
ICML 2026|ECA:面向开放式图文生成的高效持续对齐
导读
视觉语言模型进入真实环境后,面对的数据分布不会保持不变。家庭机器人早期可能主要看到家具和家电,部署到街道后则更多遇到车辆和户外物体;一个视觉问答系统也可能从通用物体逐渐转向包含大量文字的商品、招牌和文档。模型必须不断学习新的视觉主题,同时保留旧主题上的图文理解能力。 这类问题属于开放式图像到文本生成的增量学习,包括图像描述和开放式视觉问答。过去的持续学习研究通常把任务划分为互不重叠的类别或场景,并通过保存旧图像、微调整个融合模块或语言模型来抵抗遗忘。然而,真实图像往往同时包含多个语义主题,只有主导内容随时间变化;保存原图还带来隐私和存储压力,大规模微调则成本高昂,并可能破坏预训练模型已有能力。
ICML 2026 论文《ECA: Efficient Continual Alignment for Open-Ended Image-to-Text Generation》提出一个更准确的研究视角:在冻结视觉编码器和语言模型的条件下,持续学习的关键是维护二者之间的跨模态对齐。作者据此提出 ECA,只持续调整中间对齐模块,并通过三种机制协调稳定性与可塑性:Mixture of Query(MoQ)按样本组合历史查询,Fisher Dynamic Expansion(FeDEx)只在参数冲突确实出现时扩展适配器,Dictionary Replay(DR)则用稀疏嵌入字典回放旧视觉语义,无需保存原始图像。 实验覆盖四个新构建的持续开放式图文生成基准。ECA 在全部基准上取得最佳最终平均性能,并以约 12M 至 22M 可训练参数逼近联合训练上界。它的价值不仅在于提升分数,更在于把“何时复用、何时扩容、如何无原图回放”组织成一套清晰且高效的持续对齐方法。
一、为什么需要持续对齐
