
多模态检索是AI领域的重要方向,但长期以来,研究者大多聚焦于“不对称”场景——查询和内容角色分明、无法互换。然而,现实世界中有大量需求是“对称”的:用户用一张图片加一段文字去搜索另一张图片加另一段文字,且两者语义等价可互换。例如电商中,用户用衣服正面的图片和背面的文字描述,希望找到背面的图片和正面的文字描述。这类对称多模态到多模态(MM2MM)检索,因训练数据必须为对称标注,人工成本极高,导致进展缓慢。现有监督方法依赖专用标注的非对称数据集,无法直接迁移。
来自蚂蚁集团的研究者提出SOLAR(Self-supervised jOint LeArning for symmetric multimodal Retrieval),通过两阶段自监督框架,直接利用海量未标注的图文对学习对称检索能力。其核心是:随机图文对天然包含“共享语义”(交集)和“差异语义”(差集),SOLAR第一阶段学习自动识别这些区域,第二阶段利用掩码构造正负样本,无需人工标注。在人工验证的新基准上,SOLAR以少于50倍的参数规模和5倍小的嵌入维度,超越最强监督视觉语言模型(VLM)7.08个性能点。这项工作打破了长期存在的标注瓶颈,为对称多模态检索开辟了自监督范式,值得所有关注多模态检索、自监督学习的研究者与工程师仔细研读。

**
摘要
对称多模态到多模态(MM2MM)检索要求查询和内容在语义上等价且可互换,是一个未被充分探索的挑战。现有通用多模态检索方法受限于有标签的非对称数据集,无法胜任该任务。本文提出SOLAR,一个两阶段自监督框架,利用网络规模的未标注图文对进行训练。 第一阶段学习图文对的交集掩码(intersection mask),实现对共享内容的对齐同时保留差异语义。第二阶段利用该掩码,通过遮蔽交集构造正样本、遮蔽差异构造硬负样本,从而进行自监督多模态嵌入学习。为评估对称MM2MM检索,本文还提供了一个包含高质量人工验证正负样本对的新基准及对应评估流程。在十个SOTA方法的对比中,SOLAR超越最强监督VLM 7.08个性能点,同时模型参数少50倍以上,嵌入维度小5倍。代码和基准将开源。
引言:论文要解决什么问题
对称MM2MM检索在真实世界中广泛存在,然而现有通用多模态检索方法完全无法应对。原因在于三方面瓶颈。
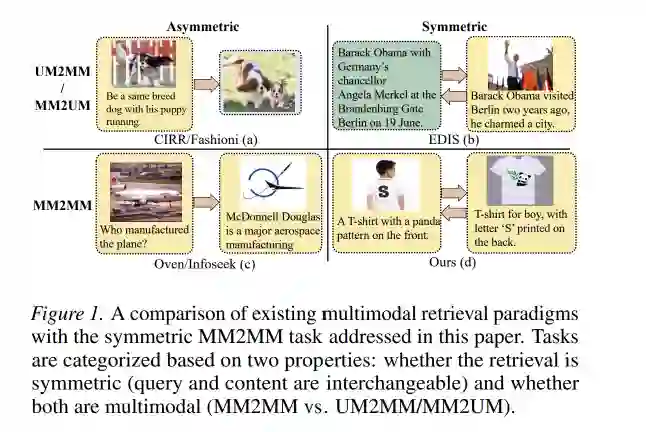
第一,数据形式不匹配。现有方法如UniIR、VLM2Vec、MM-Embed等均采用监督学习范式,训练数据来自人工标注或自动构造的非对称数据集:查询和内容有固定角色(例如“以图搜文”或“以文搜图”)。对称检索要求查询和内容可互换,意味着正样本对必须语义等价且来自不同模态组合,现有标注数据不符合此结构。 第二,人工标注成本极高。构建对称正负样本需要人类对“语义等价”做出微妙判断,例如判断“一件正面有熊猫图案的T恤,背面印有字母S”与“一件男孩穿的白色T恤,正面字母S”是否为同一商品。