
导读
这篇综述把大语言模型智能体在真实生产环境中的可靠性问题,从“模型能力是否足够强”推进到“执行器工程是否足够稳”。作者指出,许多长任务、多工具、多轮交互失败并不来自模型本身,而来自包裹模型的系统基础设施:执行环境、工具协议、上下文与记忆、生命周期编排、可观测性、验证评估以及治理安全。 论文的核心贡献是提出 ETCLOVG 七层分类法,并将 170+ 个开源项目映射到这一框架中,梳理 2022-2026 年从提示工程、上下文工程到执行器工程的演进。对于正在构建代码智能体、浏览器智能体、企业流程智能体或多智能体系统的团队,这篇综述提供了一套很适合做架构检查表的系统视角。
Abstract / 摘要
大语言模型(LLM)智能体在生产中的快速部署揭示了一个反复出现的模式:任务执行可靠性往往更多地依赖于底层基础设施层(即智能体执行执行器,agent execution harness),而非模型本身。本综述对智能体执行工程(agent harness engineering)进行了基于实践的系统性处理,围绕三个核心论点展开。首先,智能体执行器是一个独立的系统层,其工程质量在很大程度上决定了真实世界的可靠性,我们通过从提示工程到上下文工程再到执行工程的三阶段演进、涵盖成本-质量-速度三元悖论、能力-控制权衡以及执行器耦合问题的跨层综合,以及基于研究空白和生产痛点的开放问题议程来发展这一立场。其次,我们提出了ETCLOVG七层分类法(执行环境、工具接口、上下文管理、生命周期/编排、可观测性、验证、治理),该分类法通过将可观测性和治理视为独立架构关注点,扩展了先前的六组件框架。第三,我们将170多个开源项目映射到该分类法上,以揭示生态系统模式、覆盖空白和新兴设计原则,同时提炼自OpenAI、Anthropic和LangChain生产部署的工程原则,弥合了实践者知识与研究词汇之间的鸿沟。 图1:提示工程、上下文工程和执行工程的简要比较。
1 Introduction / 引言
1.1 瓶颈约束:执行器胜于模型
学术界对基于大语言模型的智能体的研究,在很大程度上是对模型本身的研究。研究议程集中于模型能做什么:能否跨多步规划、能否可靠地调用工具、能否检索和压缩相关记忆、或能否与其他智能体协调。其隐含假设是,智能体能力主要取决于模型能力,即一个足够强大的模型加上一个足够好的提示,将产生足够可靠的行为。 然而,近期的实证证据挑战了“更好的模型即能产生更可靠的智能体”这一假设。三项近期成果确立了这一模式。Bölük(2026a)仅修改了编辑工具格式和工具执行系统,未改动模型,便在跨15个模型的编码基准测试中报告了高达10倍的增益。Trivedy(2026)仅通过系统提示重组、中间件上下文注入和自我验证钩子,将固定的GPT-5.2-Codex智能体在Terminal-Bench 2.0上的性能从52.8%提升至66.5%,即13.7个百分点的增益,完全通过基础设施变更实现。Meta-Harness(Lee等,2026)通过自动化执行优化在Terminal-Bench-2上达到76.4%,超越了所有手工工程方法,且未修改模型权重。在每种情况下,变量都是执行执行器,即管理上下文构建、工具交互、编排、反馈和执行约束的基础设施层;模型则是固定的。这些仅通过执行器获得的增益均超过了同一基准测试上报告为有意义模型进步的典型2到4个百分点改进。这一模式并非偶然:是执行器,而非模型,在驱动结果。 我们将这一模式称为瓶颈约束论点:对于跨可比前沿模型评估的长时域任务,基准测试方差可能由执行器本身驱动,其程度与模型相当。
1.2 实践者-研究鸿沟
实践者的紧迫性与研究词汇之间存在张力。OpenAI明确将“执行器工程”定义为围绕Codex智能体设计环境、约束、文档和反馈循环的学科,报告称一个小团队在五个月内产生了约一百万行内部产品代码,而无需手动编写生产代码。Anthropic的智能体工程文章从相邻方向得出了相同原则:有效的智能体应使用简单且可检查的架构;工具接口应为智能体使用而设计,而非从面向人类的API复制;上下文应逐步披露而非急切加载;长期运行的工作需要持久交接工件和可恢复的执行基础设施。Martin Fowler网站的一篇文章将执行器工程描述为“AI智能体的控制论治理器”,由前馈指导和反馈传感器组成,围绕大语言模型形成控制循环。 与此同时,研究社区一直在以日益精确的方式研究智能体系统的组件:记忆、工具使用、规划和安全。但尚未系统研究的是将这些组件整合为可靠运行的系统。结果形成了一个实践者-研究鸿沟:实践者知道执行器基础设施很重要,但缺乏正式词汇来描述其原因,从而无法实现系统改进。本综述试图弥合这一鸿沟。
1.3 范围与贡献
本综述聚焦于封装语言模型以管理长时间、多步骤任务执行的基础设施层。我们不综述作为开发工具的智能体框架、作为产品类别的智能体平台,或模型能力本身,尽管三者都为我们分析提供信息。图4总结了构建本综述其余部分的七层分类法。 我们的贡献围绕三个论点组织:
