
综述 | 世界动作模型:少做梦,多行动
论文标题:World Action Models: A Survey 副标题:Dream Less, Act More 作者:Qiuhong Shen、Shihua Zhang、Yue Liao、Qi Li、Zhenxiong Tan、Shizun Wang、Shuicheng Yan、Xinchao Wang 机构:National University of Singapore 论文链接:https://arxiv.org/abs/2606.20781 项目主页:https://world-action-models.github.io/

图1:论文首页摘要。作者将 World Action Models 定义为“让预测未来进入行动路径”的具身预测-行动模型。
导读
近两年,具身智能和机器人学习正在从“看见当前状态后直接输出动作”,走向“先预测未来,再决定如何行动”。RT-2、OpenVLA、π0 等 Vision-Language-Action 模型证明了大规模视觉语言预训练可以迁移到机器人控制,但标准 VLA 仍然缺少一个关键能力:它通常不显式建模自己的动作会如何改变世界。 这篇 57 页综述提出并系统梳理 World Action Models,简称 WAMs。作者认为,WAM 不是“视频生成模型加一个动作头”这么简单,而是一类让未来预测真正服务于行动的模型。它可以生成像素级未来,也可以只预测潜空间、特征、几何、可供性图,甚至完全不使用视频生成骨干;关键是这个未来必须参与动作生成、动作评分、动作验证或行动路径训练。 文章的主线很清晰:先划清 VLA、World Model、Video World Model 与 WAM 的边界,再用“三种设计哲学”和“四轴解剖”组织现有工作,最后讨论交互性、因果性、持久性、物理合理性、泛化、数据评测与开放挑战。核心判断可以概括为一句话:未来的趋势不是把未来生成得更完整,而是在保留控制所需信息的前提下,生成得更少、更快、更可行动。
1. Introduction | 引言
