
导读
Transformer 的 Softmax 注意力机制虽然强大,但其二次复杂度限制了高分辨率图像和长序列生成任务的可扩展性。本文提出 T⁵(Transformer To Test-Time Training)——一种基于测试时训练(TTT)的线性复杂度架构,可直接继承预训练 Softmax 模型的全部权重,仅需极少的微调即可恢复原有性能。在 Stable Diffusion 3.5 上,T⁵ 仅用 4×H20 GPU 上约 1 小时的微调,即在图像质量上与原始模型持平,同时实现 1.32×(1K分辨率)和 1.47×(2K分辨率) 的推理加速。
- 论文标题:Linearizing Vision Transformer with Test-Time Training
- 作者:Yining Li, Dongchen Han, Zeyu Liu, Hanyi Wang, Yulin Wang, Gao Huang(清华大学)
- 发表:ICML 2026
- 论文链接:https://arxiv.org/abs/2605.02772

图1:SD3.5-T⁵ 生成的 2K 图像(左)和 1K 图像(右)
1 背景与动机
Transformer 的 Softmax 注意力计算复杂度为 O(N²),输入序列 N 增大时计算和内存开销呈平方级增长。这在处理高分辨率图像或长上下文生成时成为严重瓶颈。
为此,研究者提出了多种线性复杂度注意力机制。然而,训练一个线性模型不仅成本高昂,更核心的挑战在于:如何将已有的预训练 Softmax 模型高效转换为线性模型?现有的方法存在以下问题:
- 线性注意力的表达能力有限,难以直接继承 Softmax 的权重
- 需要复杂的蒸馏策略或多阶段训练