典型预训练视觉语言模型可以分解为三部分:视觉编码器、跨模态对齐模块和大语言模型。视觉编码器把图像变成 patch 特征,对齐模块将视觉特征投射或查询成语言模型能够消费的表示,语言模型再根据图像信息和文本提示生成答案。 在 BLIP-2 中,对齐模块是 Q-Former;在 LLaVA 一类模型中,则由视觉投影器和语言模型的部分高层承担。对开放式生成而言,预测不是固定类别,而是一个文本序列。因此,当视觉数据分布发生变化时,最脆弱的不只是视觉分类边界,而是视觉证据与语言 token 之间的对应关系。 作者提出“持续对齐”概念:模型按顺序接收不同视觉主题的数据,在学习新分布的同时,持续保持高质量跨模态表示。这里有三个具体难点。
- 重复语义没有任务标识:旧主题会作为新图像的上下文再次出现,模型不能简单选择唯一任务提示,而要组合历史语义线索。
- 不能保存旧原图:系统需要在隐私与存储约束下维持旧对齐关系。
- 任务语义存在重叠:新旧任务的参数更新可能相互促进,也可能发生冲突,不能机械地为每个任务分配独立模块。

图中的差异很关键。传统设置可能删除包含多类对象的图像,以获得干净的互斥任务;ECA 的设置则保留真实语义重叠。例如,一张图片的主主题可以从“家电”转向“车辆”,但食物、家具或人物仍可能同时出现。模型既要识别当前主导分布,又要复用过去学习过的上下文语义。
二、问题定义与模型边界
第 (t) 个主题任务的数据包含图像 (X_t)、文本提示或问题 (P_t),以及目标句子 (S_t)。模型根据图像和文本输入,逐 token 生成预测句子。 作者以 BLIP-2 为主要实验载体,将视觉编码器和语言模型完全冻结,只更新 Q-Former 对齐模块及查询 token。这种设计有两点好处:一是能够隔离研究“对齐模块如何持续学习”,避免主干模型变化掩盖机制;二是训练参数和计算成本远低于全量微调。 但直接顺序微调 Q-Former 或一个并行适配器仍会遗忘。查询 token 会被当前任务覆盖,适配器容量可能不足;如果每个任务都新增适配器,又会阻断语义共享并导致参数线性增长;缺少旧数据还使模型无法检查新参数是否破坏过去的视觉语言映射。
三、ECA 整体框架
ECA 由三个相互配合的模块组成。
- MoQ负责输入侧的语义组合。它为每个任务学习查询 token 和键,并根据当前图像动态融合所有历史查询。