- 概念贡献:基于瓶颈约束论点,我们认为执行器,而非模型本身,是真实世界智能体可靠性的瓶颈约束。三项近期结果表明,仅通过执行器即可在编码基准测试上获得高达10倍的增益、在Terminal-Bench 2.0上获得+13.7个百分点的增益,以及在Terminal-Bench-2上达到76.4%,每一项都超过了同一基准测试上典型的模型驱动增益。我们通过三阶段工程演进、涵盖成本-质量-速度三元悖论、能力-控制权衡和执行器耦合问题的跨层综合,以及开放问题议程来发展这一论点。
- 分类贡献:七层ETCLOVG分类法将可观测性和治理视为一等层,而非生命周期钩子的副产品。每层都有其生产工具栈(可观测性侧为Langfuse和OpenTelemetry;治理侧为权限引擎、网关和审计管道),并在生产部署中由不同团队负责。我们还将状态管理置于生命周期和编排内部,状态与其读写的执行流相邻。
- 实证贡献:将148个以上开源项目映射到ETCLOVG,显示了生态系统的密集区、稀疏区以及先前语料中遗漏的类别。该映射是迄今为止最大的开源智能体执行器语料库。执行、工具、生命周期和验证层覆盖密集;可观测性和治理层覆盖较薄且更多存在于商业平台;而此前语料中缺失的三个类别——任务运行器、多智能体编排器和规格驱动开发工具——现在已成为一等类别。
图1:提示工程、上下文工程与执行器工程的关系对比。论文强调,大语言模型智能体可靠性正在从单次输入优化转向系统级执行基础设施优化。
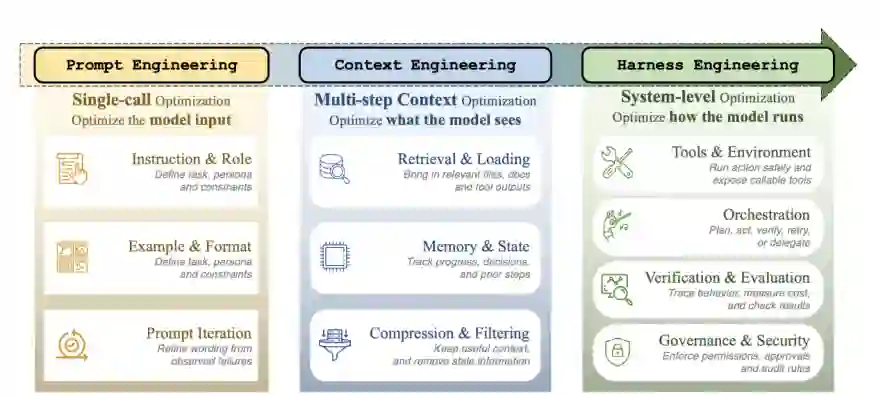 图1:提示工程、上下文工程与执行器工程的关系对比。论文强调,大语言模型智能体可靠性正在从单次输入优化转向系统级执行基础设施优化。
图1:提示工程、上下文工程与执行器工程的关系对比。论文强调,大语言模型智能体可靠性正在从单次输入优化转向系统级执行基础设施优化。2 Background and Taxonomy / 背景与分类法
2.1 智能体系统的演进
从早期链式思维提示到自主智能体的轨迹,可以理解为实践者必须管理的工程表面逐步扩展的过程。 ReAct时代(2022-2023)。Yao等人(2023)将“观察-思考-行动”循环确立为基础原语。早期系统以最小基础设施运行:一个while循环、一个提示模板和一个小型工具调度表。AutoGPT和BabyAGI通过用任务队列、记忆和工具调度封装语言模型调用,展示了完全自主操作的雄心,同时也使执行失控、上下文爆炸、状态丢失和未监控副作用等失效模式作为基础设施问题(而非仅提示问题)显现出来。 工具集成与多智能体协调(2023-2024)。Gorilla、ToolLLM和Toolformer确立了工具使用能力可以被学习或诱导,而非硬编码到固定API包装器中。CAMEL、ChatDev、MetaGPT和Mixture-of-Agents引入了多智能体协调模式,涵盖角色扮演对话、软件开发组织以及分层智能体聚合。评估基础设施随着SWE-bench、AgentBench、WebArena和GAIA而成熟,同时协议标准化随着Anthropic的MCP和Google的A2A而开始。 执行器转向(2025-2026)。到2025年,积累的部署经验足以清晰表明,智能体可靠性的瓶颈约束是基础设施质量而非模型质量。2026年初的三项独立发展验证了这一转变:OpenAI明确采用“执行器工程”作为学科;斯坦福/MIT的Meta-Harness显示自动化执行器优化超越手工工程;LangChain的DeepAgents通过仅执行器层变更,在Terminal-Bench 2.0上从52.8%提升至66.5%,对应13.7个百分点的增益和约26%的相对改进。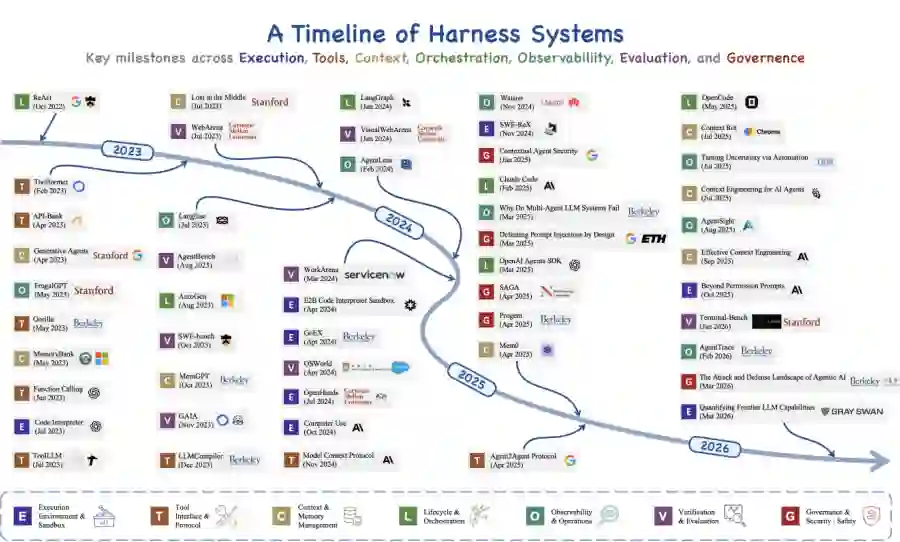
2.2 三个工程阶段
2022-2026年期间揭示了一个连贯的三阶段演进,反映了该领域所选择工程对象的变迁。 提示工程(2022-2024)。主要杠杆是输入提示文本。实践者通过编写更好的指令、少样本示例和推理模板进行优化。工程范围狭窄:优化单个模型调用的单个文本输入。 上下文工程(2025)。随着智能体运行时间变长,瓶颈约束从“输入是什么?”转变为“模型在每一步应看到什么信息?”这一阶段聚焦于上下文管理:每轮注入什么、如何检索和压缩记忆、如何按相关性排序工具结果,以及如何处理上下文窗口饱和。范围从单一输入扩展到管理流入上下文窗口的多个信息流。 执行器工程(2026)。随着模型变得足够强大以处理长时间运行的任务,可靠性越来越依赖于维护状态、中介工具、注入反馈、强制执行约束和验证进度的基础设施包装器。这一观察与瓶颈约束观点一致,即长时域智能体性能是由耦合的模型-执行器系统而非模型单独产生的。因此,执行器工程询问必须围绕模型设计什么治理、约束、反馈循环和执行控制,才能使智能体系统可靠。 每个阶段都包含前一阶段:执行器工程包括上下文工程,后者又包括提示工程。这三个阶段在时间和概念上也有重叠,而非以清晰边界相继更替。提示工程至今仍是执行器实践中的活跃部分,而上下文工程也在与执行器层级关注点并行发展。 图2:基于大语言模型的智能体系统的执行器工程分类示意图。四个层次E、T、C和L构成了系统的结构支柱。O层提供系统级监控,而V层提供跨组件的评估和反馈。G层在整个系统上实施治理和安全约束。颜色方案对应于§2.3中开发的ETCLOVG层次。