- 通常只能继承 MLP 层的权重,丢弃了注意力层中的宝贵知识
本文从结构对齐和表征对齐两个角度系统性地解决这一转换难题。
2 核心方法
2.1 结构对齐:Softmax 注意力本质上是双层动态 MLP
本文的核心洞察是:Softmax 注意力可以重写为一个双层动态 MLP:
Attn(q, K, V) = σ(q · K^T) · V = σ(q · W1^dyn) · W2^dyn
其中 W1^dyn = K^T, W2^dyn = V,σ 是 Softmax。每个 query 都经过一个由 K、V 动态构建的双层非线性 MLP。
相比之下,标准线性注意力退化为单层动态变换:
LinearAttn(q) = φ(q) · (φ(K)^T · V)
这种单层线性结构缺乏 Softmax 的非线性表达能力。
TTT 的桥梁作用:测试时训练(TTT)维护一个内部模型 f_W,通过梯度下降在线更新其参数。当内部模型选用双层 MLP 时,TTT 的输出具有与 Softmax 注意力完全相同的结构:
TTT(q) = σ(q · W1') · W2'
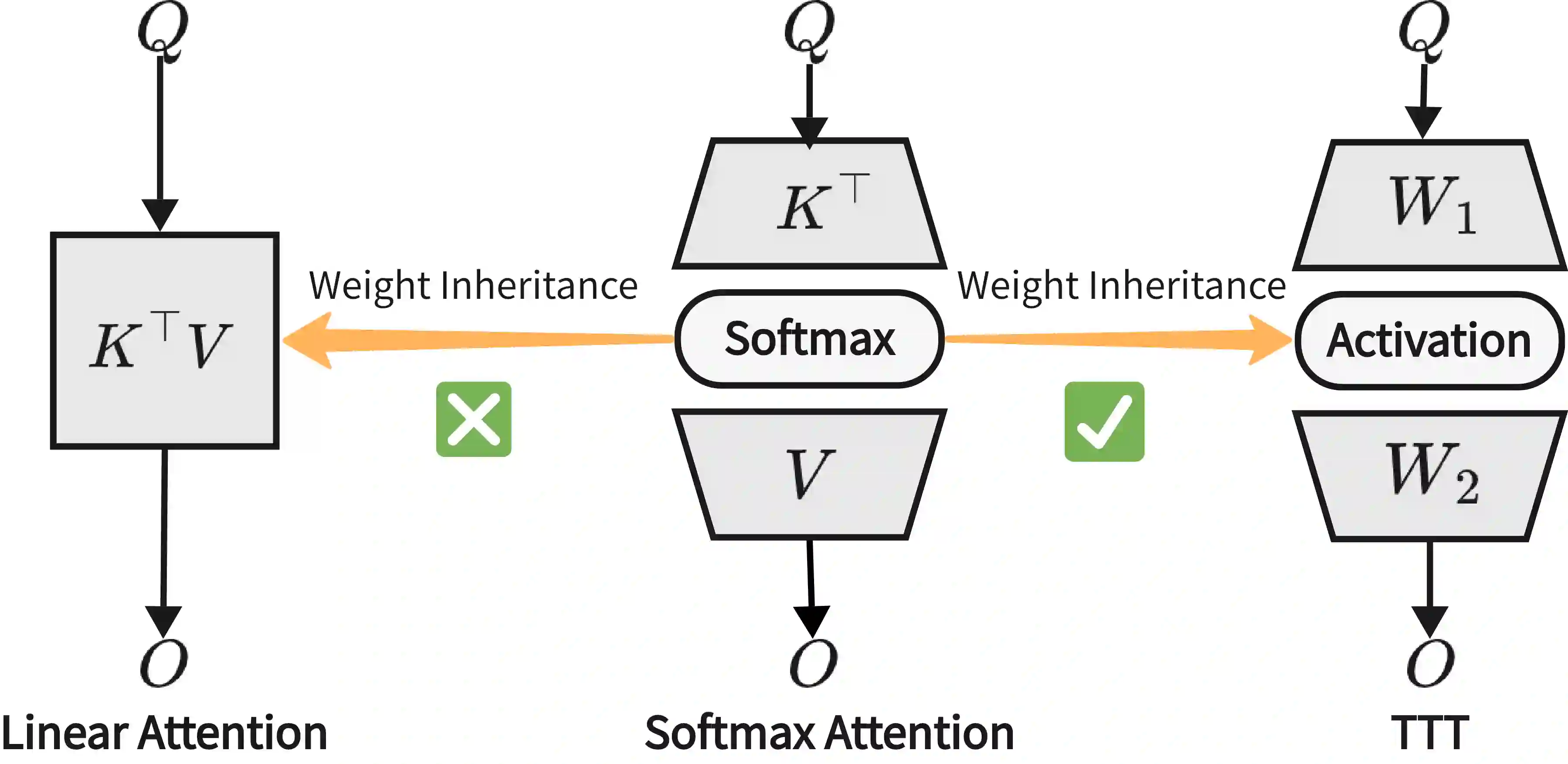
图2:Softmax Attention 与双层 TTT 的结构相似性,使得权重直接继承和快速适应成为可能
这一结构对等性使 TTT 可以直接继承预训练 Softmax 模型的全部权重(包括 Q/K/V/O 投影、MLP、归一化层等),而 TTT 内部的可学习参数(W1, W2)则提供了进一步的适应能力。
实验结果验证了这一设计:线性注意力在冻结预训练权重时 Top-1 仅 3.71%,而 TTT-SwiGLU 可达 67.33%,充分证明了 TTT 的结构兼容性。
2.2 表征对齐:解决 Key 偏移问题