- FeDEx负责模型容量管理。它利用 Fisher 信息构造冲突度量,仅在新任务更新会损害旧任务时扩展并行适配器。
- DR负责旧知识回放。它把历史视觉 patch 的基本成分压缩进固定大小的嵌入字典,并通过蒸馏保持新旧对齐输出一致。
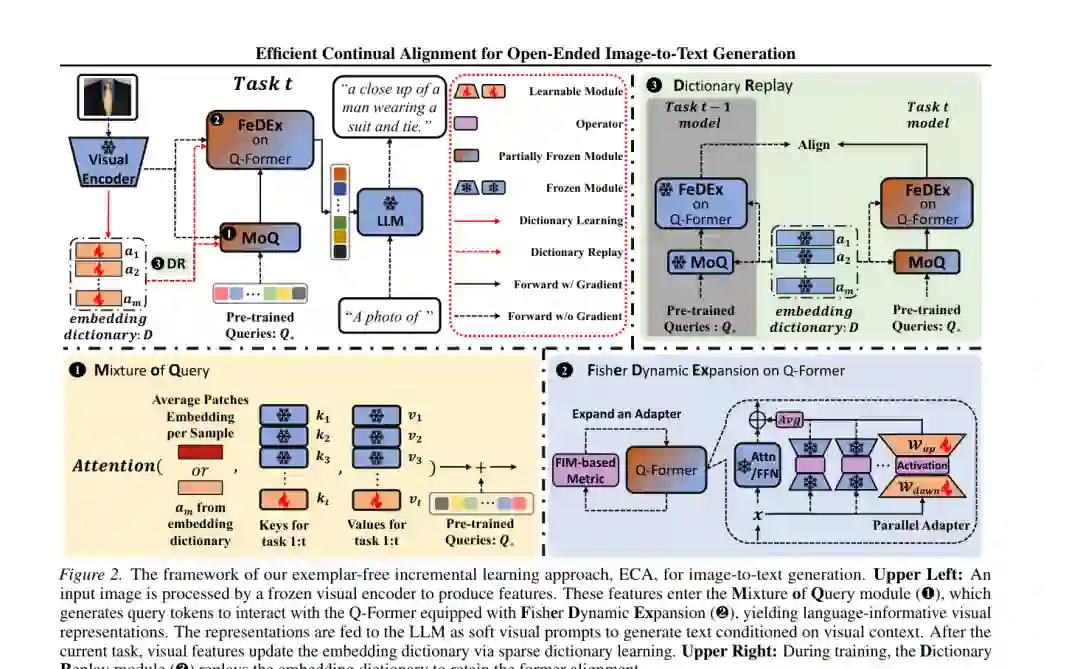
训练一个新任务时,图像先经过冻结视觉编码器。MoQ 根据平均 patch 表示生成组合查询,Q-Former 使用这些查询提取与语言生成相关的视觉信息。任务结束后,视觉特征用于更新稀疏字典;下一个任务训练时,字典原子同时输入旧模型和新模型,以蒸馏损失约束对齐表示。FeDEx 则在任务切换处判断是否需要增加容量。
四、Mixture of Query:按图像组合历史查询
BLIP-2 的预训练查询 (Q^*) 是通用视觉信息接口。如果只在当前任务上更新一组查询,旧主题线索会被覆盖;如果每个任务保留一组查询并根据任务 ID 选择,又不符合无任务标识的开放环境。 MoQ 为第 (t) 个任务学习一组任务查询 (v_t) 和任务键 (k_t)。推理时,模型取当前图像所有 patch 的平均表示作为注意力 query,以历史任务键组成 key,以各任务查询 token 组成 value,动态计算: Q_(t,i) = Q* + Attention(image_embedding, historical_keys, historical_queries) 因此,同一张图像可以同时激活多个历史主题的查询,而不是被硬路由到某个任务。预训练查询始终保留,持续学习查询作为增量补充。 为了降低任务间干扰,作者固定已经学到的键与查询,并对新键、新查询施加正交约束;同时使用键对齐损失,使任务键接近当前任务图像的平均表示。正交损失强调差异化,键对齐损失保证路由相关性,两者共同决定查询池的可组合性。 这一设计特别适合语义重叠场景:新图像即使主主题是车辆,也可以调用过去与人物、户外或配件相关的查询线索。消融实验显示,简单为每个任务增加查询但不进行跨任务组合,效果反而低于 Vanilla PA;MoQ 则改善平均性能和后向迁移。