具身 AI 的长期目标,是让智能体在非结构化物理环境中感知、推理并行动。过去两年,研究重点从纯反应式策略转向带有预测组件的策略:智能体不仅根据当前观测和语言指令输出动作,还要提前估计环境可能如何变化。 标准 VLA 的形式可以理解为从当前观测和指令直接预测动作。它继承了视觉语言模型的语义知识,却没有明确回答“执行这个动作之后会发生什么”。这会限制模型在接触、遮挡、视角变化、物理约束和长程任务中的后果推理能力。 WAM 的出现正是为了解决这个缺口。作者指出,已有工作已经形成三条流派:第一类把视频生成进行到像素级,再从渲染未来中解码动作;第二类保留视频世界模型的动态先验,但在像素解码前停止,只使用潜变量、流场、掩码或特征;第三类完全放弃视频生成核心,在语言 token、音频、联合嵌入或结构化表示中预测未来。虽然实现差异很大,它们共享同一个契约:预测出的未来必须面向行动。
2. The Emergence of World Action Models | 世界动作模型的兴起
概念边界
论文首先区分四类概念。VLA 模型直接建模动作,不必显式预测未来;世界模型预测未来状态或观测,但不一定选择动作;视频生成模型学习从提示或条件生成视频;视频世界模型进一步把动作作为条件,预测动作导致的视觉未来。 WAM 位于这些概念的交叉处,但边界更严格:它要求预测未来留在行动路径中。这个未来可以用于生成动作、评分候选动作、验证动作后果,也可以在联合模型中训练动作分支。若一个模型只在训练中使用辅助未来损失,而推理时完全丢弃未来分支,就不能算作 WAM。
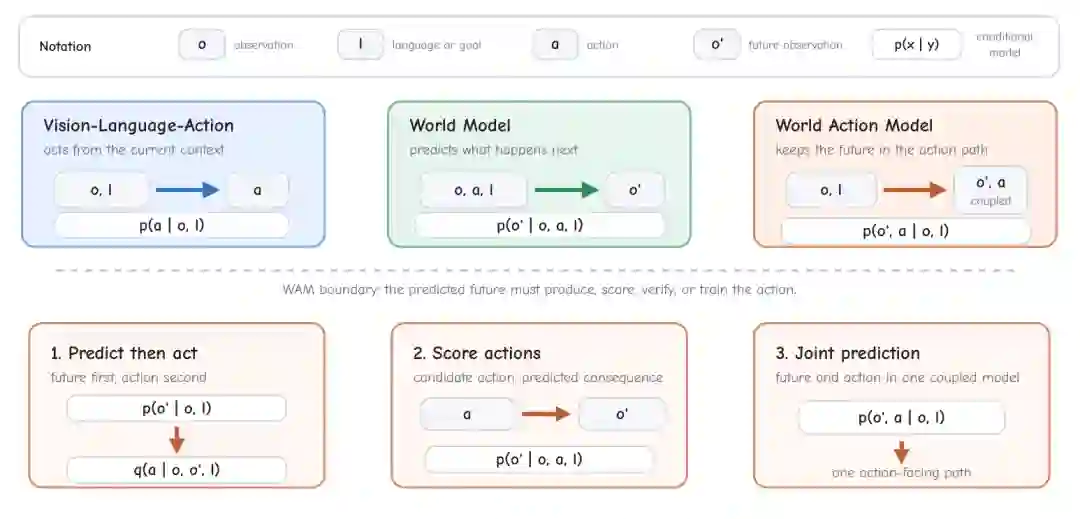
图2:WAM 的定义边界。VLA 直接从当前上下文预测动作,世界模型预测未来,WAM 则要求预测未来继续参与动作路径。
三种行动路径
作者将 WAM 的未来-行动关系概括为三种形式。第一种是“先预测再行动”:模型先生成未来观测,再由逆动力学、轨迹优化器、规划器或单独策略从未来中恢复动作。第二种是“先给候选动作再预测后果”:动作源提出候选动作,世界模型预测其后果,再选择最优动作。第三种是“联合预测”:同一个模型或紧耦合专家同时预测未来与动作。 这一定义很重要,因为它避免把 WAM 简化为视频生成分支。视频生成只是实现预测未来的一种方式,而不是 WAM 的必要条件。
