
【AAAI 2026】Two Heads are Better than One:将大模型做市能力拆解蒸馏给小模型
论文标题: Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture
作者: Tianhao Fu, Xinxin Xu, Weichen Xu, Jue Chen, Ruilong Ren, Bowen Deng, Xinyu Zhao, Jian Cao, Xixin Cao
机构/会议信息: arXiv 最新 v3 版本 comment 标注为 accepted by AAAI2026。本文整理基于 arXiv 提供的 v2 HTML 正文与图表,摘要页显示最新版本为 2026-01-29 的 v3。
论文链接: https://arxiv.org/abs/2511.07110v3
HTML 正文来源: https://arxiv.org/html/2511.07110v2
一句话导读
这篇论文关注一个很现实的问题:大语言模型在金融做市任务上可能具备强大的市场理解能力,但推理速度太慢,无法直接用于低延迟交易。作者提出 Cooperative Market Making(CMM),把 LLM 的复杂特征按 层、任务、数据类型 三个正交维度拆开,让多个轻量学生模型分别学习不同“局部能力”,再通过 Hájek-MoE 动态融合专家输出,最终在真实市场数据上获得比传统 RL、普通蒸馏和标准 MoE 更好的收益、风险控制和延迟表现。
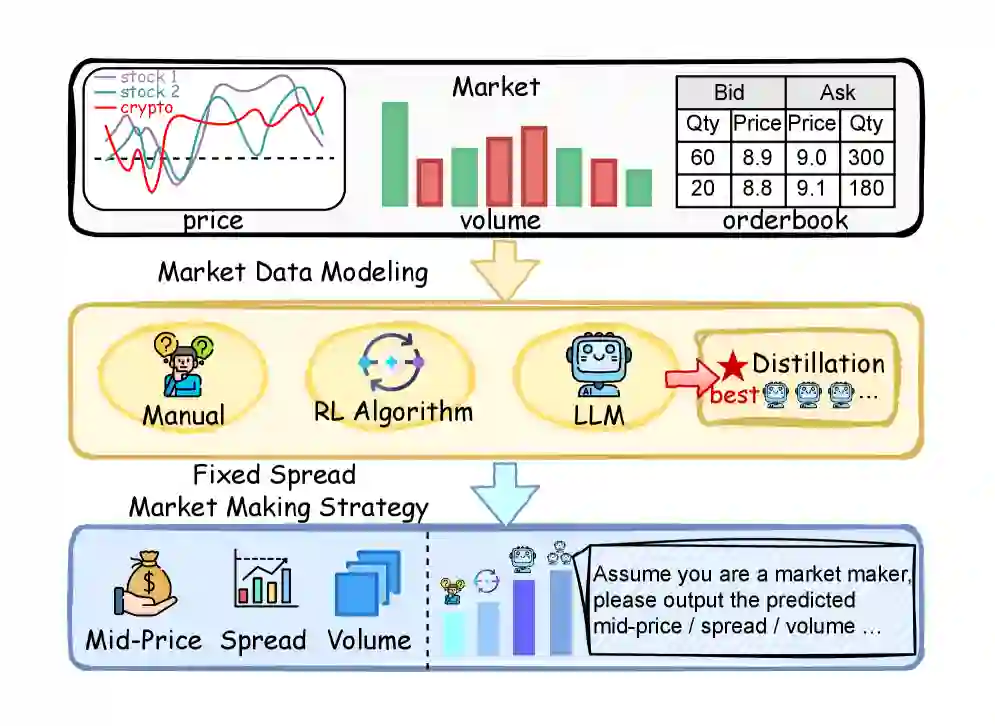
背景:LLM 会做市,但太慢
做市的核心目标是在买卖盘之间持续提供流动性,同时控制库存风险并追求收益。传统方法主要依赖规则、随机控制或强化学习;而作者发现,直接让 Gemini-2.5-Pro、Llama-3.1 等 LLM 根据历史市场状态预测未来中间价、价差和交易量,再构造下单策略,已经能超过若干传统 RL 方法。