五、FeDEx:只有发生冲突时才扩容
参数高效微调通常在 Q-Former 的注意力和前馈层加入并行适配器。单个适配器成本低,但容量有限;每个任务新增适配器虽然稳定,却忽略任务之间的正迁移,也让参数随任务数增长。 FeDEx 的目标是判断:在新任务上继续更新当前适配器,会不会显著损害旧任务? 作者从旧任务损失的二阶泰勒展开出发,用 Fisher 信息矩阵的对角项近似 Hessian,估计一次新任务梯度更新对旧任务损失的影响。每个参数的影响被分为正向损害项和负向改善项,再汇总成归一化冲突分数: S = positive_impact / (positive_impact + |negative_impact|) 当 (S \leq 0.5) 时,理论上新任务更新不会增加旧任务损失,可以继续复用当前适配器;当 (S > 0.5) 时,说明破坏性影响占主导,系统才扩展一个新的并行适配器,并冻结旧适配器。多个适配器的输出取平均作为最终结果。 这一阈值不是随意设置。论文证明,在小步更新和 Fisher 近似下,0.5 正好对应旧任务损失是否恶化的边界;附录扫描不同阈值也显示 0.5 获得最佳综合性能。过低阈值会频繁、无必要地扩容,反而削弱共享和效率。
六、Dictionary Replay:不保存原图的语义回放
持续学习常用旧样本回放,但保存图像会产生隐私、版权和存储问题。分类任务可以用每类一个原型代替原图;开放式图文生成的视觉嵌入却高度分散,一个类别原型无法描述复杂物体、文字和上下文组合。 DR 不存图像,也不存单个类别中心,而是学习一个过完备嵌入字典 (D)。每个视觉 patch 表示都由少量字典原子稀疏线性组合重建。作者使用带非负约束的 Lasso 求稀疏系数,并使用 FISTA 高效求解;随后在单位范数约束下更新字典原子。 字典保存的是跨图像可复用的基本视觉成分,而不是可直接还原的旧样本。