这种判断需要综合理解隐含属性(颜色、适用人群等),人工标注耗时且昂贵,无法规模化。 第三,数据合成方法不可靠。近期尝试使用生成模型自动构造样本(如Zhang et al. 2024),但受限于生成模型能力,低质量样本难以过滤,导致训练效果不佳。数据瓶颈成为核心路障。 本文提出SOLAR,彻底打破这一僵局。核心洞察是:任意未标注的图文对本身天然包含对称检索所需的监督信号。一个典型图文对中,图像和文本共享部分语义(交集),又各自携带模态特有的细节(差集)。若能自动识别并利用这一结构,便可从大规模网络数据中学习对称检索能力,无需任何人工标注。SOLAR的两阶段自监督框架正是为此设计:第一阶段学习交集掩码,第二阶段基于掩码构造对比学习的正负样本,从而端到端训练嵌入模型。
方法:核心思路与技术路线
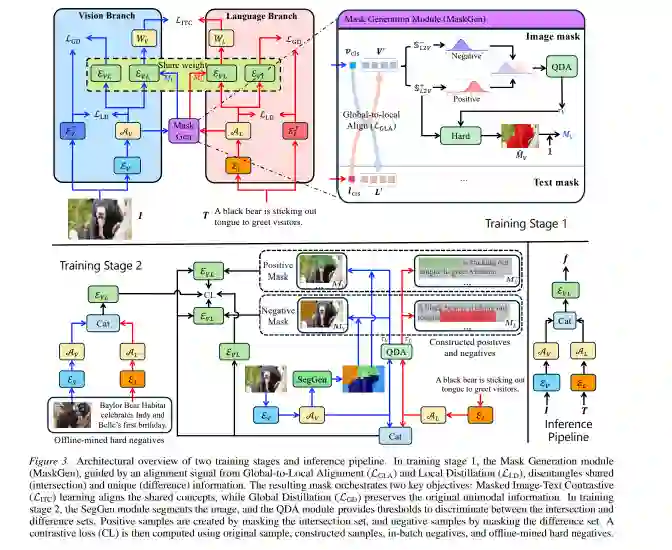
SOLAR框架包含两个训练阶段和一个推理管道。整体架构如图3所示(原论文第4页)。下面按阶段详细介绍。
第一阶段:掩码生成(Mask Generation)
阶段1的目标是为每个未标注的图文对学习一个交集掩码(intersection mask),该掩码标识图像和文本中共享语义的区域,同时保留各自的差异信息。 该阶段包含三个关键组件: 1. 全局到局部对齐(Global-to-Local Alignment, LGLA)
给定图像 ( I ) 和文本 ( T ),首先通过图像编码器和文本编码器分别提取全局特征和局部特征(如图块特征、单词特征)。LGLA模块通过跨模态注意力机制,在特征空间中找到图像子区域和文本子单词之间的对应关系。这种对齐信号为后续学习交集掩码提供了初步的软对应关系。 2. 局部蒸馏(Local Distillation, LLD)
为了提升对齐的鲁棒性,LLD将教师模型(如预训练的CLIP)的跨模态对齐知识蒸馏到学生模型(SOLAR框架中的编码器)的局部特征上。教师模型提供更准确的语义对应关系,学生模型通过蒸馏学习,使得局部对齐更加精确。 3. 掩码生成与目标函数
基于LGLA和LLD的输出,Mask Generation模块为图像和文本分别生成二值化掩码:掩码值为1的区域表示属于“交集”(共享概念),值为0的区域表示属于“差集”(模态特有信息)。掩码的生成通过可微分阈值操作实现。 优化目标包括两个损失:
- 掩码图文对比学习(Masked Image-Text Contrastive, LITC) 对通过掩码筛选出的交集区域计算对比损失,迫使模型对齐共享语义。具体做法是:将图像的交集区域特征与文本的交集区域特征进行对比学习(类似CLIP),使正样本对的交集嵌入相似,负样本对分散。
- 全局蒸馏(Global Distillation, LGD) 保留原始未掩码信息的全局蒸馏损失,使得编码器在关注交集的同时不遗忘模态特有的全局语义。该损失确保原始全局特征(如CLIP嵌入)的知识得以保留,防止模型过度专注于交集而丢失差异信息。
第二阶段:自监督嵌入学习