即使结构兼容,直接继承权重后微调仍会出现训练发散(NaN)。原因是:
Softmax 对 Key 的偏移具有不变性——给所有 Key 加上相同的偏移向量 δ,注意力权重不变。而 TTT 不具备这种不变性。预训练模型中的 Key 存在显著的偏移(偏移比率 ≈0.5),这会导致 TTT 的梯度爆炸。
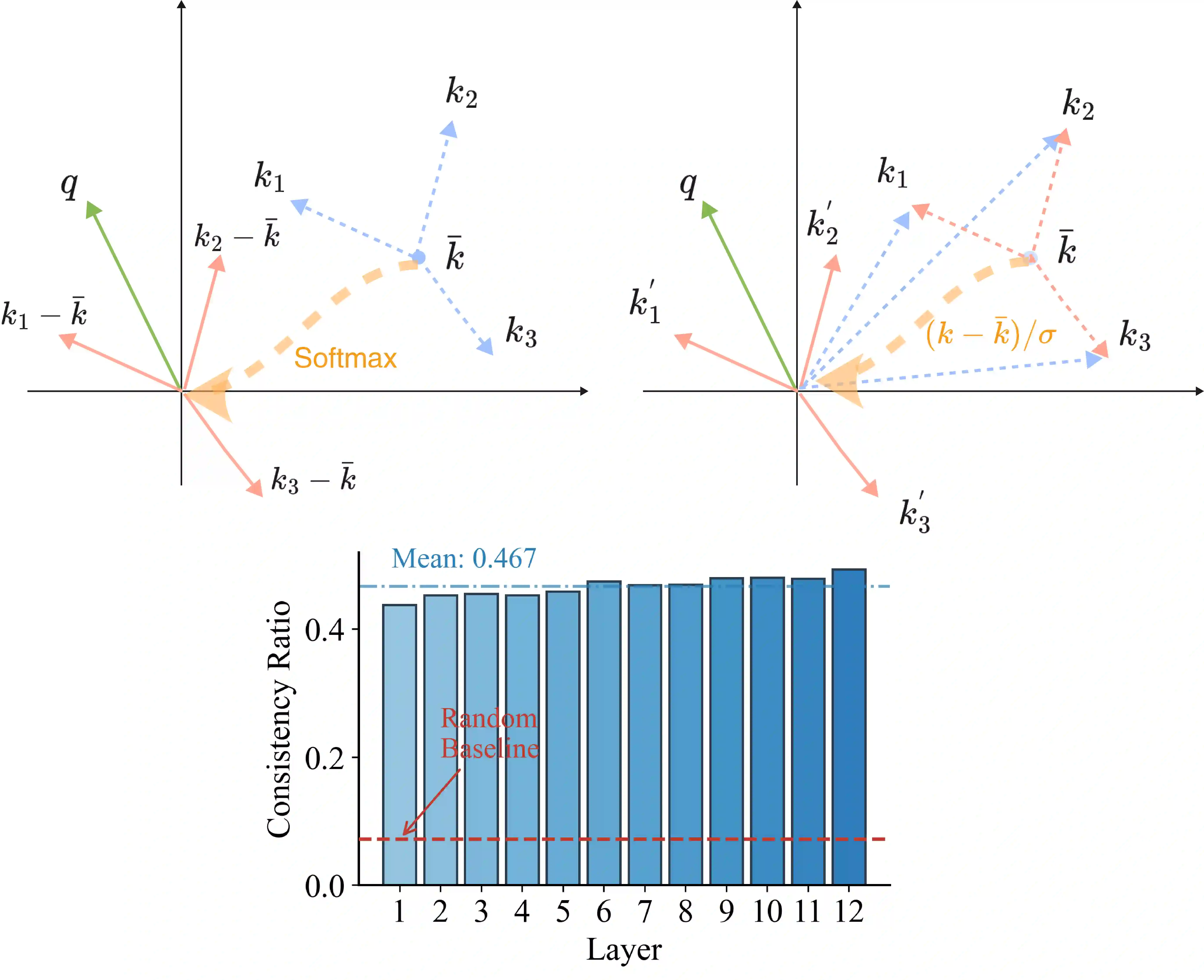
图3:Softmax 可吸收 Key 偏移而 TTT 不能;预训练 ViT 的 Key 偏移比率约 0.5,随机初始化仅 0.07
解决方案:在 TTT 计算前对 Key 应用实例归一化(Instance Normalization):
k̂_i = (k_i - k̄) / sqrt(1/N · Σ(k_j - k̄)² + ε)
该方法去除了 Key 的均值偏移,模拟 Softmax 的偏移不变性。实验表明,去掉均值减法的消融实验立即导致 NaN,而去掉标准差缩放则基本不影响精度。
2.3 表征对齐:增强局部性
Softmax 注意力天然具有强局部偏好——相邻 token 间的注意力权重更高。而 TTT 的隐式注意力图显示其全局建模能力更强,局部性偏弱。
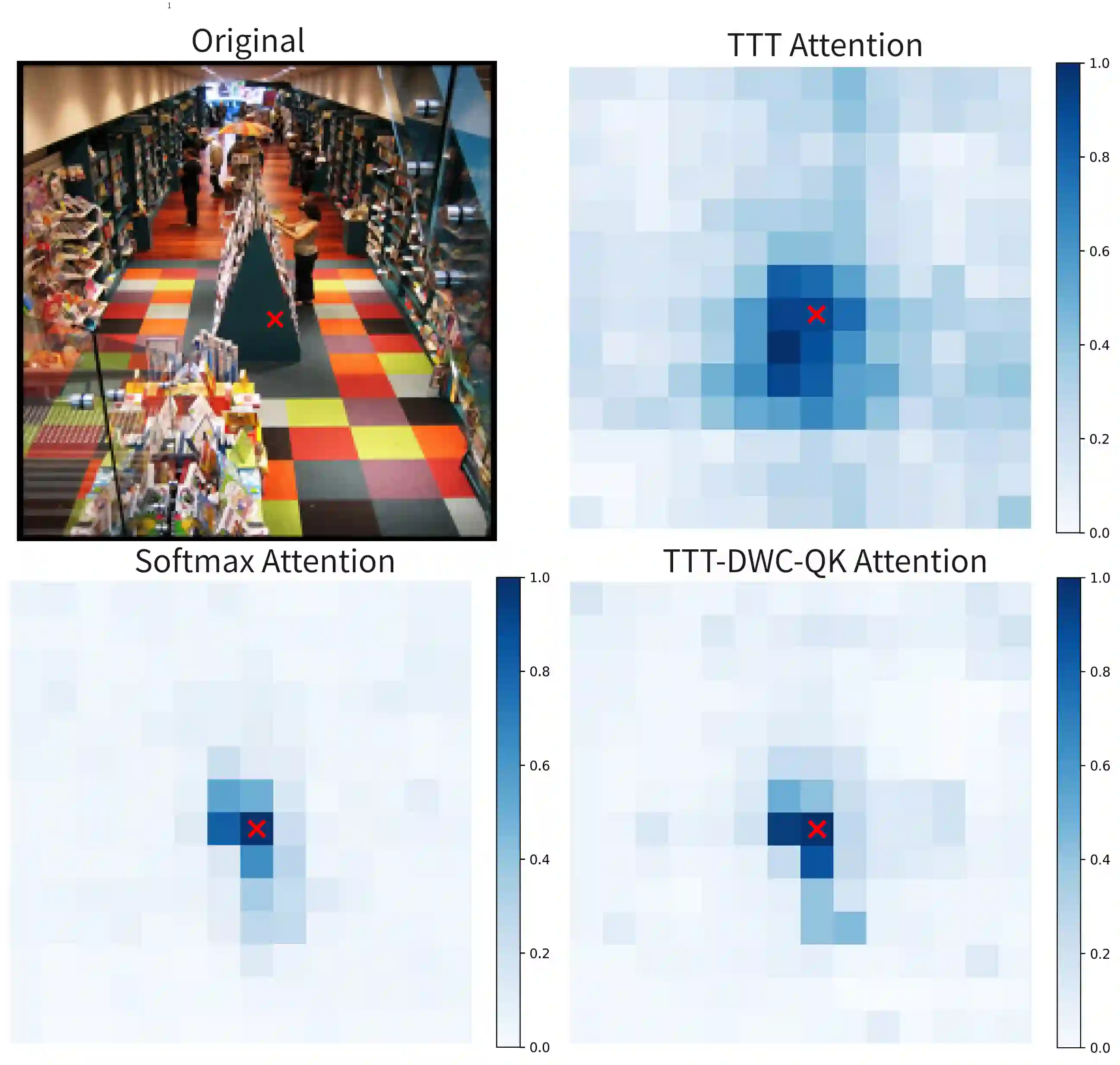
图4:隐式注意力分数可视化。Softmax 有强局部偏置,TTT 偏全局建模,DWCQK 增强了局部性
解决方案:在 Q 和 K 上应用深度可分离卷积(DWCQK):
q̂ = q + DWC(q), k̂ = k + DWC(k)
这直接注入了局部性先验,且当卷积后的 Key 用于 TTT 内部学习目标时,局部窗口的 Key 能联合预测 Value,扩大了感受野。
