

针对大语言模型(LLM)系统安全性的研究正发生范式偏移:从关注“模型是否会泄露训练数据”,转向一个更具深远影响的问题——“一个具备持久化长期记忆的智能体,是否会被持续塑造、遭受跨会话投毒、被越权访问,并在共享的组织状态中传播风险?”近期的综述研究虽已涵盖记忆架构、智能体记忆机制以及部分记忆安全风险,但鲜有工作将持久化可写记忆的认识论(Epistemic)与治理属性视为其构成独立安全问题的核心诱因。
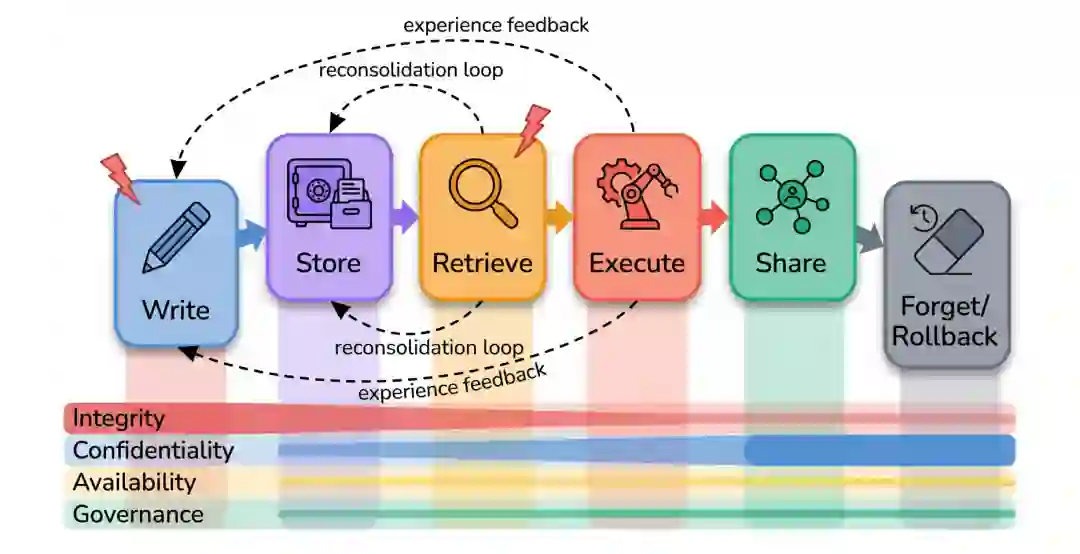
本文旨在填补这一细分领域的研究空白。借鉴认知神经科学与记忆哲学,我们将智能体记忆刻画为具塑性(Malleable)、可重写性及社会传播性的实体。据此,我们构建了一个涵盖六个阶段——写入(Write)、存储(Store)、检索(Retrieve)、执行(Execute)、共享(Share)以及遗忘/回滚(Forget/Rollback)——的记忆生命周期分析框架,并将其与完整性、机密性、可用性和治理性四大安全目标进行交叉分析。利用该框架,我们对关于记忆投毒、提取、检索破坏、控制流劫持、跨智能体传播、回滚及治理的现有文献进行了系统梳理,并探讨了代表性架构如何决定哪些生命周期阶段具备显式可治理性。 本综述具有三大核心发现: 1. 研究分布失衡:现有文献高度集中于写入时与检索时的完整性攻击;而关于机密性、可用性、存储/遗忘阶段以及良性持久化失效(如压缩、漂移或幻觉导致的非对抗性记忆错误)的研究依然稀缺。 1. 架构治理缺失:在所有受调研的记忆架构中,均未实现本文提出的全部九种治理原语;其中,**写入门控验证(Write-gate validation)与删除后验证(Post-deletion verification)**是现有系统的共同盲点。 1. 防御工具链亟待加强:将 LLM 自身作为记忆安全工具(如自动化红队测试、防御侧验证、反事实压力测试)的次要研究路径虽尚处起步阶段,但至关重要。若防御机制未经适应性 LLM 驱动的红队压力测试,则无法达到成熟安全领域所要求的严谨性。
最后,我们将上述观察统一于**“记忆主权”(Mnemonic Sovereignty)概念之下——即系统对于“何物可写、谁人可读、何时更新授权以及哪些状态可被遗忘”具备的可验证、可恢复的治理能力。我们认为,未来安全智能体的核心竞争力将不再仅取决于检索容量,更取决于其记忆治理(Memory Governance)**的质量。
1 引言
大语言模型(LLM)安全研究最初围绕两个对象展开:编码在模型权重中的参数化知识(Parametric knowledge),以及单轮或多轮对话中的提示词操控。然而,随着智能体从“无状态聊天机器人”演进为配备持久化长期记忆的自主系统,安全关注的核心正在发生迁移。攻击者不再仅仅追求影响当前的回复,而是旨在改变系统在未来的记忆、检索、规划与行动方式。 这种转变意味着,记忆安全既不是提示词注入的附属分支,也不是 RAG 安全的同义词。它构成了一类独立的系统安全问题,因为长期记忆引入了至少三种新颖属性: * 持久性 (Persistence):一旦恶意内容沉积到长期记忆中,它可能会在后续数十次甚至数百次匹配其检索键的任务中被反复调用。不同于单次提示词注入的效果随当前上下文窗口结束而消失,中毒的记忆条目可以跨越无限数量的未来会话而持续存在。 * 状态性 (Statefulness):核心问题不再是“当前输入是否有害?”,而是“系统目前处于何种记忆状态?”一个累积了大量细微偏见情节记忆(Episodic memories)的智能体,可能在单条记忆触发传统安全分类器之前,就已表现出行为漂移(Behavioral drift)。 * 传播性 (Propagation):在多智能体及共享状态系统中,污染可以通过内部渠道(如智能体间消息、共享存储、工具参数)传播,产生跨越会话、角色和用户边界的级联效应。最近的基准测试进一步表明,多智能体系统中的隐私泄露主要集中在这些内部渠道,而非最终面向用户的输出。
安全威胁未必总源于对抗性攻击。第四个属性是,持久化记忆在无对手的情况下也可能失效:共享存储的静默跨用户污染、个人资料在失效上下文中的过度应用,以及记忆诱发的“趋炎附势”(Sycophancy)行为,均源于记忆增强型智能体系统的常规运行。因此,我们将“记忆安全(Memory security)”视为“记忆安全性(Memory safety)”的超集:对抗轴与良性持久化轴共享生命周期与防御手段,但在所需证据类型上有所不同。 如果传统的提示词注入类似于对单次执行流的短暂劫持,那么对长期记忆的攻击则更接近于对系统状态的持久化污染。即便现有的提示词注入防御方案在静态评估中表现良好,最新的联合评估也显示其在强对抗模型下极具脆弱性。这强调了记忆领域的任何防御主张都必须在强自适应威胁模型下进行评估,包括常规基准测试无法涵盖的跨会话和持久状态场景。 因此,一份真正探讨智能体安全的综述必须超越“模型是否会被误导”这一表层问题,去面对更深层的挑战:系统是否会将它被误导后相信的内容作为“自身的过去”进行保存?且是否会基于这段错误的过去反复采取行动?
