从二维(2D)输入重建三维(3D)表征是计算机视觉与图形学领域的一项基础任务,也是人类理解物理世界并与之交互的基石。尽管传统方法能够实现高保真度重建,但往往受限于低效的**逐场景优化(per-scene optimization)或类别特定(category-specific)**的训练模式,从而阻碍了其实际部署与可扩展性。
鉴于此,**通用型前馈式三维重建(generalizable feed-forward 3D reconstruction)在近年来取得了突飞猛进的发展。通过训练模型在单次前向传播中将图像直接映射为 3D 表征,这类方法实现了高效的重建效率及稳健的跨场景泛化能力。本综述受一个核心观察所驱动:尽管几何输出表征形式各异(涵盖了从隐式场(implicit fields)到显式原语(explicit primitives)**的多种形式),但现有的前馈式方案在宏观架构模式上具有高度一致性,例如图像特征提取主干、多视图信息融合机制以及几何感知(geometry-aware)的设计原则。 因此,我们剥离了表征形式的差异,转而聚焦于模型架构设计,提出了一种全新的、与输出格式无关的分类体系。该分类法将研究方向组织为驱动近期发展的五个关键问题: 1. 特征增强: 用于实现稳健的 2D 到 3D 提升; 1. 几何感知: 为稀疏输入引入几何先验; 1. 模型效率: 旨在降低计算损耗与显存占用; 1. 增强策略: 利用生成模型进行数据与能力增强; 1. 时序感知模型: 用于动态 4D 重建。
为了给该分类体系提供实证支撑与标准化评估,我们进一步全面审视了相关基准测试(benchmarks)与数据集,并对基于前馈 3D 模型的现实应用进行了详尽的分门别类。最后,我们概述了未来的研究方向,旨在解决可扩展性、评估标准及世界建模(world modeling)等开放性挑战。更多资源可见于我们的 GitHub 仓库及项目主页。 关键词前馈式 3D(Feed-forward 3D)、网格(Mesh)、有符号距离函数(SDF)、占用率(Occupancy)、3D 高斯泼溅(3DGS)、神经辐射场(NeRF)、点图(Pointmaps)、综述
1. 引言 (Introduction)
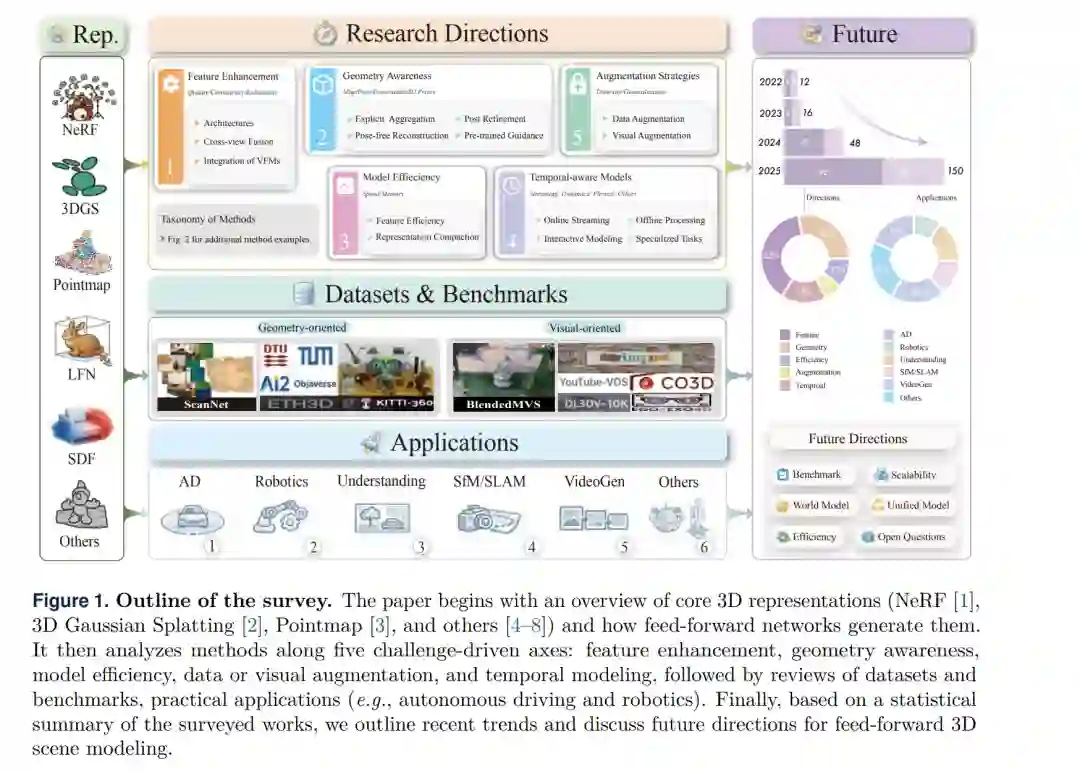
从图像或视频中建模三维场景(包括其几何结构、外观、运动及交互)是计算机视觉领域的一个核心问题,在机器人、增强现实/虚拟现实(AR/VR)、数字遗产保护以及自动驾驶系统等领域具有广泛的应用。传统方法,如运动恢复结构(SfM)[9]、多视图立体视觉(MVS)[10],以及最新的神经辐射场(NeRF)[1] 和 3D 高斯泼溅(3DGS)[2],已经奠定了重要的基础,逐步提升了几何保真度与照片级真实感。然而,这些方法通常依赖于逐场景优化(per-scene optimization),计算量大且速度缓慢,限制了其可扩展性与实时应用。这使得开发更高效、泛化能力更强的范式成为迫切需求。 前馈式三维建模(Feed-forward 3D modeling) [11, 12] 近年来作为一种替代范式脱颖而出。前馈式方法不再是在测试时对场景表征进行优化,而是学习一种从输入图像到显式或隐式三维表征的映射。在这一过程中,可以选择性地结合相机位姿或深度先验等辅助信号 [3, 13–19],并仅通过单次前向传播(single forward pass)完成。这种设计显著提高了推理速度,增强了跨场景的摊销效率(amortization),并能无缝集成到下游任务的端到端管线中。然而,这一范式也带来了新的技术挑战,包括多视图特征融合、几何细节保留、模型效率以及动态场景的时序一致性。