此外,TTT 还可选地与**邻域注意力(NAT)**结合,进一步提升局部建模能力。
3 实验验证
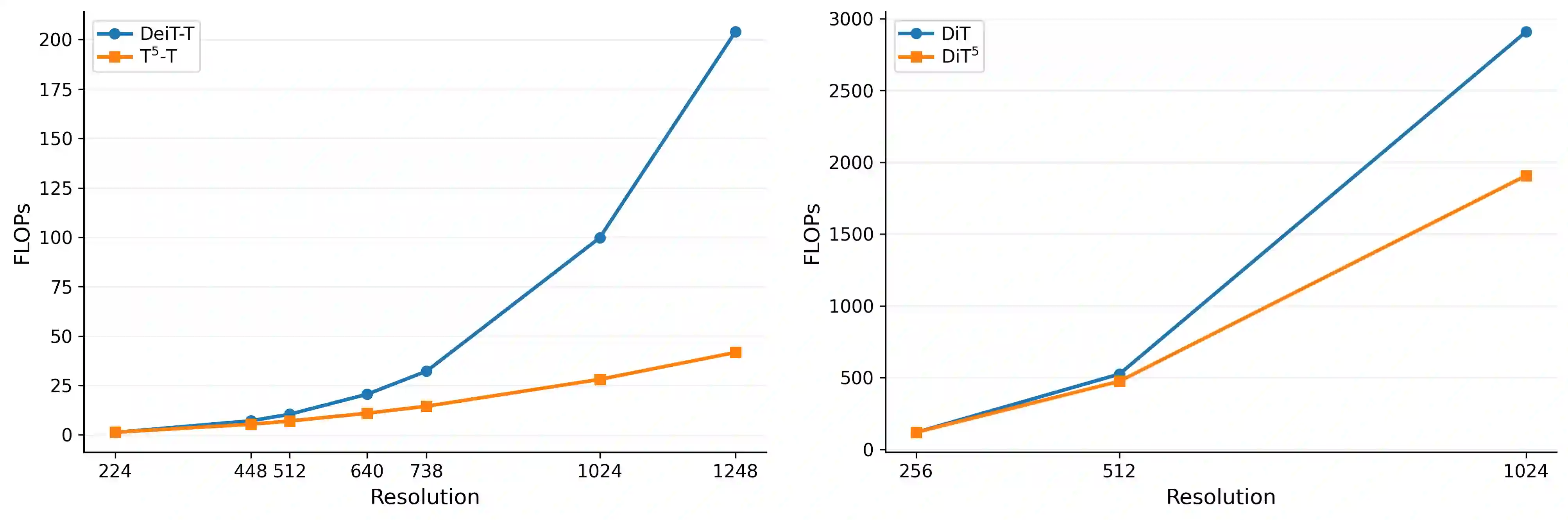
图5:不同分辨率下的 FLOPs 对比。T⁵ 的计算效率优势在高分辨率下更加明显
3.1 图像分类(ImageNet-1K)
在 DeiT-Tiny/Small 上,T⁵ 仅用 30 轮微调(10% 的训练量)即可恢复到接近基线的性能:
| 模型 | 训练轮数 | 比例 | Top-1 |
|---|---|---|---|
| DeiT-T† | 300 | 100% | 72.05 |
| T⁵-T | 30 | 10% | 71.19 |
| T⁵⁺-T | 30 | 10% | 72.06 |
对比其他线性化方法,T⁵ 在相同设置下显著优于标准线性注意力、LiT、CLEAR 和 Hedgehog。
3.2 类别条件图像生成(DiT-XL/2,256×256)
在 DiT-XL/2 上,T⁵(称为 DiT⁵)仅用 8 轮微调(0.57% 原始训练量) 即取得 FID 2.48 的优异成绩,无需蒸馏或复杂初始化策略:
| 模型 | 训练轮数 | 微调比例 | FID↓ | 蒸馏? |
|---|---|---|---|---|
| DiT-XL/2 | 1400 | - | 2.27 | - |
| DiT⁵-XL/2 | 8 | 0.57% | 2.48 | ✗ |
| LiT-XL/2 | 280 | 20% | 2.32 | ✓ |
| Hyena-Y | ~28† | 2% | 2.72 | ✗ |
3.3 文生图(Stable Diffusion 3.5-Medium)