问题也很明显:LLM 推理延迟高,实时交易场景通常要求亚秒级甚至更低延迟。直接部署大模型并不现实。普通知识蒸馏也不够,因为单个小模型很难承接 LLM 深层、高维、纠缠的金融表征。论文的核心判断是:不是把整个 LLM 一口气压进一个小模型,而是先拆,再分工学习,再协同融合。
方法总览:CMM 的三段式思路
CMM 的整体框架可以理解为三步:
- 先探测 LLM 特征如何组织。 作者提出 Normalized Fluorescent Probe,用归一化探针观察 LLM 的隐藏特征在不同层、不同任务、不同市场数据类型下是否能被分离。
- 再做正交特征分解蒸馏。 将 LLM 知识沿 layer、task、data type 三个维度拆解,不同学生模型只负责一类更简单、更可学习的特征。
- 最后用 Hájek-MoE 做动态融合。 每个学生模型输出自己的预测,融合模块在核函数生成的公共特征空间中估计不同专家的贡献权重,得到最终做市决策。
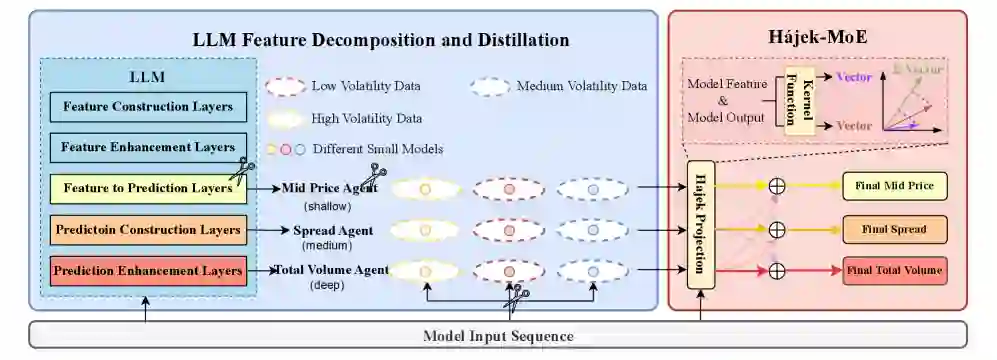
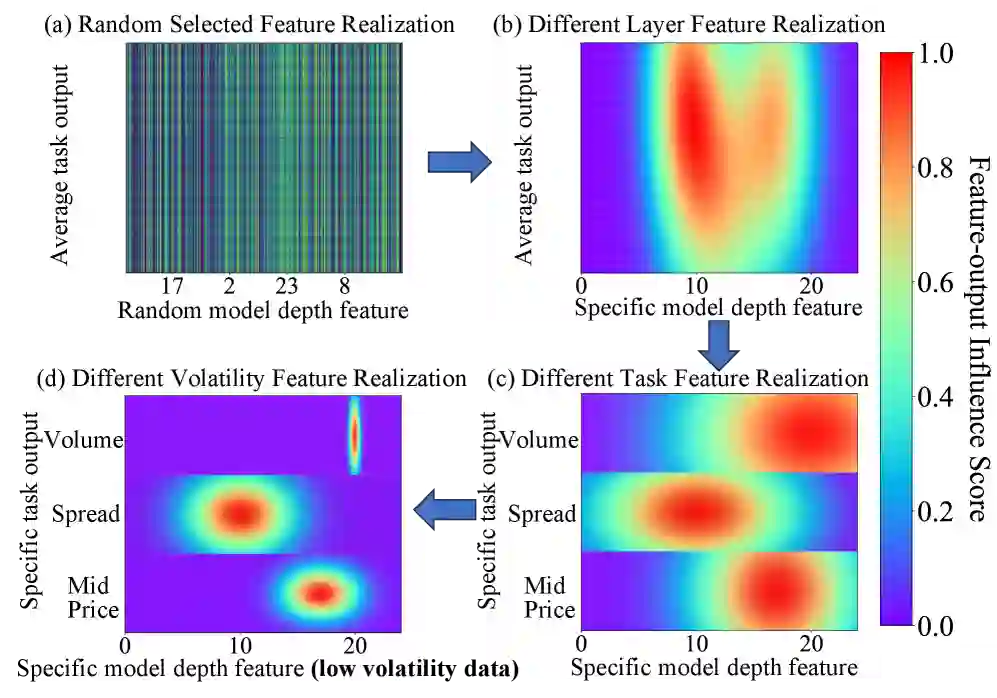
Normalized Fluorescent Probe:为什么要按三维拆解
论文并不是直接假设“多专家一定更好”,而是先用探针分析 LLM 内部表征。实验观察到两个现象:
- 解耦条件越强,LLM 特征簇之间的分离越明显,说明复杂特征确实可以被拆成更简单的子结构。
- 不同深度层存在任务偏好:浅层更偏向中间价预测,中层更关注价差,深层更适合总量预测。
这解释了为什么单个小模型难以完整学习 LLM 表征:它要同时拟合不同层级、不同任务、不同市场状态下的多种规律。CMM 因此将“蒸馏”改造成“分解式协作蒸馏”。
