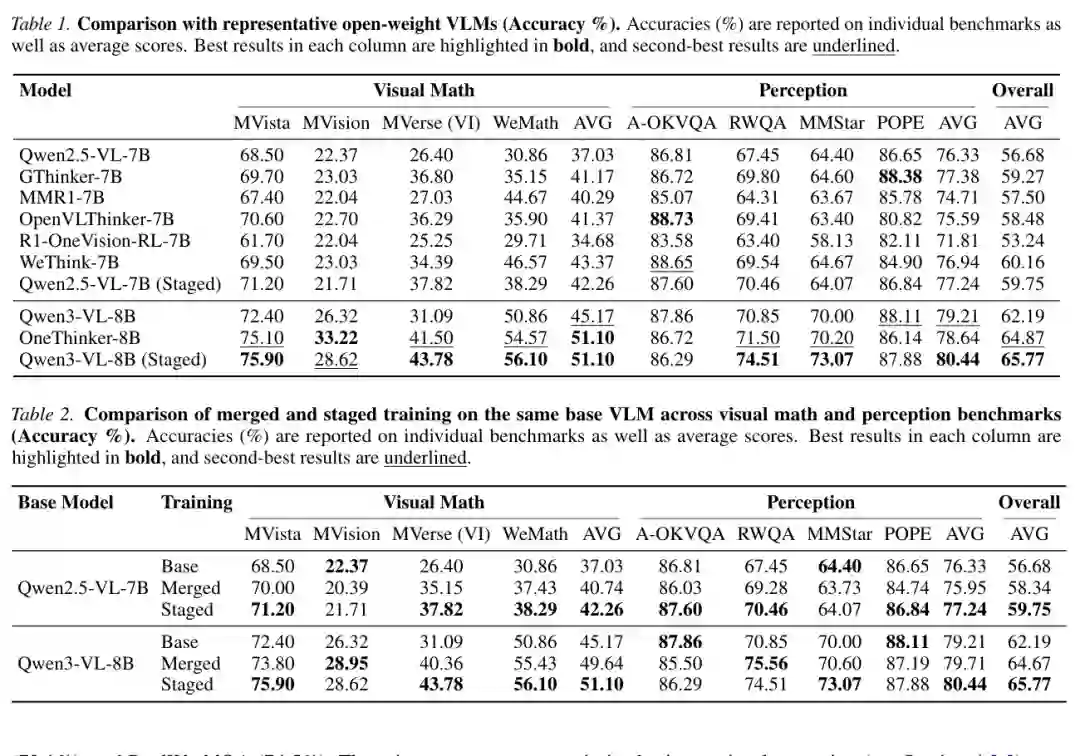
分阶段训练优于混合训练
论文特别比较了“相同数据、相同总步数”下的混合训练与分阶段训练。对于 Qwen2.5-VL-7B,混合训练将视觉数学平均分从 37.03% 提升到 40.74%,而分阶段训练进一步提升到 42.26%。对于 Qwen3-VL-8B,混合训练把视觉数学平均分从 45.17% 提升到 49.64%,分阶段训练则达到 51.10%。 更关键的是,分阶段训练在感知指标上也更好。Qwen3-VL-8B 的感知平均分从基础模型的 79.21% 提升到分阶段训练的 80.44%,高于混合训练的 79.71%。这说明分阶段训练并不是只让模型更会答视觉数学题,而是在基础视觉感知上也有改进。
推理更短:更准不是因为想得更久
图 4 展示了一个很有启发性的案例。混合训练模型错误地把长度为 73 的边和角度对应关系看错,之后不断重复检查图片,但始终基于同一错误感知继续推导。分阶段训练模型则在开头正确识别几何关系,因此后续推理非常短,直接得到正确答案。 论文还统计了训练过程中的平均响应长度。对于 Qwen3-VL-8B,分阶段训练在第三阶段出现明显分化:它平均只需 445 个 token,而混合训练需要 562 个 token,响应长度缩短 20.8%。与此同时,分阶段训练的视觉数学准确率更高。这表明性能提升不是来自“想得更久”,而是来自“看得更准”。
阶段顺序与训练方式分析
论文进一步分析了阶段顺序。结果表明,视觉感知作为基础能力非常关键。Stage 1→2→3(视觉感知→文本推理→视觉推理)和 Stage 2→1→3 都能取得较强结果,但如果反过来采用 Stage 3→2→1,让视觉推理先于感知优化,则视觉数学和感知指标都会明显退化。这支持了作者的核心判断:视觉推理应该建立在可靠感知之上。 在视觉感知阶段,作者比较了 SFT 与 RLVR。结果显示,RLVR 在两个基座模型上都更稳定:Qwen2.5-VL-7B 的感知平均分从 SFT 的 75.7% 提升到 RLVR 的 77.2%,Qwen3-VL-8B 从 79.2% 提升到 80.4%。这说明视觉感知训练更适合用可验证奖励直接优化,而不是让模型模仿自然语言描述。
与难度课程学习结合
论文还验证了能力分阶段与难度分阶段的可组合性。在 Qwen3-VL-8B 上,混合训练总体得分为 58.56%;单独使用能力分阶段达到 60.53%;单独使用难度分阶段达到 60.36%;二者结合后达到 62.99%。这说明能力课程和难度课程解决的是两个不同维度的问题,可以叠加获得更大收益。