2.3 七层分类法
我们提出了一个用于智能体执行器工程的七层分类法,简称ETCLOVG,代表执行、工具、上下文、生命周期、可观测性、验证、治理。图4给出了紧凑的可视化映射;本小节固定了整个综述中所用解释。 前四层描述执行器的结构核心。执行(E) 决定智能体代码在何处运行以及何种沙箱约束限制它;工具(T) 规定外部能力如何被描述、发现和调用;上下文(C) 控制模型在短期、会话级和持久性视野中能看到什么;生命周期(L) 组织读取和写入该状态的控制流,从单智能体循环到多智能体以及从问题到拉取请求的工作流程。其余三层描述围绕该核心的控制平面。可观测性(O) 捕获轨迹、成本、故障和可靠性信号;验证(V) 将任务和轨迹转化为评估、失败归因和回归反馈;治理(G) 通过权限、身份、策略、强化、审计和人工监督机制约束行为。 两个设计选择使该分类法与众不同。首先,我们将可观测性(O) 提升为独立层,而非视为生命周期钩子的副产品。在生产系统中,可观测性拥有专用工具生态系统(Langfuse、Arize Phoenix、OpenLLMetry)和独特工程实践(OpenTelemetry仪表化、成本归因、异常检测),值得独立处理。其次,我们引入治理(G) 作为一等层,捕获跨三个子层的安全与合规关注点的全谱:模型层(护栏、内容过滤器)、系统层(网关、代理、权限模型)和组织层(审计、合规、人在环监督)。 状态管理自然地属于生命周期和编排(L)内,与其读写的执行流相邻;生命周期钩子和策略执行属于治理(G)内,与其他约束机制对齐。 图3:2022年至2026年代表性智能体执行器系统的时间线。该时间线展示了从早期单循环智能体到更丰富的执行器基础设施的转变,涵盖执行环境、工具接口、上下文和内存管理、生命周期编排、可观测性、验证和治理。颜色方案对应于§2.3中开发的ETCLOVG层次。 图4:智能体执行器工程分类的详细说明。每个分支对应一个ETCLOVG层及其主要子类别;代表性系统和论文将在后续章节讨论。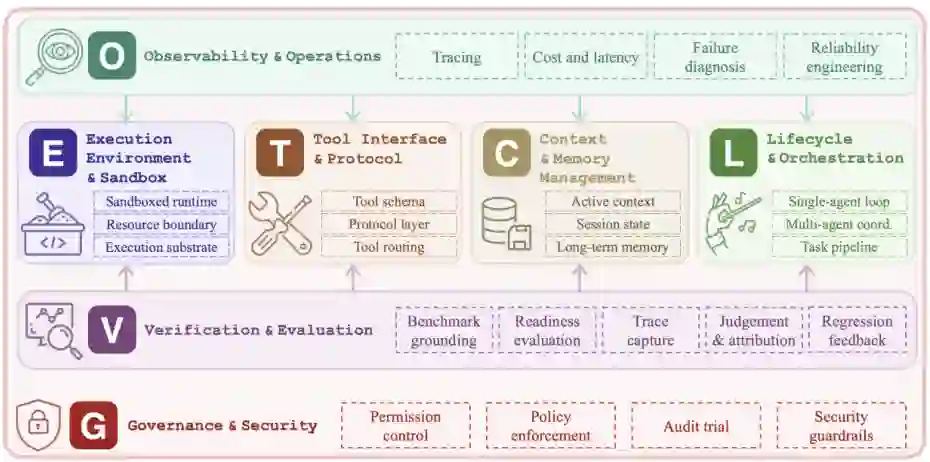
2.4 范围
我们在比“任何围绕大语言模型的软件”更窄的意义上使用智能体执行器(agent harness):执行器是将模型调用转化为有边界、有状态、由工具中介的任务执行的人工工程化包装器,通过执行基质、工具接口、上下文控制、编排、可观测性、评估反馈和治理约束实现。因此,分析单位是使长时间运行智能体行为可控、可检查、可恢复的基础设施,而非基础模型或提示本身。我们按功能而非产品类别划定边界:当智能体框架暴露如状态化编排、工具路由、运行时策略钩子或轨迹捕获等可复用机制时,它属于范围内;而一个薄模型API包装器、提示库、静态数据集、通用容器运行时、向量数据库、APM仪表板或内容过滤器则属于范围外,除非其被明确适配于智能体执行、状态、评估或工具使用治理。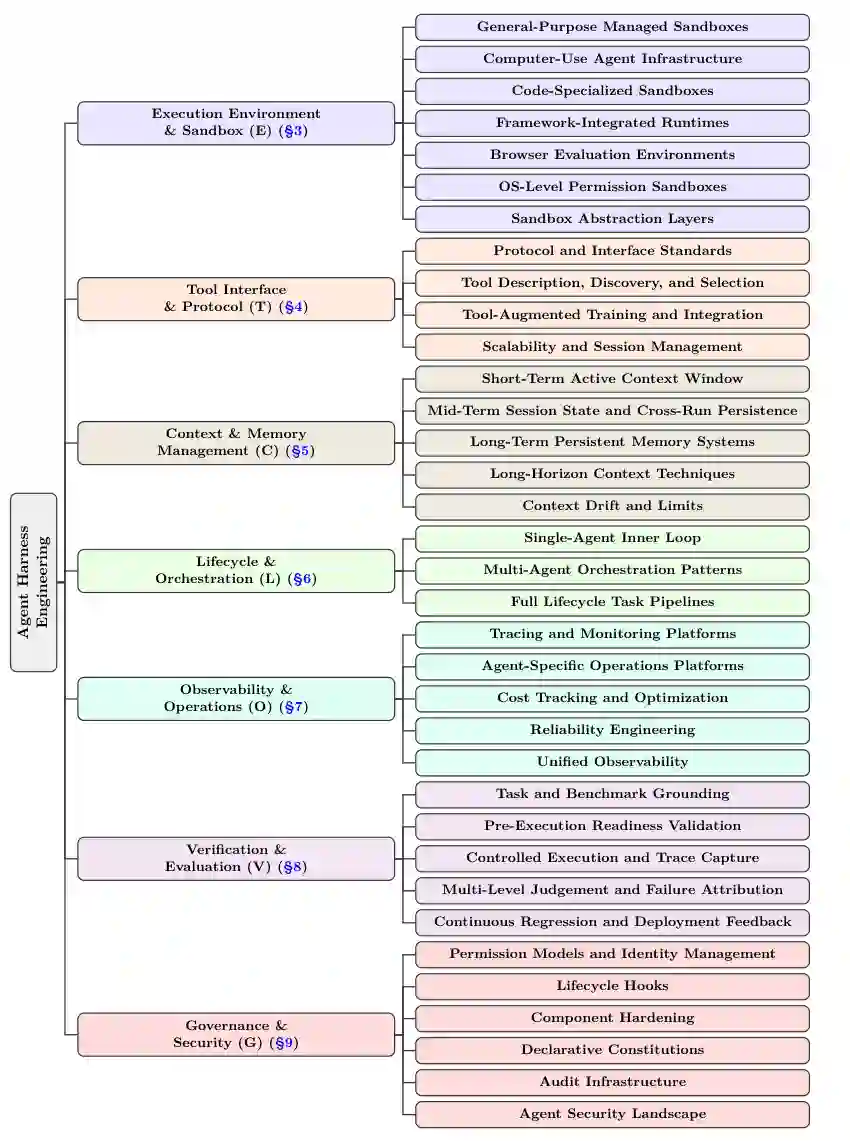
2.5 项目收集程序
我们构建了语料库作为公开文档化智能体执行器工件的系统映射,使用系统综述的报告规范使源流、搜索策略和选择过程明确。候选项目从四个流收集:先前综述和基准论文;对名称、描述、README文本、主题、星标、更新时间和归档状态的可复现GitHub搜索;精选项目列表和包注册表;以及公司工程博客或发布说明中引入执行器级机制的内容。代表性查询组合了诸如“agent harness”、“coding agent”、“LLM agent sandbox”、“MCP server”、“agent observability”、“agent memory”、“agent evaluation”和“agent governance”等术语。对于每个保留的候选项目,我们记录了项目名称、URL、工件类型、源类型、可用状态、可识别的发布年份、可用的GitHub元数据,以及用于后续ETCLOVG编码的公开证据;本版本中报告的元数据快照冻结于2026年5月8日。
2.6 纳入与排除标准
当一个项目满足三个条件时被纳入:它是公开文档化的;它实现或指定了一个具体的执行器级机制;可用证据足以分配至少一个ETCLOVG层。这包括具有可复用编排或工具路由逻辑的智能体框架;实例化可执行智能体环境的基准测试;为智能体执行打包的沙箱;以及操作于智能体状态、轨迹、动作或策略之上的记忆、可观测性、评估或治理系统。我们排除了简单的聊天演示、提示包、薄模型客户端包装器、没有智能体运行时的静态数据集或排行榜、非面向智能体的通用基础设施组件,以及无法从公开文档检查技术行为的产品页面。边界案例按机制而非标签解决:一个被命名为“智能体”的仓库不足以纳入,而一个评估或沙箱项目在提供可复用执行器机制时被纳入。
2.7 编码协议