3. Three Design Philosophies of World Action Models | 三种设计哲学
渲染后解码
Render-and-Decode 是最直接的路径:模型把未来生成到像素或接近像素的形式,再从渲染未来中解码动作。这类方法保留完整视觉外观、运动、接触和场景动态,解释性强,也便于人类检查生成质量。UniPi、VLP、AVDC 以及后续视频规划方法都属于这一方向。 代价也很明显:全像素未来昂贵,控制闭环中的延迟高,动作模块还必须把“看起来合理”的视频转换成可执行轨迹。对于真实机器人来说,视觉合理并不等于动作可执行。
仅使用潜空间
Latent-Only 保留视频模型学到的时空和物理先验,但不把未来完整解码成像素。模型可以截取中间去噪特征、视频潜变量、光流、语义掩码、轨迹或其他视频派生表示,再让动作模块消费这些表示。 这一类方法的优势是节省计算和内存,更适合实时控制;缺点是可解释性弱于像素生成,评估也不能只看视频质量,而必须看下游动作是否更好。
无视频生成
Video-Generation-Free 进一步移除视频生成骨干。它可以基于 LLM、VLM、JEPA、非视频扩散、确定性特征回归或混合架构,让模型预测紧凑的未来表示。这些表示可能是未来特征、语言 token、音频 latent、几何变量、可供性图或任务相关分数场。 这类方法体现了论文标题“Dream Less, Act More”的精神:如果行动只需要某些紧凑未来变量,就没有必要生成完整视频。控制系统真正关心的是可行动信息,而不是视觉逼真度。
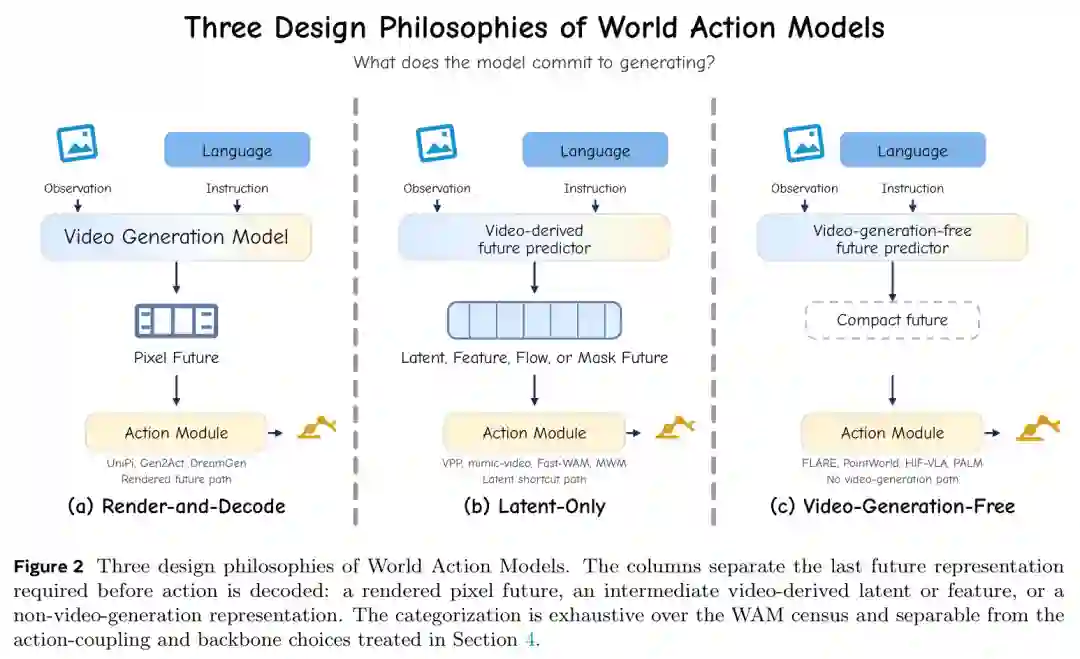
图3:WAM 的三种设计哲学:生成像素未来、停在潜空间未来、或完全不使用视频生成核心。
发展时间线