训练新任务时,固定的旧模型与当前模型分别处理字典原子,DR 最小化二者输出表示的均方差,使当前 Q-Former 不偏离旧跨模态映射。 最终目标由三部分组成:当前任务文本生成交叉熵、MoQ 的正交与键对齐损失,以及带权重 (\lambda) 的字典回放蒸馏损失。任务结束后再用当前视觉特征更新字典。实验统一使用 7040 个字典原子,(\lambda=0.1)。
七、四个更现实的持续学习基准
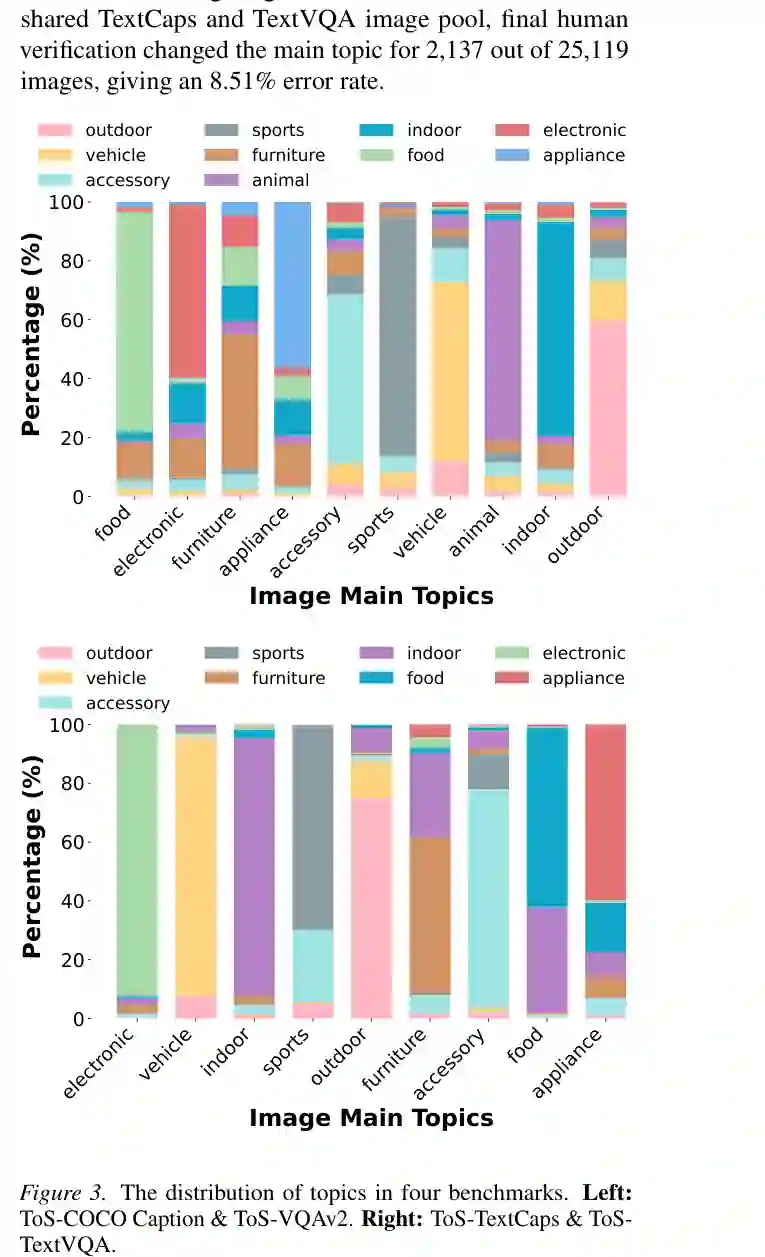
论文从 COCO Caption、VQAv2、TextCaps 和 TextVQA 构建四个 Topic of Semantic(ToS)基准。 对于 COCO 系列,作者根据实例标注中面积最大的显著物体确定主主题;最终形成动物、车辆、户外、体育、食物、家具、电子设备、家电、室内和配件 10 个任务。缺少实例标注的少量图像由 GPT-4o 给出初始主题,再由两名人工标注者复核。 TextCaps 和 TextVQA 采用类似流程,但动物主题样本太少,最终形成 9 个任务。GPT-4o 辅助标注经人工修正后的变化比例,在 COCO 共享图像池中为 11.48%,在 TextCaps/TextVQA 图像池中为 8.51%。这说明自动标注只用于初始建议,最终标签经过人工验证。
图像描述使用 BLEU-4、CIDEr 和 SPICE;视觉问答使用 VQA Accuracy。持续学习则报告三个维度:最终平均性能 Avg、学习后续任务对旧任务影响的 BWT,以及对尚未学习任务迁移能力的 FWT。BWT 越高代表遗忘越少,FWT 越高代表旧知识越有助于未来任务。 所有方法共享预训练 BLIP-2,冻结视觉编码器与 LLM。基线包括顺序训练并行适配器、顺序微调 Q-Former、LwF、EWC、Dual-Prompt、CODA-Prompt 和 MoE-LoRA,并以联合训练 PA/Q-Former 作为上界。
八、主实验:四个基准全部领先
8.1 COCO Caption 与 VQAv2