每个保留项目使用公开工件本身作为证据,针对七个ETCLOVG层进行编码:自述文件、文档页面、论文、示例、发布说明,以及必要时还包括仓库结构。编码是多标签的,因为许多系统跨越多个层;主层标记工件最中心的机制,而次要层仅当文档暴露独立能力(而非偶然依赖)时才分配。当前快照使用单主编码员协议并经过作者审计,而非正式的多编码员一致性研究,因此我们不报告Cohen's kappa或类似的可比注释者间统计量。歧义案例在全部集合编码后重新审阅,采用保守规则:如果公开证据未明确显示面向智能体的机制,则保留层分配。
2.8 语料库的局限性
语料库应被视为可见智能体执行器生态系统地图,而非所有已部署智能体基础设施的普查。它偏向于英语源、GitHub可见项目、开源工件以及维护者发布足够实现细节以供外部编码的系统。商业生产系统代表性不足,除非其工程博客、文档或SDK暴露了相关机制;编码智能体基础设施被过度代表,因为它拥有异常丰富的公开痕迹:仓库、基准测试、沙箱、从问题到拉取请求的工作流程和发布说明。层分配也反映了公开文档而非私有架构,因此某层缺失意味着“未公开证实”而非“未实现”。
2.9 聚合分析
170多个项目的映射揭示了一个广泛但不均衡的生态系统。执行、工具接口、生命周期编排和验证拥有最密集的可见覆盖,因为编码、网页、终端和计算机使用智能体都需要可运行环境、工具契约、控制循环和可复现评估才能有用。上下文和记忆出现在许多项目中,但通常嵌入在更大的框架内部,而非作为独立执行器组件发布。可观测性和治理在开源覆盖中较薄,更常通过商业平台、SDK功能或工程文章出现,表明运营控制比运行时和基准基础设施成熟得晚。跨层项目日益常见:最完整的系统结合了沙箱、工具协议、编排、追踪、评估和权限控制,这支持了核心论点,即执行器工程是一个集成系统问题,而非孤立附加组件集合。
3 Execution Environment and Sandbox / 执行环境与沙箱
3.1 范围与概念
定义。智能体的执行环境是指智能体动作物理执行的基础设施层。在大语言模型智能体语境下,执行环境和沙箱是紧密耦合的概念。因此,生产级智能体系统几乎总是在沙箱化环境中执行动作。 为什么沙箱在智能体时代至关重要。智能体时代的沙箱不仅仅是继承自传统多租户代码执行的安全措施。它同时服务于三个不同目的,三者结合将沙箱从操作细节提升为智能体执行器设计中的一等关注点。 第一个目的是安全。智能体沙箱面临超越传统多租户代码执行的挑战。大语言模型生成的代码在大规模下既不可审计也不可预测,排除了静态审查作为主要防线。智能体在多个步骤上自主执行,因此动作执行时无法进行人工干预。提示注入攻击可以将原本良性的智能体重新用作沙箱定向攻击的向量,模糊了可信用户意图和恶意输入之间的界限。近期关于沙箱逃逸的实证工作表明这些担忧并非假设性,我们将在§3.3中给出定量证据。 第二个目的是可复现性。长时域智能体任务及其测量它们的评估执行器需要能够将执行状态重置到已知基线。Docker容器或微型虚拟机可以按需销毁和重建,而开发者的工作站则不能,这一特性使得基于沙箱的评估标准如SWE-bench和OSWorld成为可能。在训练时,当单个任务可能在并行轨迹中被重复数百次时,缺乏廉价重置机制本身就是可扩展性瓶颈。 第三个目的是活性(liveness),这是最特定于智能体时代的目的。没有沙箱,智能体希望执行的每个可能有风险的动作,例如文件写入、包安装或出站网络调用,都必须通过显式权限提示向人工门控。在大规模下,这会产生两种失效模式:用户因挫败而放弃智能体,或者他们反射性地批准一切并破坏提示的安全理由。沙箱打破了这一僵局,定义了一个有边界的区域,在该区域内智能体被授权自由行动,将权限从逐动作问题转变为话配置问题。Anthropic报告称,向Claude Code引入沙箱后,权限提示减少了84%,同时保持了安全性。这三种目的中,安全与传统沙箱共享,可复现性在智能体设置中被放大,而活性本质上是新的。它们的结合证明了将智能体沙箱视为独立研究对象的合理性。
3.2 智能体沙箱的类别
智能体沙箱基础设施在2024-2026年从一小套通用运行时多样化到几个不同的产品类别,每个针对不同的任务类型优化。我们沿工作负载和用例轴将景观组织为七个类别,这在我们看来对在执行器设计者中选择系统最为有用。隔离技术的正交轴在每一小节内作为设计属性讨论,而非作为顶层类别,因为相同的隔离原语被跨不同工作负载复用。七个类别是:通用型托管沙箱、计算机使用智能体基础设施、代码专用沙箱、框架集成运行时、浏览器评估环境、操作系统级权限沙箱和沙箱抽象层。 图6:按沙箱类别组织的大语言模型智能体执行环境和沙箱的代表性工作。 通用型托管沙箱提供商业或开源沙箱即服务平台,通过API接口暴露任意OCI容器镜像,支持shell、文件系统、网络和解释器。代表性系统包括Daytona、E2B、Modal、Northflank、OpenSandbox和Docker Sandboxes。 计算机使用智能体基础设施代表一种不同的执行模型,其中智能体通过模拟鼠标、键盘和屏幕观察与图形界面交互,而非通过API或shell命令。