这是本文最令人印象深刻的实验。将 SD3.5-Medium 中约 50% 的 Transformer 模块替换为 TTT 块,得到 SD3.5-T⁵:
- 训练成本:仅需 3000 步微调(约 1 小时,4×H20 GPU)
- 图像质量:DPG-Bench 上 84.43 vs 原始 83.83(甚至略有提升)
- 推理加速:1K 分辨率 1.32×,2K 分辨率 1.47×
| 方法 | DPG-Bench | GenEval | 延迟(1K) | 延迟(2K) |
|---|---|---|---|---|
| SD3.5-Medium | 83.83 | 0.66 | 25s | 231s |
| SD3.5-FT | 82.74 | 0.70 | 25s | 231s |
| SD3.5-T⁵ | 84.43 | 0.69 | 19s | 157s |
3.4 消融研究
- 权重继承策略:全部继承远优于仅继承 MLP 或仅继承注意力权重
- TTT 参数学习率:新初始化参数需要更高的学习率(20× 基学习率)
- NAT 的作用:NAT 是可选增强而非核心组件,在文生图实验中完全可省略
4 总结与展望
本文的核心贡献在于从结构角度解决了 Transformer 线性化的难题。T⁵ 通过利用 TTT 与 Softmax 注意力之间的天然结构对等性,实现了:
- 完全权重继承——无需蒸馏或多阶段训练
- 极低微调成本——在 SD3.5 上仅需 1 小时
- 显著推理加速——高分辨率下可达 1.47×
这一工作的意义不仅在于提供了一个高效的线性化方案,更在于揭示了 Softmax 注意力与 TTT 之间深层结构联系的见解——为未来大规模模型的高效部署提供了新的思路。
由专知整理,原文发表于 ICML 2026,作者单位:清华大学
