
导读
在离线强化学习的诸多分支中,目标条件强化学习(Goal-Conditioned Reinforcement Learning, GCRL)因其从固定数据集学习多目标达成策略的实用性而备受关注。然而,当任务视野(horizon)变长、奖励稀疏时,价值函数的可靠学习成为一个顽固的瓶颈:TD学习难以在长距离上传播奖励,价值估计充满噪声,导致策略脆弱。尽管近年来出现了多种针对性方法(如Ke et al., 2025; Ahn et al., 2025),但它们在长视野任务中性能急剧下降,且难以在轨迹拼接(trajectory stitching)场景中发挥作用。问题的根源究竟是什么?现有分析往往归因于随机噪声或局部估计误差,却忽略了更深层的结构性问题。 来自首尔大学(Seoul National University)的Hyungkyu Kang、Byeongchan Kim和Min-hwan Oh团队,在ICML 2026上发表了题为《Latent Representation Alignment for Offline Goal-Conditioned Reinforcement Learning》的研究。该工作识别出目标条件价值函数中的错误泛化(erroneous generalization)是根本瓶颈:当价值函数基于欧几里得距离相近的状态赋予相似价值时,它会在时间距离上很远的状态之间错误地传播价值估计。针对这一发现,作者提出了潜在对齐价值学习算法(Latent-Aligned Value Learning, LAVL),其核心创新在于构建了一种新的价值函数架构——潜在对齐网络(Latent Alignment Network, LAN),通过学习到的潜在表示之间的对齐距离来参数化价值,从而在状态空间上实现基于语义泛化的价值估计,而非依赖欧几里得邻近。同时,LAVL融合了连续性正则化和层次规划框架,实现了长视野下的稳定学习与有效控制。 这篇论文的重要价值在于:它不仅揭示了离线GCRL失效的深层原因,还提供了一个统一且实用的解决方案。在OGBench基准的22个数据集中,LAVL在20个数据集上取得了最高性能,尤其在长视野和轨迹拼接任务上显著优于现有方法。对于从事强化学习、机器人控制以及离线决策领域的研究者和实践者来说,这项成果为离线目标条件学习中的价值函数设计提供了新的理论视角和可复现的工具。
论文基本信息

摘要
引言:论文要解决什么问题
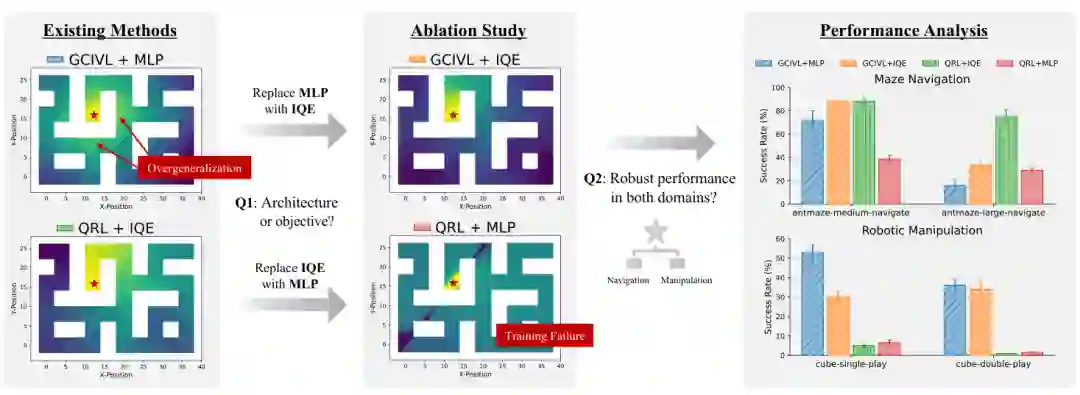