应对这些挑战持续推动着该领域的快速进步与方法论创新。 基于前馈式三维重建的飞速发展,本综述旨在系统地总结近期进展,特别是明确其中的关键挑战。以往的综合性综述 [20] 主要依据三维表征(3D representations)来组织现有方法。与之不同,我们的工作采用问题驱动(problem-driven)的视角,提供了一个结构化的、端到端的研究全景,如图 1 所示。本综述涵盖了表征形式、五大关键研究方向(详细分类见图 2)、数据集与基准测试、广泛的现实应用以及未来方向。 为了以一种既能反映技术进步又能体现潜在挑战的方式组织该领域,我们没有简单地按输出的三维表征对前人工作进行归类。虽然网格(Mesh)、SDF、NeRF、3DGS、点图(Pointmap)等表征提供了一个有用的描述层,但它们往往掩盖了驱动近期前馈式方法的不同功能目标和设计动机。在实践中,基于相同表征的方法可能针对完全不同的问题(如特征鲁棒性、几何歧义或计算效率),而应对相似挑战的方法则可能采用迥异的表征。因此,在简要回顾前馈式三维重建中常用的表征之后,我们采用了一种问题驱动的分类法,根据方法旨在解决的核心挑战进行分类(见图 1 和图 2)。具体而言,我们确定了五个关键研究方向: 1. 特征增强 (§4.1): 旨在提升隐式特征表征的质量,以实现对三维场景更准确的解码; 1. 几何感知 (§4.2): 针对底层场景几何的稳健且精确的推理; 1. 模型效率 (§4.3): 解决实时和资源受限环境下的计算与显存瓶颈; 1. 增强策略 (§4.4): 丰富数据分布与视觉表征,以克服稀疏输入和训练多样性有限的问题; 1. 时序感知模型 (§4.5): 捕捉帧间的几何与运动一致性,用于低延迟的动态 4D 场景建模。
这一视角能更好地捕捉现有方法的功能角色、设计权衡及发展趋势,并为理解前馈式三维重建的当前进展与未来方向提供更清晰的路线图。 因此,我们也重新评估了数据集与基准测试。除了传统的数据集罗列,我们还根据其核心关注领域对数据集进行了分类:几何导向型数据集(如 DTU [21], ScanNet [22], Replica [23]),侧重于点云、深度和位姿;以及视觉导向型数据集(如 NeRF-Synthetic [1], RealEstate10K [24], DL3DV [25]),优先考虑照片级真实的视图合成。 为了进一步说明基准测试的选择如何影响研究进展,我们系统地整理了代表性方法在关键数据集上的报告性能,揭示了不同类别间的显著趋势。我们得出了几个重要的数据驱动结论,例如需要建立标准化的场景复杂度量化方法,以及更清晰地报告几何多样性 [24, 25]。这些发现将在我们关于未来方向的讨论中进行深入探讨 (§7)。 在总结方法与基准测试之后,我们转向前馈式三维重建在现实应用中日益增长的影响力。这一范式已从研究概念演变为实用技术,正推动着自动驾驶 (§6.1)、机器人 (§6.2)、场景理解 (§6.3)、SfM 与 SLAM (§6.4)、视频生成 (§6.5) 以及视觉定位 (§6.6) 等领域的发展。这些应用共同展示了前馈式三维重建如何推进计算机视觉的基础任务,实现前所未有的效率,并显著降低实际部署的门槛。 尽管已取得显著进展,前馈式三维重建仍是一个活跃的前沿领域,面临许多开放性挑战与机遇。最后,我们概述了几个充满前景的未来方向,涵盖基准测试的严谨性 (§7.1)、模型效率 (§7.2)、可扩展场景表征 (§7.3)、世界模型 (§7.4)、统一感知与重建 (§7.5) 以及其他关键的开放问题 (§7.6)。本综述中引用的所有文献与资源均已在 ff3d-survey.github.io 进行整理并持续更新。