在 ToS-COCO Caption 上,ECA 的 BLEU-4、CIDEr、SPICE 平均性能分别为 43.42、125.56 和 23.80,三项均为持续学习方法最佳。相较 CODA-Prompt,ECA 分别弥合了 38.10%、50.18% 和 42.42% 的联合训练上界差距。 在 ToS-VQAv2 上,ECA 达到 68.05 VQA Accuracy,BWT 为 1.81,FWT 为 16.38。它比 CODA-Prompt 高 2.41,并且距离使用所有任务联合训练的 PA 上界 68.18 仅差 0.13。
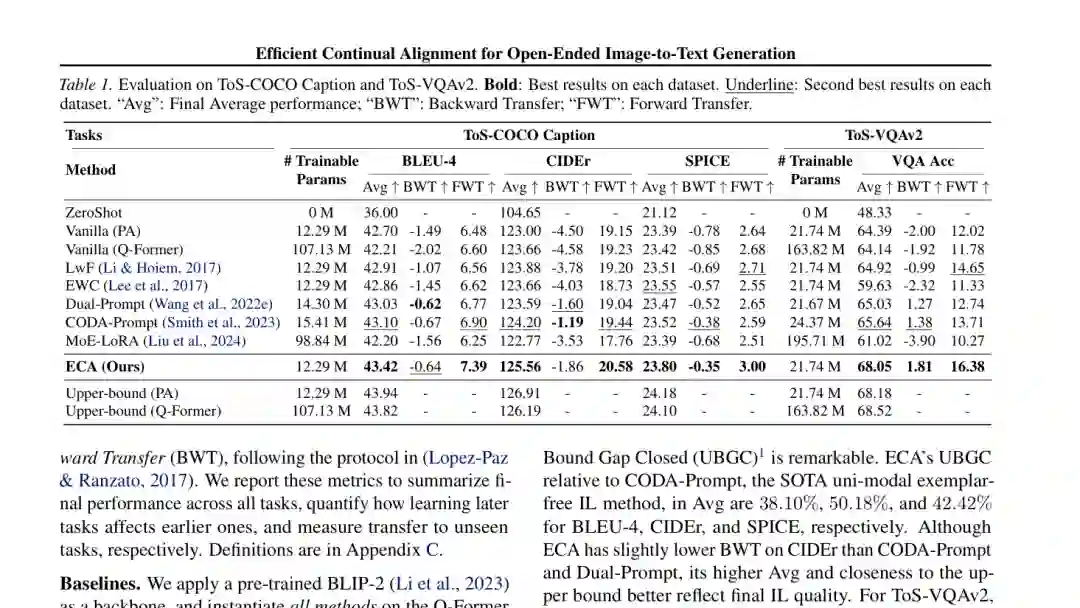
COCO Caption 是 BLIP-2 的预训练数据之一,因此绝对提升较小;但 ECA 能在高起点上进一步缩小与联合训练的距离,说明它并非依靠模型原本不会的内容制造增益。
8.2 TextCaps 与 TextVQA
这两个基准更困难:BLIP-2 没有在其上预训练,生成还依赖 OCR token 与视觉特征通过交叉注意力结合。 在 ToS-TextCaps 上,ECA 的 BLEU-4、CIDEr 和 SPICE 分别为 30.05、103.03 和 16.86。相较最佳单模态无样本回放基线 LwF,分别提高 2.16、5.57 和 0.67。 在 ToS-TextVQA 上,ECA 达到 38.13,比 LwF 的 32.92 提升 5.21;其 BWT 为 2.36,FWT 为 19.30,表明学习新主题不仅没有整体损害旧主题,还形成了正向迁移。
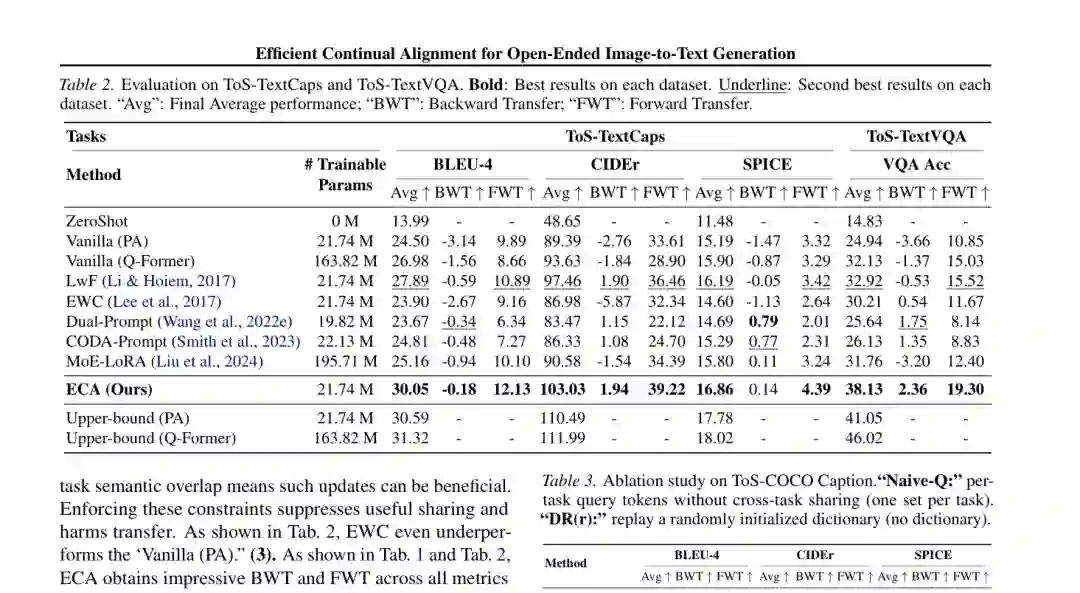
论文还解释了基线差异。LwF 在 OCR 基准上超过提示池方法,因为蒸馏能够直接保持新 token 与视觉特征的对齐;EWC 假设任务互斥,会限制对旧任务重要参数的更新,但在语义重叠场景中,一些更新本可带来共享收益,因此可能比普通适配器更差。
九、消融:三个模块各自解决什么问题