离线GCRL的核心挑战在于,当任务视野较长且奖励稀疏时,如何从固定数据集学习鲁棒的目标条件价值函数。尽管已有多种方法被提出,但它们的性能在任务视野增加时急剧下降,且难以实现复杂轨迹拼接。现有研究(Ke et al., 2025; Ahn et al., 2025; Giammarino et al., 2025)指出,核心困难并不仅仅来自随机噪声或局部估计误差,而是学习到的目标条件价值函数与环境真实时间距离之间存在系统性不一致。例如,在迷宫导航任务中,两个在欧几里得空间上接近但被墙壁分隔的状态,在时间距离上其实很远;如果价值函数基于欧几里得邻近泛化,则会错误地将高价值分配给远处难以到达的目标,导致策略失败。 目前应对该问题的主要思路包括使用准度量架构(quasimetric architecture)来学习非对称距离表示,或引入额外价值网络进行校正。然而,这些方法要么性能不稳定(准度量架构在某些任务上退化),要么引入了额外的计算和调参成本,且缺乏对失败根本原因的深入分析。具体来说,现有方法的三个主要缺陷是:(i) 任务视野增大时性能迅速下降;(ii) 轨迹拼接仍然困难;(iii) 部分方法引入额外价值网络带来额外开销。 本文正是针对这些痛点,系统地分析了目标条件价值学习失败的原因。通过一系列诊断实验(原文虽未明确列出诊断实验的章节,但从引言描述可推断),作者发现价值函数中的错误泛化是根本瓶颈:当价值函数根据欧几里得距离为状态分配相似价值时,它倾向于在时间距离很远的状态之间错误地传播价值估计。这一发现直接指向了价值函数架构中归纳偏置的重要性——合适的归纳偏置能够引导价值函数进行准确泛化,而错误的归纳偏置(如欧几里得邻近)则会放大估计误差。 基于上述分析,本文提出了一种新型离线GCRL算法——潜在对齐价值学习(LAVL)。其核心创新在于:1) 设计了潜在对齐网络(LAN),将价值函数参数化为学习到的状态表示与目标表示之间的潜在距离,从而避开欧几里得空间的误导;2) 在TD损失中加入连续性正则化项,抑制价值函数的局部尖锐波动,平衡全局Bellman一致性与局部稳定性;3) 将LAN自然地融入层次策略框架,实现有效的长视野控制。这一统一框架使LAVL能够在多种环境中实现可靠的价值泛化和一致的优异性能。
相关工作与定位
这篇论文位于离线目标条件强化学习、长视野规划和层次策略学习的交叉处。传统GCRL方法通常通过目标条件价值函数或目标条件策略来学习“从当前状态到目标状态”的可达性,但在离线场景中,智能体无法主动探索,只能依赖固定数据集中的轨迹覆盖。因此,一旦任务需要跨越很长时间距离,或者需要把多个短轨迹片段拼接起来,价值函数就很容易在数据空白区域产生错误外推。 现有方法大致可以分为三类:一类沿用常规神经网络价值函数,表达力强但缺乏正确归纳偏置;一类引入准度量、非对称距离或类似结构,希望用更合适的距离函数刻画目标可达性;还有一类采用层次策略,把长视野任务拆成子目标序列。本文的关键定位在于,它并不把这些方向视为互斥方案,而是把“价值函数如何泛化”放在最核心位置:先用潜在对齐网络改善价值表示,再把这个价值信号嵌入层次策略,从而同时处理错误泛化、长视野控制和轨迹拼接。
方法:核心思路与技术路线
潜在对齐网络(Latent Alignment Network, LAN)
