
鉴于深度强化学习在训练智能体赢得《星际争霸》和《DOTA》等复杂游戏方面近期取得的成果,将基于学习的技术用于专业兵棋推演、战场模拟与建模的研究激增。实时战略游戏和模拟器已成为作战规划与军事研究的宝贵资源。然而,近期研究表明,此类基于学习的方法极易受到对抗性扰动的影响。本文研究了在一个由活跃对手控制的环境中,为指挥控制任务训练的智能体的鲁棒性。该指挥控制智能体使用最先进的强化学习算法——A3C和PPO,在定制的《星际争霸II》地图上进行训练。通过实验证明,使用这些算法训练的智能体极易受到对手注入的噪声影响,并研究了这些扰动对训练后智能体性能的影响。工作表明,迫切需要开发更鲁棒的训练算法,特别是针对战场等关键领域。
深度强化学习已成功用于在《星际争霸》和《DOTA》等多个战术和实时战略游戏中训练智能体,这些游戏涉及复杂的规划和决策。通过自我博弈、模仿学习等技术,这些智能体已展现出制定制胜策略的能力,其水平堪比经验丰富的人类玩家。因此,近年来军事研究界对将这些强化学习技术应用于作战规划和指挥控制等任务的兴趣日益浓厚。同时,传统游戏引擎已被重新用于促进自动化学习,并开发了新的用于战场模拟的引擎,从而形成了有效的数字化兵棋推演系统。这项研究背后的驱动力在于改进和增强未来战场使用的策略,未来的战场预计将更加复杂和非传统,可能超出人类指挥官的认知能力。
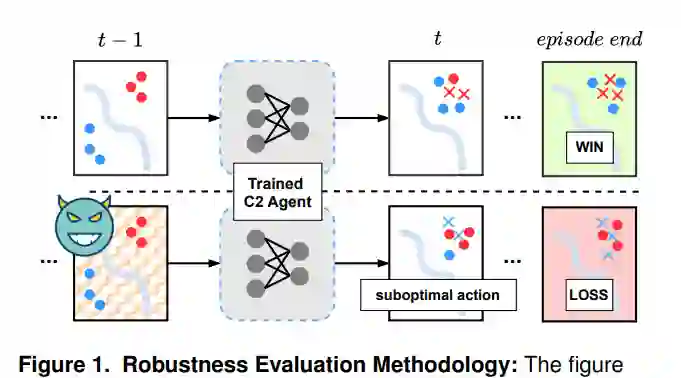
近期研究在使用通过强化学习技术和合成数据训练的指挥控制智能体来赢得模拟兵棋推演方面取得了相当大的成功。这部分归功于强化学习训练的可扩展性,这已被证明是探索和利用不同策略的巨大优势,即使面对困难或复杂的场景且仅获得关于环境的部分信息时也是如此。然而,这些评估是在良性环境中进行的,其中假定指挥控制智能体可获得的信息是未被破坏的。实际上,在战场环境中这不太可能,因为信息可能由于收集方式而具有固有噪声,或者可能被敌人篡改。在这项工作中,在指挥控制的背景下评估了此类训练有素的智能体在面临潜在对抗性输入时的鲁棒性。
为此,首先使用《星际争霸II》学习环境来模拟蓝军和红军两支队伍之间的冲突。指挥控制智能体指挥蓝军通过消灭红军部队来赢得战斗。
接下来,假设环境中存在一个攻击者,在战场收集的观测数据提供给指挥控制智能体之前对其进行篡改。所添加的扰动被称为对抗性扰动,其构建目的是高度难以察觉以逃避检测,同时最大限度地颠覆指挥控制智能体的策略,使其转向有害方向。然后,在多个指标上评估由此导致的智能体性能下降,并从军事角度分析行动过程的偏差。
主要贡献总结如下:
- 通过实验证明,训练后的指挥控制智能体即使在输入观测中受到很小的对抗性扰动也容易受到攻击。研究量化了一些预期趋势,并揭示了一些不明显的趋势。例如,研究表明,部分训练的智能体似乎比完全训练的智能体更能抵抗噪声。
- 为了普适性,评估了攻击在两种不同场景下的有效性,这两种场景分别对应指挥控制智能体的进攻和防御任务。
- 还评估了使用两种最先进强化学习算法训练的智能体,并评论了它们对注入噪声的鲁棒性。
- 通过分析攻击者扰动导致策略网络预测的动作分布变化,为模型的输出提供了可解释性。
评估证明了标准强化学习训练算法对对抗性扰动的敏感性,以及需要鲁棒的训练机制和先进的检测与防御技术,特别是对此类关键场景。结构如下。首先,简要介绍强化学习用于指挥控制的背景,随后在第2.1节描述《星际争霸》环境以及两个用于训练智能体的定制场景。在第4节,描述定制场景的状态和动作空间以及强化学习智能体的细节。第4.2节和第5节分别包含攻击方法和评估。最后,讨论了利用对抗性鲁棒训练技术的必要性以及未来工作的方向。