从单个并行适配器出发,加入 MoQ 后,CIDEr 的 BWT 从 -4.50 改善到 -3.66;再加入 DR,CIDEr Avg 提升到 124.57,FWT 提升到 20.45;MoQ 与 FeDEx 组合则把 CIDEr Avg 提升到 124.95、BWT 改善到 -2.04。三者全部结合后达到最高的 125.56、-1.86 和 20.58。
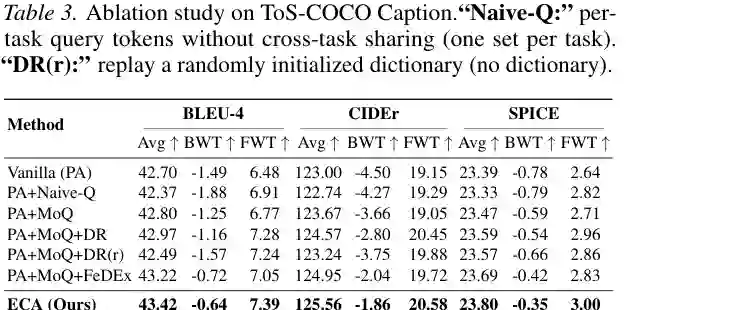
随机初始化字典的 DR 明显弱于稀疏学习字典,证明收益并非来自随意增加蒸馏输入,而是来自字典对历史视觉成分的有效压缩。MoQ 的损失消融进一步显示:正交损失主要改善 BWT,键对齐损失保证查询选择与当前图像相关;只使用后者会增加任务干扰,两者结合才得到稳定路由。
十、效率与通用性
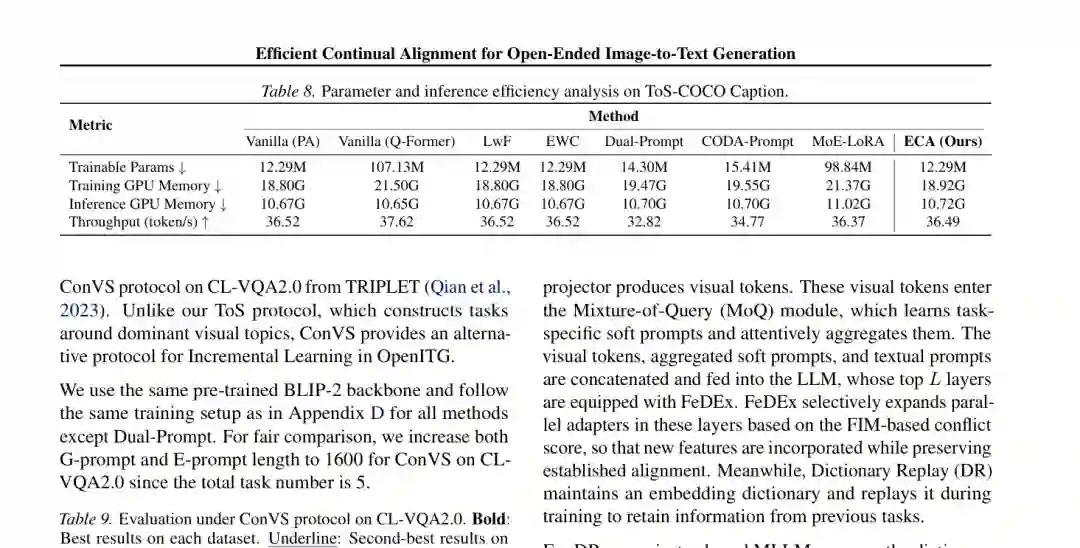
在 ToS-COCO Caption 上,ECA 仅训练 12.29M 参数,与 Vanilla PA、LwF、EWC 相同,远低于全量 Q-Former 的 107.13M 和 MoE-LoRA 的 98.84M。训练峰值显存为 18.92GB,推理显存为 10.72GB,吞吐为 36.49 token/s,基本保持单适配器基线的运行效率。
在另一种 ConVS 协议的 CL-VQA2.0 上,ECA 也达到 71.03,高于 MoE-LoRA 的 70.68 和 LwF 的 69.71,说明优势不只依赖作者提出的 ToS 划分。 作者还把 ECA 迁移到投影器架构 LLaVA-v0:把 LLM 顶部 6 层视作有效对齐模块,在其中加入 FeDEx;MoQ 生成软提示;DR 则使用字典原子生成教师伪描述,以 token 级 KL 散度蒸馏学生。在 ToS-TextCaps 和 ToS-TextVQA 上,ECA 仍获得最佳平均性能,证明框架不限于 Q-Former。
十一、案例分析
训练完全部任务后,作者重新测试最早学习的 ToS-VQAv2 主题。CODA-Prompt 在一些简单问题上已经失去可靠视觉对齐,例如错误判断画面中是否存在长椅、反射或人物;ECA 则能保留早期任务知识,给出更符合图像的回答。