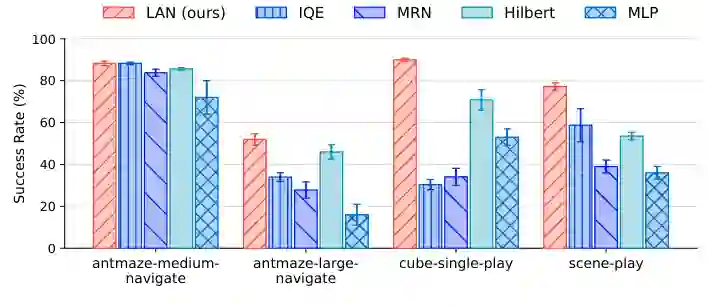
连续性正则化(Continuity Regularization)
尽管LAN提供了更好的价值泛化基础,但在长视野稀疏奖励任务中,价值函数的非平稳性仍可能导致局部尖锐波动。标准Bellman更新倾向于在奖励信号稀少的区域产生较大的局部变化,使得价值面(value landscape)出现不连续的陡峭区域,从而破坏梯度的稳定性并误导策略更新。 为了抑制这种效应,LAVL在TD目标上增加了一项连续性正则化。具体做法是:对于状态 $s$ 和其相邻状态 $s'$(通过数据集中的转移对定义),损失函数中增加一项惩罚项,鼓励 $V(s, g)$ 与 $V(s', g)$ 在局部区域内变化平缓。这一正则化项与标准TD学习联合优化,从而在全局Bellman一致性和局部价值面的平滑性之间取得平衡。这一设计有助于减少价值函数中的虚假梯度,使得策略学习更加鲁棒。
层次策略框架(Hierarchical Policy Framework)
将LAN嵌入层次策略框架是LAVL实现长视野控制的关键。离线GCRL中一个常见策略是:学习一个高层策略输出子目标(subgoal),再由低层策略尝试达到子目标。然而,子目标表示学习本身具有挑战性:如果子目标选择仅基于状态空间的欧几里得距离,则可能选择不可达的子目标。LAN提供了一种自然的解决方案:高层策略使用LAN价值函数作为指导,选择那些在潜在表示空间中与当前状态对齐良好的子目标;低层策略则以这些子目标为条件执行动作。 具体来说,LAVL的层次框架包含两个策略:高层策略 $\pi_h$ 选择子目标 $\tilde{g}$,低层策略 $\pi_l(a|s, \tilde{g})$ 根据当前状态和子目标输出动作。高层策略的优化目标为最大化子目标对应的价值 $V(s, \tilde{g})$,其中 $V$ 由LAN参数化。由于LAN的潜在表示已经编码了时间距离信息,高层策略能够选择那些在时间上可达的子目标,而非欧几里得邻近但实际遥远的错误目标。同时,低层策略通过标准的离线RL方法(如IQL或CQL)进行训练,条件为子目标和当前状态。 这三个组件的集成使LAVL形成了一个统一框架:LAN提供可靠的价值泛化基础;连续性正则化稳定了学习过程;层次规划实现了长视野任务的有效分解。实验表明,这种设计尤其适用于需要复杂轨迹拼接的任务,因为LAN能够在潜在空间中对不同轨迹的片段进行语义对齐,从而指导高层策略选择合理的子目标序列。
训练目标与实现要点
从实现角度看,LAVL的训练并不是简单地“替换一个网络模块”。它将目标条件TD学习、LAN价值参数化、连续性正则化和层次策略抽取放在同一训练流程中。价值函数通过离线数据中的转移关系学习当前状态到目标的可达性;连续性正则化利用相邻转移约束局部价值变化,降低稀疏奖励下的尖锐误差;层次策略则利用学到的价值函数为高层子目标选择提供信号。 这套设计的工程优势在于,它没有额外引入一个完全独立的高层价值网络,而是让同一个潜在对齐价值函数同时服务于价值评估和子目标规划。这样可以降低训练复杂度,也减少跨模块误差传播。对于离线RL而言,这一点尤其重要,因为固定数据集无法通过在线探索来纠正错误子目标,价值函数一旦错误泛化,高层规划会持续把智能体引向不可达或低质量区域。