代表性系统包括Anthropic的Computer Use、CUA和OSWorld提供的基于虚拟机的环境。 代码专用沙箱是为代码生成、评估和数据分析优化的轻量级环境。代表性系统包括Judge0、OpenAI Code Interpreter、sandboxed.sh和langchain-sandbox。 框架集成运行时是打包在更广泛智能体框架内部的执行环境,而非作为独立沙箱产品暴露。代表性系统包括OpenHands运行时、agent-infra沙箱和smolagents的执行器层。 浏览器评估环境同时扮演沙箱和评估执行器的双重角色。代表性系统包括WebArena、VisualWebArena、BrowserGym和WorkArena。 操作系统级权限沙箱使用操作系统原语实现细粒度文件和网络隔离。代表性系统包括Anthropic的sandbox-runtime、Claude Code的沙箱功能以及IsolateGPT。 沙箱抽象层不是沙箱本身,而是统一多个沙箱后端为单一API的接口。代表性系统包括SWE-ReX、smolagents的执行器接口和Kubernetes Agent Sandbox项目。 综合。跨七个类别,可见三个交叉趋势。首先,该领域正沿着隔离强度而非收敛程度分化:托管沙箱正从共享内核容器向专用内核微型虚拟机迁移,而操作系统级权限沙箱则完全摒弃独立环境,转而收窄主机视图。普通Docker容器的中间地带正被两端挤压。其次,评估稳健性正成为一等关注点:沙箱逃逸基准测试和生产中的代码解释器智能体安全基准测试表明,当前部署的沙箱配置可被前沿模型部分绕过。第三,该领域正在分离基础设施级隔离和语义或能力级隔离。
3.3 威胁模型与沙箱逃逸
智能体执行沙箱面临传统容器级威胁和智能体特有的威胁类别。首先,提示注入攻击允许外部输入劫持智能体行为并发起恶意沙箱操作。其次,目标错位可能导致智能体自身将沙箱逃逸作为工具性子目标主动尝试。第三,组合放大发生在具有多个工具访问的智能体允许单个沙箱弱点级联跨集成能力时。 关于智能体设置中沙箱逃逸的实证证据有限但令人担忧。SandboxEscapeBench评估前沿大语言模型在嵌套沙箱夺旗挑战中,报告对基于Docker的容器有15%至35%的逃逸成功率,具体取决于容器配置。防御研究仍处于早期阶段。IsolateGPT提出了基于大语言模型的智能体系统的执行隔离架构。事务性沙箱方法提供基于回滚的保护。这些结果暴露了攻防进展之间的差距。
3.4 部署模式
智能体沙箱基础设施已从最初的自主托管Docker模式多样化为三种共存模式。在自主托管模式中,开发者直接管理沙箱基础设施。在云(SaaS) 模式中,沙箱即服务提供商处理基础设施。在混合或自带云模式中,智能体逻辑和沙箱执行解耦跨环境。在观察到的实践中,自主托管沙箱在交互式开发和单租户场景中占主导地位,而云沙箱在多租户和大规模部署中更常见。混合模式正专门为合规或数据驻留需求与大池临时执行能力并存的场景而出现。
3.5 总结
执行环境是智能体执行器的物理基质:它们提供安全边界、用于可复现评估和训练的重置机制,以及长时域智能体无需每步人工批准即可行动的有界区域。七个类别表明设计空间现在较少受单一隔离原语决定,而更多受工作负载保真度、威胁模型和运营模式影响。
4 Tool Interface and Protocol Layer / 工具接口与协议层
工具接口和协议层(T)定义了智能体如何发现能力、表示可调用的接口以及在异构运行时边界上执行动作。在实践中,该层位于两个竞争目标之间的分界线上:通过暴露更多工具增加能力覆盖,与通过保持动作空间和提示占用小来保持决策质量。生产级智能体系统的最新工程指南反复报告,过大的工具菜单会降低可靠性、增加令牌开销并放大规划错误。 我们将该层组织为四个互补方向:协议和接口标准;工具描述、发现和选择;工具增强模型训练与集成;以及可扩展性和会话管理。 图7:按工具层类别组织的大语言模型智能体工具接口和协议的代表性工作。
4.1 协议与接口标准
MCP已成为编码和企业智能体最可见的工具集成基质,具有显式的主机-客户端-服务器架构和基于JSON-RPC的类型化工具、资源和提示交换。MCP的实际价值不仅在于模式级互操作性,还在于生态系统流动性:智能体构建者可以复用不断扩展的服务器目录,而无需为每次部署实现自定义连接器。 A2A针对一个不同但相邻的边界。它不是向一个智能体进程暴露工具,而是标准化了不透明智能体应用之间的通信,包括通过Agent Cards进行发现、支持同步和流式交互,以及长时间运行的任务协作。更有效的组织原则,在我们看来,是按集成边界对工具/接口标准进行分类。在此视角下,出现了四个边界:模型↔函数、智能体↔外部能力、智能体↔智能体、智能体↔仓库/环境。表1总结了这一视图,并阐明了为什么几个广泛比较的标准占据非重叠角色。 函数调用模式和API描述标准仍然是该层的基础构建块。OpenAI风格的函数调用通过JSON模式和显式调用/返回回合将工具调用操作化;OpenAPI提供了语言无关的机器可读API契约。此外,仓库级指令文件如AGENTS.md和AGENT.md提供了直接在版本控制中编码工具使用和工作流约束的轻量级替代方案。