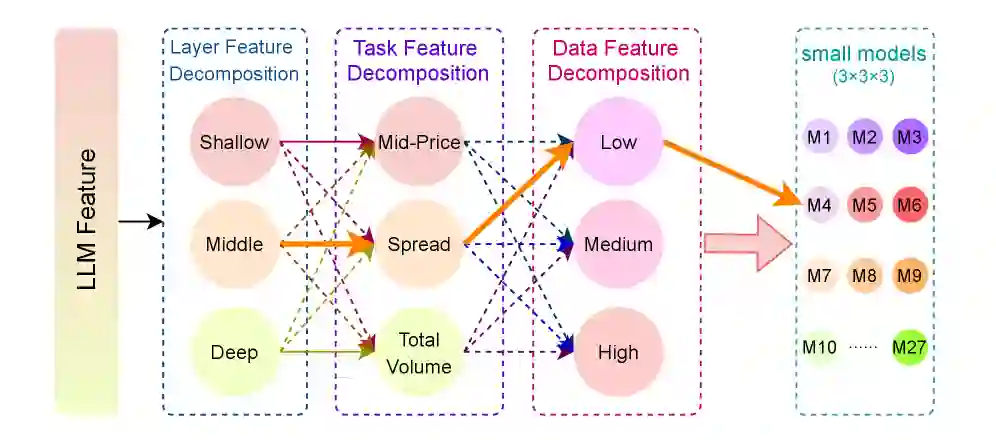
正交特征分解蒸馏:让小模型各司其职
论文提出 Orthogonal Feature Decomposition Distillation(OFDD),把学生模型分配到三个拆解维度:
- Layer Feature Decomposition: 不同学生模型学习 LLM 不同层的表示。
- Task Feature Decomposition: 分别面向中间价、价差、成交量等任务特征。
- Data/Market Type Feature Decomposition: 按不同市场类型或数据状态训练专家,让模型对牛市、熊市、震荡市等环境更敏感。
这种设计的好处是降低每个学生模型的学习难度。每个小模型只负责一块相对“干净”的特征空间,最后通过融合模块把这些能力重新组合成完整的做市策略。
Hájek-MoE:不是静态投票,而是按输入动态分配专家权重
标准 MoE 常见问题是专家融合比较静态,容易在极端行情下给错权重。CMM 的 Hájek-MoE 会把各学生模型的特征和输出映射到公共特征空间,利用核函数估计每个专家在当前输入上的置信贡献,再做加权聚合。
这意味着模型在平稳行情下可以偏向收益专家,在波动行情下可以更重视风险控制专家。论文后续鲁棒性实验也指出,在闪崩和快速反转等极端情境中,CMM 的动态专家置信机制能更好地平衡收益与风险。
实验结果:收益、风险和延迟同时改善
论文在四个真实市场数据集 RB、FU、CU、AG 上评估 CMM。指标包括:
- EPnL: 预期收益,越高越好。
- MAP: 库存偏离/风险相关指标,越低越好。
- PnLMAP: 收益与风险综合指标,越高越好。
- SR: Sharpe Ratio,越高越好。
- Latency: 推理延迟,越低越好。