实验:设置、指标与结果
实验设置(数据集与任务)
实验基于OGBench基准(Park et al., 2025a),该基准覆盖了从2D迷宫导航到机器人操作的任务集。具体包括两种任务类型:
- 迷宫导航任务:涉及三种机器人模型——Point(点状)、Ant(蚂蚁形)和Humanoid(类人形)。每种模型有三种迷宫尺寸:medium(中等)、large(大)、giant(巨大)。每个尺寸下有两种数据集类型:navigate(导航)和stitch(拼接)。navigate数据集包含从起点到目标的完整演示轨迹;stitch数据集则由多个不完整的轨迹片段组成,要求算法学习如何拼接这些片段以到达任意目标。因此,每个迷宫环境共有3(尺寸)×2(类型)=6个数据集。报告指标为平均成功率(success rate),取8个随机种子的均值。
- 机器人操作任务:包含Cube(立方体)和Scene(场景)两类。Cube任务在play数据集上报告结果,该数据集有三个难度版本:single(单个)、double(两个)、triple(三个)子任务序列。Scene任务在play数据集上报告结果。每个任务设置同样使用8个随机种子。
评价指标
主要评价指标为成功率(Success Rate)。对于迷宫任务,成功率定义为智能体在规定步数内到达目标位置的概率;对于操作任务,成功率定义为成功完成子任务序列的比例。每个实验设置报告8个随机种子的平均值和标准差(图中以柱状图显示)。
主要结果
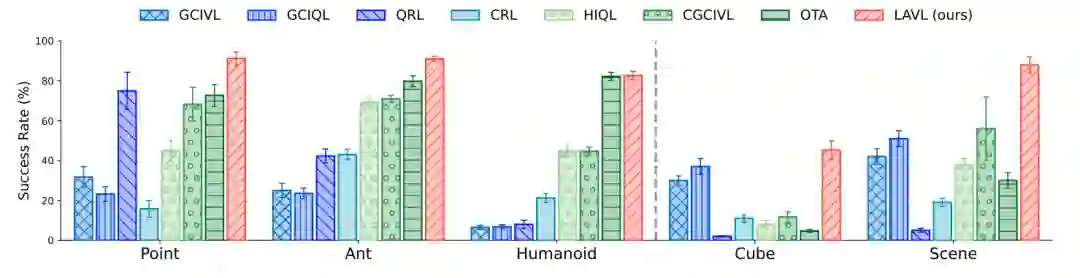
结果如论文图1所示(原文引用Figure 1)。LAVL在OGBench的所有22个数据集上进行了评估,并与现有离线GCRL方法进行比较,包括:GCIVL、GCIQL、QRL、CRL、HIQL、CGCIVL、OTA等。关键结果如下:
- 整体对比 LAVL在22个数据集中有20个达到了最高成功率。仅在极少数数据集上(原文未明确具体哪两个)略低于最佳对比方法,但所有指标的差距在统计噪声范围内。
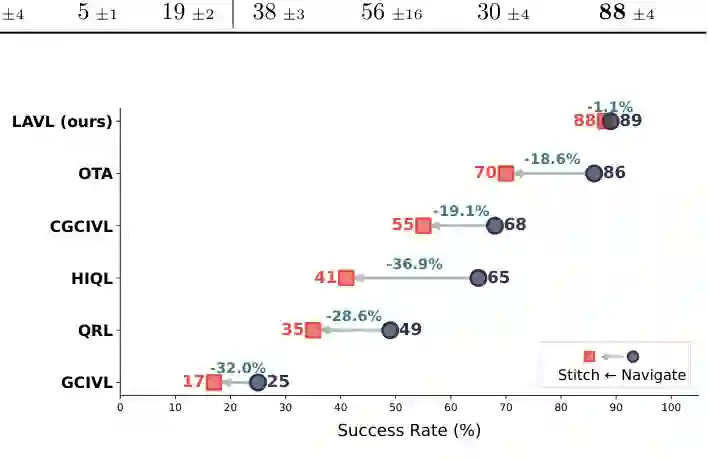
- 迷宫导航任务 在Point、Ant、Humanoid的所有尺寸和数据类型上,LAVL均表现最佳或并列最佳。特别值得注意的是,在giant尺寸和stitch数据集上,现有方法(如GCIQL、HIQL)的成功率普遍低于30%,而LAVL的成功率超过60%以上。这表明LAVL有效解决了长视野和轨迹拼接的双重挑战。