4.2 工具描述、发现与选择
一旦协议定义了如何进行调用,下一个瓶颈是应表面和选择哪些工具。越来越多的工作研究工具文档质量、检索和动态候选剪枝。EASYTOOL分析了从大型库存中选择合适工具的挑战。AnyTool和CRAFT专注于通过自动构建或细化工具使用管道来减少手动说明负担。MetaTool基准测试风格评估显示工具检索和调用质量在领域和查询形式上可能有显著差异。近期工作如MCP-Zero、ToolRet和ToolRegistry强调检索感知编排和注册表质量作为下游智能体成功的一阶决定因素。一个紧密相关的方向将工具选择扩展到可复用技能,其中智能体必须识别相关的程序模块而不仅仅是紧凑的API模式。系统级结果强化了两个设计原则:首先,“更少但更好的工具”通常优于暴力工具暴露;其次,发现管道必须具有适应性。
4.3 工具增强训练与集成
第三个方向从运行时编排转向模型能力获取。Toolformer展示了在生成过程中何时以及如何插入API调用的自监督增强。Gorilla和ToolLLM/ToolBench用更大的工具语料库、指令调优管道和面向执行的API使用监督扩展了这一路线。在生产执行器中,这些模型端进步通常与框架级运行时堆栈配对,如LangChain、Semantic Kernel和smolagents。编码智能体设置还暴露了第二类更语义化的工具:静态分析器、类型检查器、求解器支持的验证器、证明助手,以及补丁等价性或故障定位检查器。Ugare & Chandra将这一空间框架为智能体代码推理。
4.4 可扩展性与会话管理
随着工具集合和调用频率增长,可扩展性和状态管理成为该层的操作瓶颈。ReAct在每一步顺序调用单个工具,限制了并行性但保持了简单性。LLMCompiler引入了依赖感知的并行调度。在会话管理方面,E2B沙箱为长时间运行的代码解释器会话提供持久性。Anthropic的MCP代码执行子协议支持长时间运行的交互式shell会话。BFCL、StableToolBench和API-Bank从评估角度解决了工具调用质量和规模问题。
5 Context and Memory Management / 上下文与记忆管理
5.1 为什么必须工程化上下文
上下文管理之所以成为执行器工程的核心问题,有三个结构性原因。首先,上下文窗口是根本上限——模型可以在任何单步中“看到”的信息量受到其架构上下文窗口这一硬上限的限制。其次,上下文窗口内的信息质量本身决定智能体行为。第三,长时域任务产生超出简单汇总或截断的上下文工程需求。这些因素共同使上下文管理从被动文本包含转变为执行器工程中的主动控制设计领域。
5.2 从提示工程到上下文工程
提示工程和上下文工程之间的区别不在于是否在运行时修改模型输入,而在于动态性和来源。提示工程师手动构造一个静态输入字符串。上下文工程师设计一个在执行器控制下的实时管道,为每一步动态组合信息。这一转变反映了从“模型能否回答此问题?”到“智能体在长时间运行中能否跟踪足够的状态以完成任务?”的根本性演变。
5.3 短期:管理主动上下文窗口
短期上下文管理处理单个执行步骤内模型可见的动态信息。关键机制包括:窗口策略,如滑动窗口和基于令牌的预算;结构化组织,如同质化、分块和检索增强生成;以及动态压缩,如上下文优先化、选择性信息丢弃和分层抽象。
5.4 中期:会话状态与跨运行持久性
中期上下文管理涉及跨多个执行步骤(但限于单次会话)的状态维护。与短期上下文不同,中期状态需要在步骤之间保持一致性,例如累积的工具调用历史、环境变量、对话状态以及部分完成的任务工件。实践中的关键机制包括:会话级键值存储(如LangChain的RunnableWithMessageHistory)、结构化会话元数据(会话ID、时间戳、角色映射),以及基于文件或数据库的会话快照。这些机制确保智能体在多次工具调用或模型生成之间能够恢复上下文,而无需重新加载全部历史。然而,会话状态管理的挑战在于状态膨胀:随着会话长度增加,维护完整的历史可能导致上下文窗口溢出,因此需要结合压缩或摘要策略。
5.5 长期:持久记忆系统
长期记忆系统使智能体能够在跨越不同会话、任务甚至重启的时间范围内持久化信息。这与中期状态不同:长期记忆关注的是知识而非即时上下文,例如用户偏好、领域知识、学习到的技能以及跨会话的长期事实。实现方式包括外部向量数据库(如Pinecone、Weaviate、Chroma)用于语义检索,关系数据库用于结构化知识,以及专门化的记忆管理器(如MemGPT/Letta)。长期记忆系统的设计关键包括:记忆的编码(如何将交互转换为可存储的向量或事实)、检索策略(相似度阈值、重排序、多样性与时效性权衡),以及遗忘机制(处理过时信息、概念漂移和存储预算)。当前长期记忆系统面临的核心问题是:记忆检索的准确性随存储规模增长而下降,且如何避免检索到的无关信息污染上下文导致性能下降仍是一个开放问题。