1.1 重新定义记忆
本综述不将记忆视为一种附加缓存,而是将其构思为一种人工记忆系统(Artificial mnemonic system):一个具备写入、提取、压缩、重组、共享和遗忘能力的系统。此类系统影响着主体连续性、行为习惯和责任归属;它既是能力的源泉,也是全新的攻击面。
借鉴认知神经科学与记忆哲学,我们观察到人类记忆并非忠实的档案库,而是一种重构性(Reconstructive)、可再巩固(Reconsolidatable)、可外部化且具有社会传染性的机制。这些特性在 LLM 智能体记忆模块(配置文件记忆、情节记忆、RAG 外部记忆、共享组织记忆)中得到了放大。其结果是,记忆攻击无需进行暴力的覆盖写入,而可以通过诱导、来源混淆、读取时重写和社会传播来实施,从而逐渐改变系统对其过去的理解。
我们并非主张人类记忆与智能体记忆在生物学上等价,而是将其作为识别持久化可写记忆安全属性的分析透镜。我们将认知术语分为两类:结构类比(如:来源监控 $\rightarrow$ 出处追踪)用于生成可测试的设计需求;隐喻类比(如:“记忆传染”)则作为直观平行的教学手段。
1.2 研究问题与贡献
本综述的核心问题可简述为:当 LLM 智能体获得可写、可检索、跨会话持久的长期记忆时,安全格局发生了怎样的定性变化?
为此,我们开展了三项任务: 1. 理论奠基:引入出处失效、读取时重写、共享记忆传染等概念,解释记忆为何本质上是一个安全问题(第 2 节)。 1. 分析框架:提出记忆生命周期框架,沿“写、存、取、行、享、忘/回滚”六个阶段与四大安全目标进行交叉分析(第 3 节)。 1. 系统综述:调查 2023 年至 2026 年间长记忆智能体的攻击面、防御机制与架构(第 4–12 节)。
本综述最终凝练出一个规范性概念:记忆主权(Mnemonic sovereignty)。我们认为,下一代安全智能体的竞争将不仅取决于检索容量,更取决于其**记忆治理(Memory governance)**的质量。
1.3 研究范围
我们关注运行时记忆(Runtime memory):智能体在部署后持续读写的状态。我们将研究对象分为四类: 1. 配置文件记忆(Profile memory):用户偏好、身份、权限及长期个性化信息。 1. 情节/轨迹记忆(Episodic / trajectory memory):交互历史、成功案例、失败教训及过程反思。 1. 外部检索记忆(External retrieval memory):RAG 数据存储、向量索引及图增强检索结构。 1. 共享组织记忆(Shared organizational memory):多智能体共享状态与跨租户知识片段。
为什么长上下文(Long context)不能取代长期记忆?
尽管上下文窗口已扩展至百万级 token,但长上下文解决了会话内召回,却无法处理长期记忆的独立安全属性:跨会话持久性(窗口在会话结束时清空)、跨主体共享性(窗口通常是单人私有的)以及压缩血缘(Compression lineage)(自动摘要与反思作用于存储的记忆)。因此,两者是互补关系。
1.4 与现有综述的关系
尽管近期出现了多篇关于智能体记忆或 RAG 安全的综述,但本文在三个方面具有独特性: 第一,我们将持久化可写记忆的认识论与治理属性视为安全分析的核心; 第二,我们构建了六阶段记忆生命周期,揭示了“存储”、“共享”和“遗忘”等以往被忽略的阶段; 第三,我们提出了记忆主权的规范性框架,将完整性、机密性、可用性和治理性目标统一起来。
1.5 综述方法论与证据分级
检索策略:我们检索了 2023 年 1 月至 2026 年 4 月期间的 ACM、IEEE、ACL、USENIX、arXiv 等数据库。核心关键词涵盖记忆投毒、长期/情节记忆、RAG 破坏、记忆提取、共享存储及记忆治理/遗忘等。我们对各类别的种子论文进行了前向和后向引用追踪。
****
**