结论:贡献、局限与启发
贡献
第一,论文明确指出 VLM 视觉推理中的主要瓶颈往往不是推理不足,而是视觉感知错误。86.9% 错误回答源自感知错误这一结果,为后训练研究提供了很强的诊断信号。 第二,论文提出基于能力的三阶段后训练框架,将视觉感知、文本推理和视觉推理解耦,并证明分阶段训练比混合训练更有效。这一结论在 Qwen2.5-VL-7B 和 Qwen3-VL-8B 上均成立。 第三,论文展示了“更准且更短”的推理行为。分阶段训练模型不是通过更长思考换取更高准确率,而是通过更可靠的感知减少反复检查,让推理链缩短 20.8%。 第四,论文证明视觉感知训练中 RLVR 优于基于描述的 SFT,并说明能力分阶段可以与难度课程学习结合,进一步提升性能。
局限性
论文的主要实验集中在 7B/8B 规模开源 VLM 上,对更大规模闭源模型或不同架构模型的适用性仍需要更多验证。虽然附录扩展到更多模型家族,但大规模模型是否同样受益、收益是否随规模变化,仍是开放问题。 此外,视觉感知数据的构建依赖图像 caption 到感知问答的自动生成与过滤流程。这个流程降低了人工标注成本,但数据质量仍受 LLM 生成质量、过滤策略和基础 VLM 能力影响。对于医学影像、遥感、科学图表等专业领域,可能需要重新设计更精细的感知问答生成方式。 最后,论文主要关注视觉数学和通用感知任务。对于开放式视觉对话、长视频理解、交互式智能体等更复杂场景,感知-推理解耦是否仍然足够,还需要后续研究。
启发
这篇论文给 VLM 后训练带来的最大启发,是不要把所有能力混在一起训练,也不要默认长链推理能解决视觉问题。对于多模态模型,可靠推理的第一步是可靠感知;如果模型没有看清楚,它写出的思考链越长,可能越像是在错误前提上自洽。 对于研究者,本文提供了一种新的课程学习维度:不是只按任务难度排序,而是按能力依赖关系排序。对于工程实践,本文也提示我们在构建多模态后训练数据时,应该单独保留并强化视觉感知数据,而不是只收集答案型视觉推理数据。更好的“看见”,可能比更长的“思考”更重要。
原文信息
原文链接:https://arxiv.org/abs/2605.20177v1 论文 PDF:https://arxiv.org/pdf/2605.20177v1 项目主页:https://ucsc-vlaa.github.io/VLM-CapCurriculum/