5.6 长时域技术:保持智能体在100+轮次中的连贯性
当智能体需要在超过100轮交互的长时域任务中保持连贯性时,基本的上下文管理策略往往失效。长时域技术旨在防止上下文漂移、任务分叉和状态遗忘。代表性方法包括:循环式摘要(Recursive Summarization),定期对历史进行摘要并替换原始保真信息;反思与重述(Reflection & Recapitulation),让智能体在关键步骤回顾其当前任务状态和已完成动作;基于规划的分解(Plan-based Decomposition),将长任务拆分为子任务并为每个子任务维护独立的上下文;以及分层记忆架构(Hierarchical Memory),将近期细节存于主动窗口,中期摘要存于慢速层,长期事实存于持久存储。当前前沿系统(如Google的Veo代理、Anthropic的Claude Code长时间任务)已整合部分技术,但仍报告在数百轮后出现主题漂移、工具调用循环和遗忘目标的问题。
5.7 上下文漂移与当前方法的局限
尽管上述技术有所进展,上下文漂移——即智能体随着轮次增加逐渐偏离原始任务目标或丢失关键信息——仍是根本性限制。漂移的形式包括:主题迁移(智能体开始关注次要方面)、信息稀释(早期关键细节被后续内容淹没)、任务退化(智能体不再执行有效步骤,而是重复无效循环)。当前方法的局限在于:摘要会丢失细粒度信息,检索可能返回无关结果,分层记忆增加了管理开销。此外,所有方法都无法完全解决“模型在长窗口末端的注意力稀释”这一固有问题。未来的上下文工程需要更动态的适应用户意图变化的能力、更精确的遗忘与优先级策略,以及跨模型的上下文压缩标准。
6 Lifecycle and Orchestration / 生命周期与编排
6.1 生命周期状态管理
生命周期层负责智能体状态的生命周期管理和跨循环的控制流。执行器维护的状态包括:任务状态、环境状态、记忆和认知状态,以及注意和暂停状态。状态管理的关键设计决策包括:状态持久性与易失性、状态一致性与恢复、以及状态可见性。
6.2 单智能体内部循环
ReAct范式的执行循环本质上是:模型接收上下文、生成思维、确定动作、执行动作、观察结果并重复。虽然简单,但该循环中的具体工程决策(预算限制、重试策略、失败处理、人类反馈循环)对智能体质量和可靠性有显著影响。
6.3 多智能体编排模式
多智能体系统可以组织为几种模式:主从模式、团队模式、市场模式和层次模式。每种模式在能力扩展和协调开销之间做出不同权衡。
6.4 从问题到拉取请求的完整生命周期管道
在软件工程智能体中,执行器将端到端的软件贡献工作流建模为可管理管道,包括问题解析、分支创建、代码生成、测试执行、评审反馈和拉取请求创建。每个步骤由不同工具或智能体角色处理,执行器编排整个生命周期。
7 Observability and Operations / 可观测性与运营
7.1 追踪与监控平台
可观测性层捕获智能体执行轨迹、成本、故障和可靠性信号。生产部署使用专门的追踪和监控平台,如Langfuse、Arize Phoenix、OpenLLMetry和LangSmith。这些平台提供调用级追踪、成本归因、异常检测和仪表板。
7.2 智能体特定运营平台
一些平台为智能体运营提供更深度集成功能,如LangSmith、LangFuse和Phoenix。它们支持轨迹回放、A/B评估、回归测试和基于反馈的优化。
7.3 成本跟踪与优化
智能体执行会产生可变的令牌和计算成本。可观测性平台提供成本归属、按动作分解、预算管理和成本优化建议。
7.4 可靠性工程
智能体可靠性工程关注故障模式、自动恢复和SLO/SLI监控。关键指标包括任务完成率、平均执行时间、重试率和错误率。
7.5 讨论:走向统一可观测性
当前景观碎片化,不同平台监控不同智能体属性。通向统一可观测性的路径可能包括标准化追踪格式、跨层一致指标和集成式仪表板。
8 Verification and Evaluation / 验证与评估
8.1 执行器评估作为任务到反馈的生命周期
验证层将任务定义和智能体轨迹转换为结构化反馈,用于改善、选择或保证。评估生命周期包括任务和基准接地、执行前准备验证、受控执行和轨迹捕获、多级判断和失败归因、以及持续回归和部署反馈。
8.2 阶段1:任务与基准接地
评估从定义任务规范和基准构建开始。SWE-bench、AgentBench、WebArena和GAIA等基准测试提供了可复现的任务定义。
8.3 阶段2:执行前准备验证
在智能体执行任务前,验证层确保环境正确配置、工具可用和上下文准备好。
8.4 阶段3:受控执行与轨迹捕获
智能体在受控沙箱中执行任务,执行器捕获完整轨迹,包括模型调用、工具调用、交互结果和时间戳。
8.5 阶段4:多级判断与失败归因
轨迹通过多级判断管道:语法正确性、功能正确性、性能、安全和行为约束。失败归因将失败追溯到特定动作或决策点。
8.6 阶段5:持续回归与部署反馈
评估结果反馈到智能体改进循环中,支持回归测试、A/B比较和持续监控。
8.7 总结