整体结果显示,CMM 在四个市场数据集上都优于多数传统做市方法。以 FU 数据集为例,CMM 达到 EPnL 31.39±4.18、MAP 32±2、PnLMAP 298±19,明显优于 IMM 的 28.10±10.27、102±14、274±89。
在与不同蒸馏方法和 MoE 方法对比时,CMM 取得 31.39 EPnL,相比 LLM-Base 的 30.47 还略有提升,同时延迟从 LLM-Base 的 1.9s 降到 0.3s,约为 6.3× 更低延迟。普通蒸馏方法如 ReviewKD、Sim-KD、CAT-KD 虽然延迟低,但收益和风险指标显著退化;X-MoE、MH-MoE 的融合方式也没有达到 CMM 的风险控制效果。
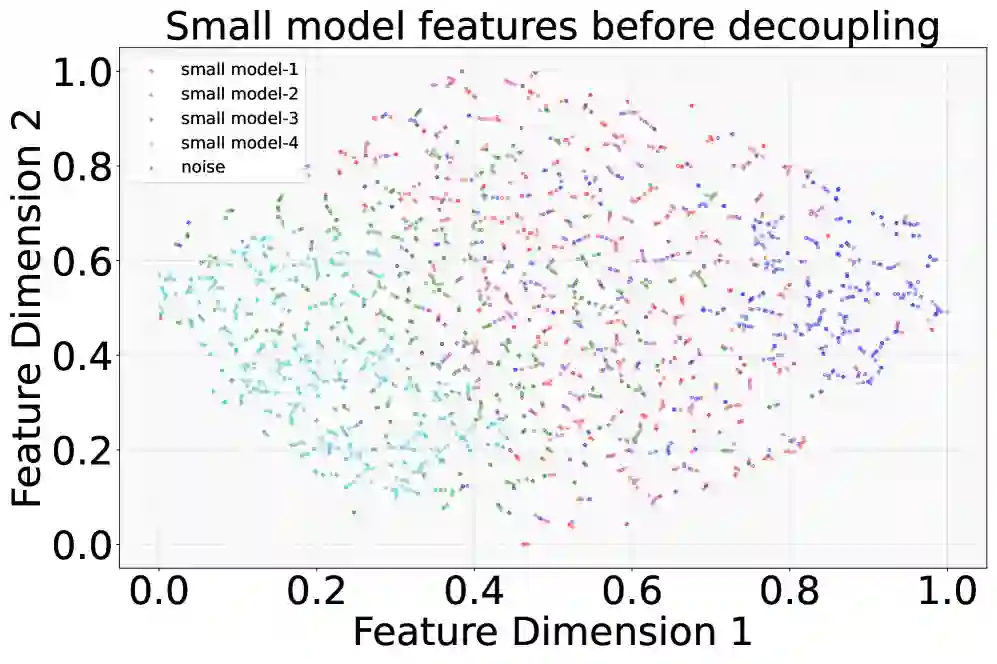
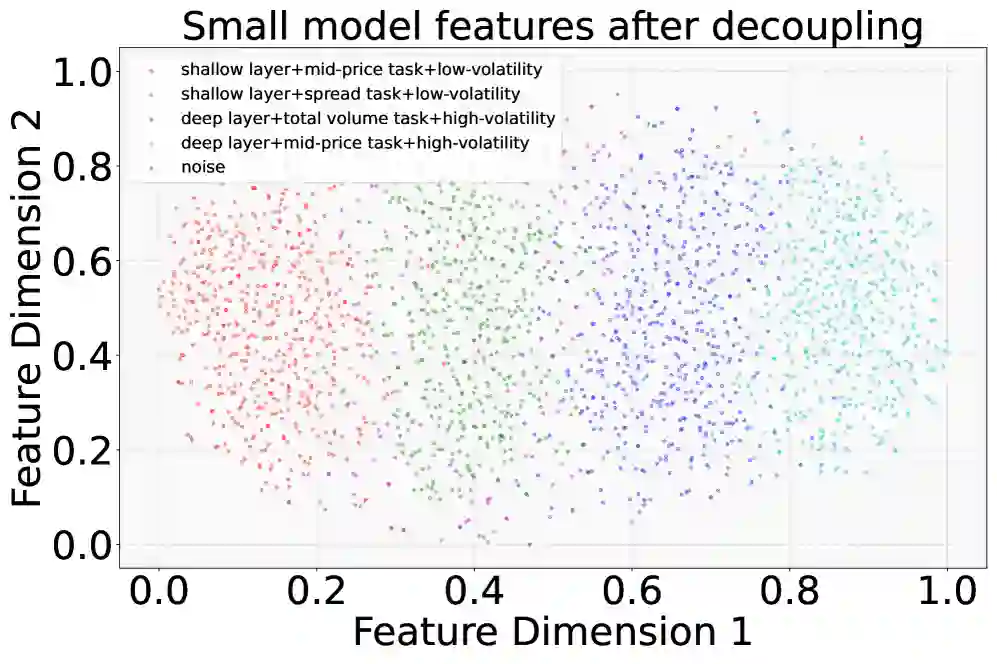
消融实验:三种分解和 Hájek-MoE 都有贡献
在 FU 数据集上的消融结果显示:
- 只做 layer 分解:EPnL 12.54,MAP 67,PnLMAP 162。
- 只做 task 分解:EPnL 17.25,MAP 58,PnLMAP 195。
- 只做 market type 分解:EPnL 22.41,MAP 45,PnLMAP 241。
- 完整 CMM 加 Hájek-MoE:EPnL 31.39,MAP 32,PnLMAP 298。
这说明三个分解维度不是装饰性的模块,而是逐步把复杂 LLM 特征变成小模型可学习对象;Hájek-MoE 则负责把这些专家能力在推理阶段动态组合起来。
低数据、极端市场和能耗测试
论文还考察了几个更接近真实部署的问题:
- 极端行情: 在模拟闪崩和快速反转数据中,CMM 相比 LLM-Base 与 IMM 获得更高风险调整收益,说明动态专家融合有助于市场压力下的风险控制。