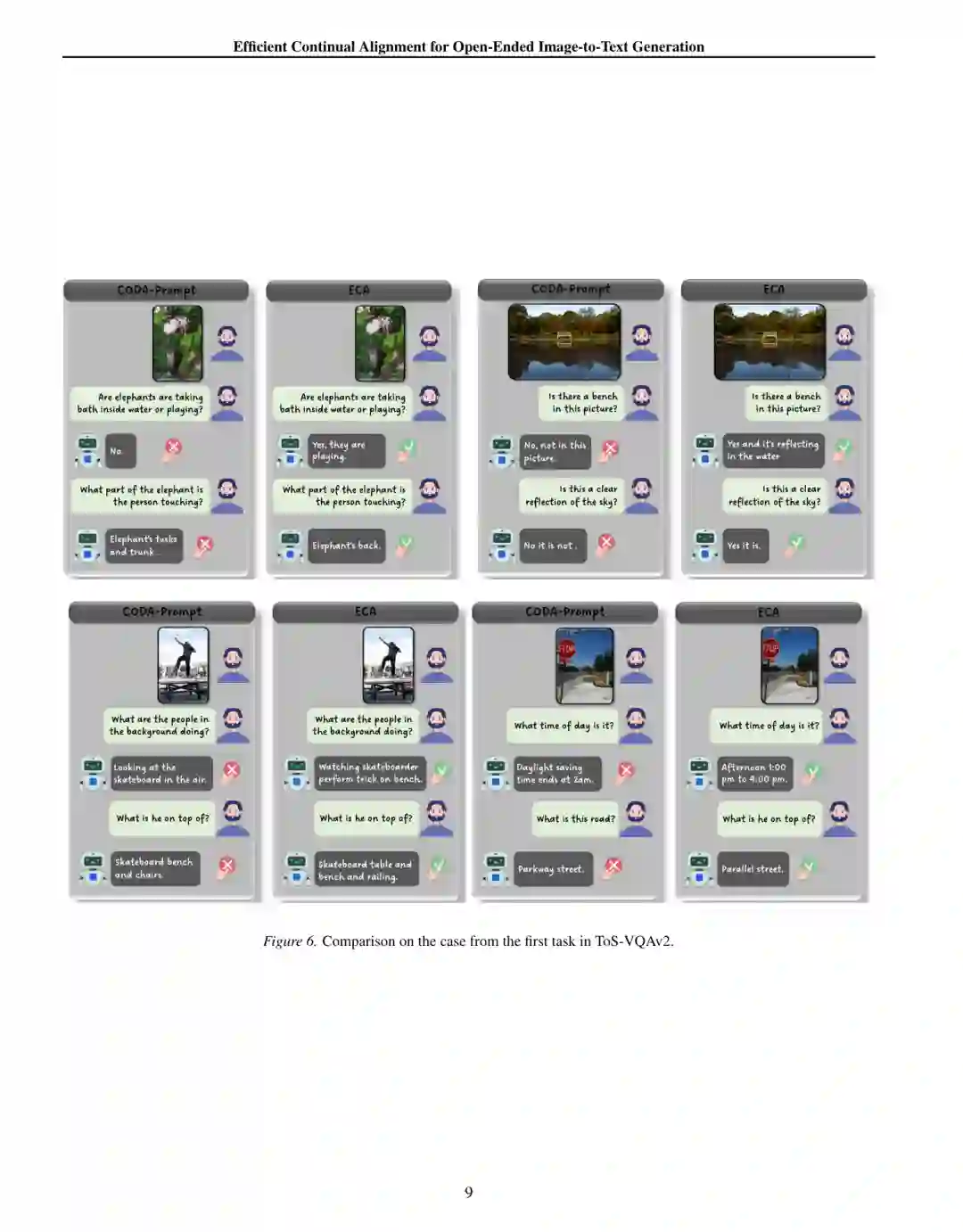
案例并不意味着 ECA 的自然语言答案始终完美,但它直观展示了持续对齐的目标:模型不是只在最后一个主题上表现良好,而是在经历完整视觉分布序列后,仍能正确调用早期学到的视觉语义。
十二、局限与启示
ECA 的主要限制来自固定大小字典。任务序列非常长、视觉分布极其多样时,7040 个原子可能不足以覆盖所有语义;频繁复用的原子也会被后续任务更新,从而覆盖早期表示。未来可采用动态扩展、重要性保护或分层字典。 方法还依赖较强预训练 VLM 提供高质量基础表示。若视觉编码器本身无法识别新领域内容,只调整对齐层可能不够。将预训练、视觉适应与持续对齐联合起来,是进一步方向。 此外,Fisher 冲突度量基于局部小步更新和对角近似,0.5 阈值在本文设置中有效,但面对更长任务序列、更大域迁移或生成目标变化,是否仍稳定需要验证。字典嵌入相较原图更有隐私优势,但也不等于形式化隐私保证,仍需研究反演风险。 从方法论上,ECA 给出三点值得推广的启示。
- 持续学习不一定更新整个模型,应先定位真正承受分布变化的接口。
- 参数扩展应由冲突证据触发,而非机械地按任务增长。
- 无样本回放可以保存可组合的特征基元,而不是保存原数据或单一类别原型。
十三、总结
ECA 将开放式图像到文本增量学习重新表述为持续跨模态对齐问题。它冻结昂贵的视觉和语言主干,只在对齐接口上进行高效适应;MoQ 处理无任务标识和语义重叠,FeDEx 平衡参数共享与冲突隔离,DR 则通过稀疏字典实现无原图知识回放。 四个新 ToS 基准比互斥类别划分更接近真实视觉流,实验也显示,ECA 能同时提升最终性能、减少遗忘并促进未来任务迁移。在多模态模型逐渐进入长期部署场景后,如何让视觉语言对齐随环境演化而持续更新,将成为比一次性微调更重要的问题。 论文地址:https://arxiv.org/abs/2606.12633