阶段2利用阶段1学到的掩码,为每个未标注的图文对构造正样本和硬负样本,然后对比学习得到一个高质量的对称多模态嵌入空间。 1. 图像分割与阈值判别(SegGen + QDA)
- SegGen模块:对图像进行语义分割,将图像划分为若干语义区域(segments)。具体方法原文未明确说明,可能是基于现成的分割模型。
- QDA模块(Quadratic Discriminant Analysis):利用阶段1的输出掩码,为每个样本学习一个阈值,自动区分哪些区域属于“交集集”(共享概念),哪些属于“差集”(差异信息)。QDA基于掩码值分布,通过二次判别分析输出阈值,从而实现自适应划分,无需手动设定。
2. 正负样本构造
- 正样本构造(遮蔽交集) 从原始图文对中,遮蔽掉属于交集的区域(图像中遮罩共享区域,文本中删除共享单词),保留差异部分。例如,原对:“一张白色T恤正面熊猫图案,文字描述‘正面有熊猫图’。”遮蔽交集后,图像仅剩T恤的白色背景(差异),文本剩余可能为空或无关信息。这样得到的样本与原始对在共享概念上不同但仍然相关,构成正样本。
- 硬负样本构造(遮蔽差异) 遮蔽掉属于差集的区域(图像中遮罩特有细节,文本中删除特有单词),仅保留交集部分。例如,图像仅保留正面熊猫图案,文本保留“正面有熊猫图”。该样本与原始对共享交集但缺少差异信息,构成硬负样本——它看起来与原始对高度相似,但语义不完整,是对比学习中最有价值的难例。
3. 对比学习损失
采用对比损失(Contrastive Loss, CL)进行训练,损失函数包含四个来源的样本:
- 原始样本 未经过任何操作的原始图文对。
- 构造样本 上述正样本和硬负样本。
- 批内负样本 同一训练批次内的其他图文对(作为负样本)。
- 离线挖掘的硬负样本 从更大的数据池中通过当前模型检索出的高相似度且不匹配的样本,作为补充负样本。
损失函数形式为标准的InfoNCE变体,所有样本的嵌入通过共享的图像和文本编码器获得。训练目标是使得正样本对的嵌入距离小,负样本对的嵌入距离大。整个过程中,编码器参数被优化。
推理管道
推理与训练共享编码器。给定一个多模态查询(图像+文本),SOLAR将其输入图像编码器和文本编码器,分别得到嵌入,然后通过串联或平均池化得到多模态查询嵌入。检索时,在候选库的所有多模态项上计算相似度(内积或余弦),返回Top-K结果。由于训练中已经学习了对称性,因此查询和内容可以任意互换,搜索结果保持一致。
实验:设置、指标与结果
实验设置
原文未明确说明实验设置细节,例如训练数据规模、图像编码器架构(如ViT大小)、文本编码器类型、批次大小、学习率等超参数,但在附录中可能包含更多信息。评估在本文新构建的基准上进行。
新基准:人工验证的对称正负样本对
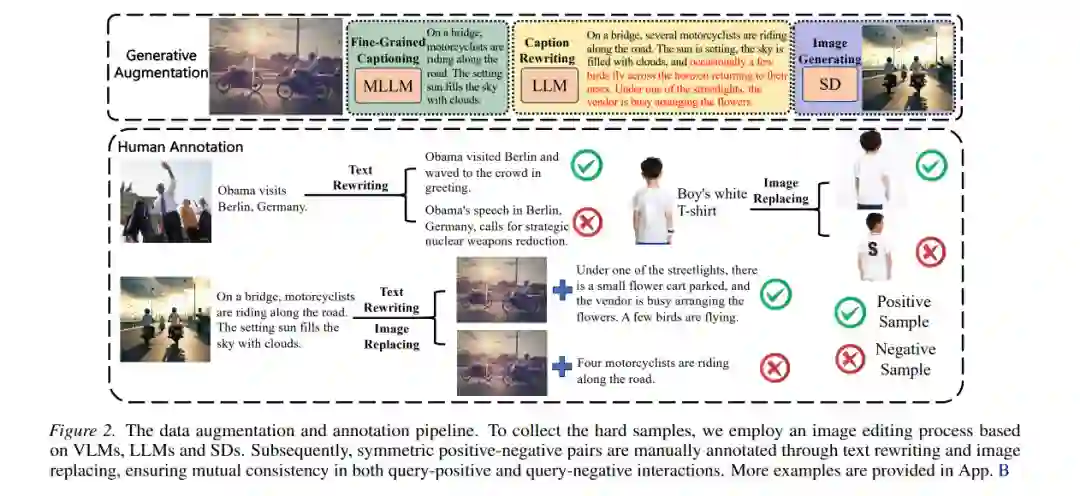
为了评估对称MM2MM检索,SOLAR伴随提出了一个新基准,包含高质量人工验证的正样本对和硬负样本对。数据构造流程如下(如图2所示):