验证层将执行器从“尝试执行”转变为“可衡量改进”。其与可观测性和治理的集成对于将智能体部署从实验阶段推进到生产阶段至关重要。
9 Governance and Security / 治理与安全
9.1 权限模型与身份管理
治理层通过权限模型和身份管理控制智能体行为。关键机制包括:基于角色的访问控制、基于属性的访问控制、能力系统和身份联合。生产系统中的权限模型必须平衡安全约束和操作可用性。
9.2 生命周期钩子
生命周期钩子允许在智能体执行的关键点插入安全策略:动作前验证、动作后审计、失败处理和人机交互门控。
9.3 组件强化
组件强化涉及保护执行器基础设施免受攻击:沙箱隔离、输入验证、输出过滤和依赖管理。
9.4 声明式宪法
声明式宪法定义智能体行为约束为可验证规则,而非隐式提示指令。这使策略检查可审计和不可绕过。
9.5 审计基础设施
治理层需要完整审计轨迹以支持合规、取证和报告。审计记录包括所有动作、决策点、策略检查和人员干预。
9.6 在智能体安全景观中定位治理
治理层填补了模型级安全和基础设施级安全之间的空白。它通过策略、权限和审计处理模型不能独自管理的安全问题。
9.7 研究方向
治理层面临开放研究问题:动态策略适应、跨组织治理标准化、隐私保护审计和人在环系统的自动化策略执行。
10 Cross-Cutting Concerns / 跨领域关注点
本章讨论不属于单个ETCLOVG层但跨层出现的关注点,包括可移植性、可扩展性、成本效益、安全性和合规性。
11 Cross-Layer Synthesis / 跨层综合
11.1 成本-质量-速度三元悖论
智能体执行器设计面对一个三方权衡:更高质量的智能体通常需要更多的计算和推理时间,更快的执行可能牺牲质量或增加成本。
11.2 能力-控制权衡
增加智能体能力通常需要放宽控制约束,而加强控制可能限制智能体可以执行的操作。治理层和工具层之间的交互是关键设计点。
11.3 执行器耦合问题
执行器各层之间的耦合程度是一个设计选择。紧密耦合可能提供优化机会,但降低可替换性和可维护性。解耦增加灵活性但可能引入性能开销。
11.4 从智能体框架到智能体平台
智能体执行器正从开发框架演变为完整平台系统,集成了执行、工具、上下文、生命周期、可观测性、验证和治理功能。
11.5 开放研究议程
跨层综合揭示了对集成执行器工程框架、标准化接口、基准测试和评估方法论的需求。
12 Open Problems and Future Directions / 开放问题与未来方向
12.1 强化与扩展执行环境
执行环境安全仍需大量研究:改进沙箱隔离、防止逃逸、管理资源利用率和跨平台可移植性。
12.2 维护长时运行智能体的可靠状态
长时间运行的智能体面临状态持久性、一致性和恢复挑战。需要能优雅处理中间故障和部分失败的状态管理方案。
12.3 从智能体轨迹诊断故障
从复杂智能体轨迹中诊断故障原因需要自动化工具和归因方法。当前缺乏标准化的诊断框架。
12.4 跨智能体、工具和人类的标准交接
智能体之间、智能体与工具之间以及智能体与人类之间的交接需要标准化协议和工件。当前景观碎片化。
12.5 保持执行器随着模型改进而有用
随着语言模型能力增强,执行器工程必须适应:一些当前执行器机制可能变得不必要,而新挑战可能浮现。
13 Conclusion / 结论
本综述系统性地处理了智能体执行工程,提出了ETCLOVG七层分类法,并将170多个开源项目映射到该分类法。核心论点是,执行器,而非模型本身,是真实世界智能体可靠性的瓶颈约束。执行器工程涵盖执行环境、工具接口、上下文管理、生命周期编排、可观测性、验证和治理。通过系统映射,我们揭示了生态系统的密度模式、覆盖空白和新兴设计原则。开放问题包括执行环境强化、长时间运行状态管理、故障诊断、标准化交接以及执行器随模型进步的适应性。我们希望本综述能为智能体执行工程提供共同词汇和系统框架,弥合实践知识和研究词汇之间的鸿沟。
原文信息
英文题目:Agent Harness Engineering: A Survey 作者:Junjie Li, Xi Xiao, Yunbei Zhang, Chen Liu, Lin Zhao, Xiaoying Liao, Yingrui Ji, Janet Wang, Jianyang Gu, Yingqiang Ge, Weijie Xu, Xi Fang, Xiang Xu, Tianchen Zhao, Youngeun Kim, Tianyang Wang, Jihun Hamm, Smita Krishnaswamy, Jun Huan, Chandan K Reddy arXiv ID:llm-harness 类别:cs.AI, cs.SE, cs.LG Comments:Survey on agent harness engineering; project page: Awesome-Agent-Harness 原文链接:https://picrew.github.io/LLM-Harness/main.pdf