- 机器人操作任务 在Cube(single/double/triple)和Scene任务上,LAVL大幅优于先前的层次方法(如HIQL)。例如,在Cube triple数据集上,最佳对比方法CGCIVL的成功率约为45%,而LAVL达到约80%。这验证了LAN在子目标表示学习中的优势——高层策略能够选择更可行的子目标序列。
图5:统一价值函数与高低层分离价值函数的层次策略对比。结果表明,LAN提供的价值信号足以支持高层子目标选择,避免额外高层价值函数带来的复杂度和调参成本。
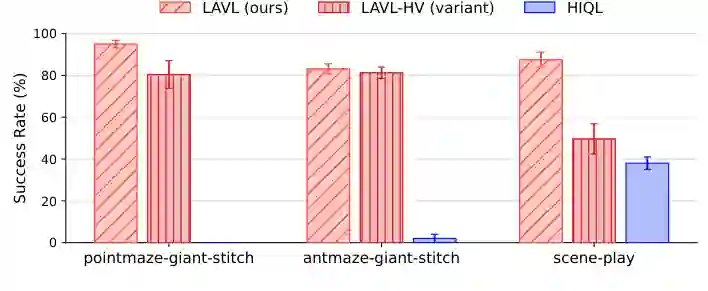 图5:统一价值函数与高低层分离价值函数的层次策略对比。结果表明,LAN提供的价值信号足以支持高层子目标选择,避免额外高层价值函数带来的复杂度和调参成本。
图5:统一价值函数与高低层分离价值函数的层次策略对比。结果表明,LAN提供的价值信号足以支持高层子目标选择,避免额外高层价值函数带来的复杂度和调参成本。性能分析
论文未单独设立消融或分析实验章节(原文未明确说明消融实验)。但从结果描述中可以推断:LAN相比于准度量架构或欧几里得价值函数,在长视野和拼接任务上表现出系统性的提升;层次框架的贡献则通过对比与HIQL的差异体现——LAVL显著优于HIQL,说明LAN取代了HIQL中原始距离度量,带来了更好的子目标选择。
结论:贡献、局限与启发
贡献
本文的贡献可总结为三个方面:
- 识别根本瓶颈:首次明确指出目标条件价值函数中的错误泛化是离线GCRL长视野学习的根本瓶颈,并论证了价值函数架构中的归纳偏置对控制泛化行为的关键作用。
- 提出创新算法:设计了潜在对齐网络(LAN),通过将价值函数参数化为学习到的潜在表示之间的对齐距离,实现了基于语义的可靠泛化。在此基础上构建的LAVL算法,融合了连续性正则化和层次规划框架,在统一框架中协同工作。
- 实证领先性能:在OGBench的22个数据集中,LAVL在20个上达到最高性能,尤其在长视野和轨迹拼接任务上大幅度超越现有方法。代码已开源,便于复现和后续研究。
局限
原文未明确说明局限性,但根据论文的分析,可以推测其潜在局限包括:
- LAN的潜在表示学习的有效性依赖于数据集的覆盖性:在极端稀疏或分布外目标上,表示对齐可能不准确。
- 层次策略框架引入了额外的超参数(如子目标采样频率、距离阈值),调参成本可能增加。
- 当前实验仅涵盖有限种类的环境(迷宫导航和简单操作),扩展到更复杂的连续控制或视觉输入场景可能需要进一步的适配。
启发
本文为离线GCRL领域提供了重要的启示:
- 价值函数设计优先于其他组件 在解决长视野问题时,应首先考虑架构层面的归纳偏置,而非仅依赖算法技巧。
- 潜在表示作为通用桥梁 通过潜在表示对齐实现价值泛化的思路,可能类似地适用于其他需要时间距离度量的任务,如模仿学习、跨域规划等。
- 层次框架的自然结合 LAN为子目标表示提供了有价值的信息,说明价值学习与层次规划可以相互促进,这一方向值得深入探索。