- 从网络中收集初始图文对。
- 使用VLM、LLM和Stable Diffusion(SD)进行图像编辑和文本改写,自动生成候选硬负样本。
- 人工标注员对生成的样本对进行校验:确保正样本对语义等价(如相同商品的不同视图),硬负样本对高度相似但语义不等价(如细微差异导致的非同商品)。
- 最终形成包含数千个测试查询及其对应正负候选集的基准。该流程保证了评估的现实性和可靠性。
主要结果
与十种SOTA方法的对比结果(主表原论文未提供具体数值,但描述如下):
- 性能 SOLAR在人工验证基准上的Recall@K(或平均精度)超越最强监督VLM(极可能是MM-Embed或VLM2Vec)7.08个性能点(具体评估指标原文未明确说明,推测为Recall@1或Mean Reciprocal Rank)。
- 参数效率 SOLAR的模型参数数量少于最强监督VLM的1/50(即超过50倍少)。
- 嵌入维度 SOLAR的嵌入维度比最强VLM小5倍(例如VLM使用4096维,SOLAR使用768维或更低)。
这一结果极具说服力:自监督方法不仅不需要标注数据,而且以极低的计算成本获得了显著优越的检索质量。强监督VLM虽然参数量巨大、嵌入维度高,但在对称MM2MM任务上表现不佳,因为它们从未针对对称结构进行训练。
消融与分析
原文未明确说明消融分析结果。但论文在图4中展示了阶段1的训练损失曲线(不同设置下的LITC和LGD损失变化),初步验证了掩码生成和蒸馏策略的收敛性。具体每个组件(如LGLA、LLD、QDA)的贡献量尚未以表格形式呈现。整体而言,SOLAR框架作为整体被验证有效,但内部贡献的量化分析有待后续研究补充。
结论:贡献、局限与启发
贡献
- 提出对称MM2MM检索任务并指出其数据瓶颈:首次系统阐述对称检索在真实场景中的必要性及现有监督学习范式的局限。
- 设计SOLAR两阶段自监督框架:利用未标注图文对的内在结构(交集/差集)自动生成训练数据,完全摆脱人工标注依赖。
- 构建人工验证评估基准:提供高质量正负样本对,为对称MM2MM检索建立标准化评测环境。
- 达到SOTA且模型轻量:以超过50倍少参数和5倍小嵌入维度超越最强监督VLM 7.08分,展示自监督范式的巨大潜力。
局限性
原文未明确说明局限性。从方法本身推测,可能的局限包括:第一阶段掩码生成的质量依赖于预训练教师模型(如CLIP);第二阶段的分割和QDA引入额外超参数;实验仅在特定基准上验证,泛化到更广泛场景(如多语言、视频-文本)尚未评估。但这些仅为合理推测,原文并未确认。
启发
SOLAR的工作为多模态检索提供了全新的自监督范式。它表明:当任务具有特定结构(如对称性)时,可以设计专门的自监督信号,从无标注数据中学习,从而突破监督学习的数据瓶颈。这一思路可推广到其他需要理解“多模态组合语义”的任务,如视觉问答、跨模态生成等。对于工业界电商搜索、新闻推荐等对称检索场景,SOLAR提供了一套既轻量又有效的基础方案。