- 长期适应: 在一周多市场状态测试中,CMM 在盈利、风险控制和效率上优于 LLM-Base 与 IMM,表明市场类型分解有助于跨行情泛化。
- 低数据条件: 仅使用 10%、20%、50% 训练数据时,CMM 都持续优于基线;例如 10% 数据下,CMM 的 EPnL 为 4.50,MAP 为 35,PnLMAP 为 1.29。
- 能耗与延迟: CMM 的功耗约 45W、推理延迟约 20ms,低于 LLM-Base 的 150W/120ms 和 IMM 的 90W/80ms。
专知分析
这篇论文的价值不只在“把 LLM 用到金融做市”,更在于提出了一种面向复杂决策任务的蒸馏范式:当教师模型的能力不是单一技能,而是由多层、多任务、多数据状态共同形成时,蒸馏目标也应该被结构化拆开。
对金融 AI 来说,这一点尤其重要。交易任务通常同时包含预测、风险控制、执行成本、库存约束与市场状态识别。单个端到端小模型可能很难稳定继承大模型的隐含知识;CMM 则把大模型当成“可解析的复杂特征源”,通过探针先看清结构,再把结构转移给多个轻量专家。
当然,论文仍需要进一步验证真实交易部署中的交易成本、滑点、监管约束和市场冲击等因素。但从方法角度看,它给出了一个很有启发性的方向:LLM 不一定要直接上场交易,它也可以作为高质量教师,把复杂市场表征拆解并传授给更快、更便宜、更可部署的小模型。
参考
Fu et al. Two Heads are Better than One: Distilling Large Language Model Features Into Small Models with Feature Decomposition and Mixture. arXiv:2511.07110. Comment in latest arXiv v3: accepted by AAAI2026.