从时间线上看,早期 WAM 多从视频生成走向控制,先生成可视未来,再从中恢复动作。随后 Latent-Only 方法开始把动作路径提前到潜空间或中间特征中。到 2025 年末和 2026 年,Video-Generation-Free 方法快速增多,LLM、VLM、JEPA 和非视频扩散等骨干开始承担预测组件。
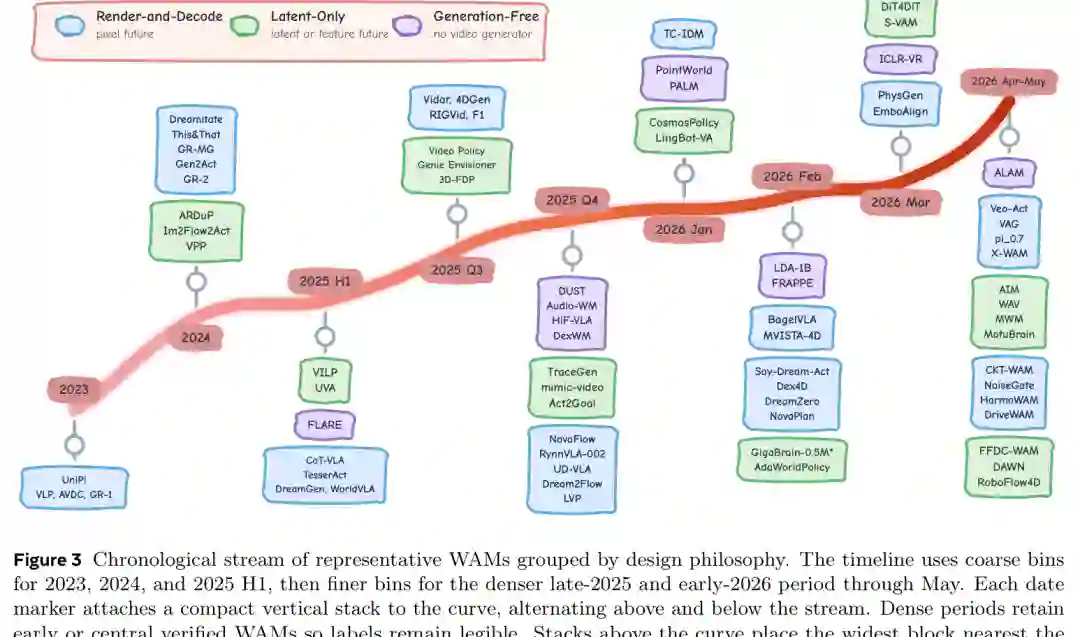
图4:代表性 WAM 工作时间线。早期以渲染未来为主,后续逐渐转向潜空间与非视频生成路径。
4. What Makes a World Action Model | 世界动作模型的四轴解剖
统一表示
论文提出一个统一抽象:WAM 可以看作一个条件联合分布,输入过去观测、过去动作和任务指令,输出未来预测基座和未来动作窗口。这里的关键不是某个单一网络结构,而是四个可分离但相互作用的选择:预测基座、动作耦合、架构骨干和部署形态。
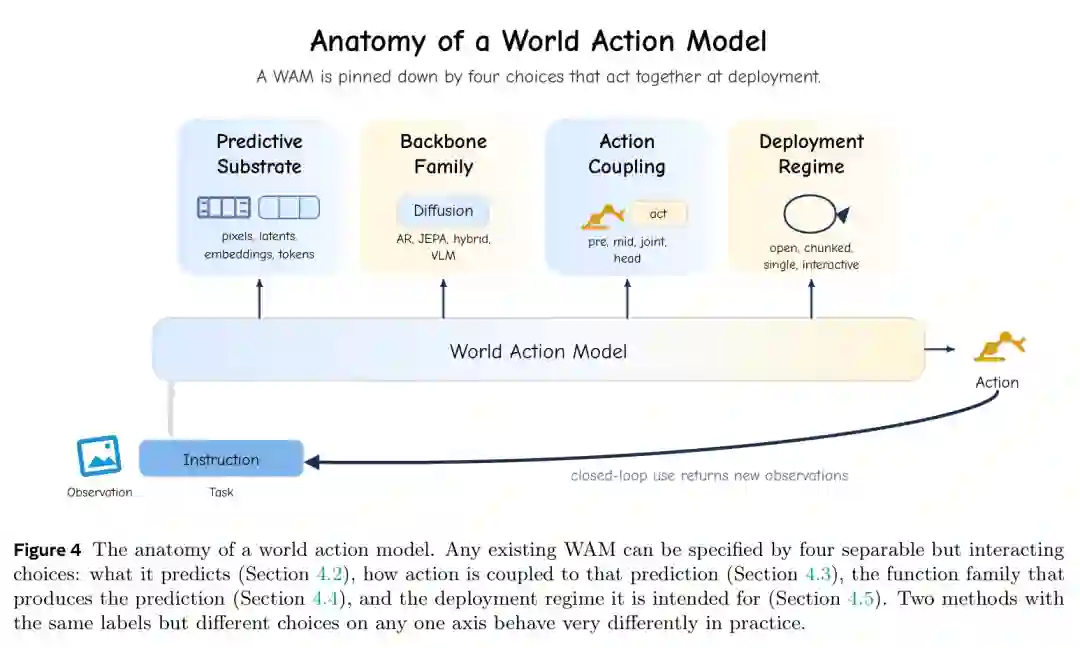
图5:WAM 的四轴解剖。一个 WAM 可以由预测基座、架构骨干、动作耦合和部署形态共同刻画。
预测基座
预测基座回答“动作路径消费什么样的未来”。论文把它分为四类。第一类是像素基座,包括解码视频和可解码像素 latent;第二类是特征基座,包括 encoder-only 特征、feature-tap、teacher-target、VLM token;第三类是几何基座,包括流、轨迹、深度、姿态、点云、运动向量;第四类是可供性基座,包括价值图、掩码、进度图、末端执行器热力图等。 这个分类比“是否生成视频”更细,因为同样是视频模型,可能输出像素、潜变量、特征或几何;同样是非视频方法,也可能预测 affordance 或 token。
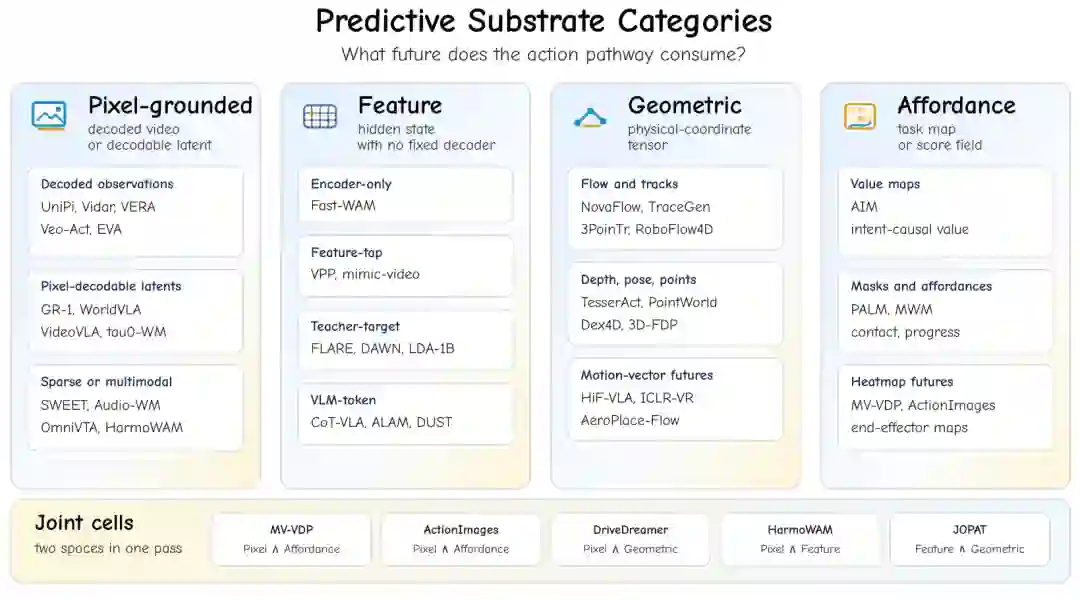
图6:四类预测基座:像素、特征、几何和可供性。它们决定动作模块最终消费什么形式的未来。
动作耦合
动作耦合回答“动作如何进入预测,又如何从预测中出来”。论文归纳出三类:动作条件 rollout、联合生成、后预测动作头。 动作条件 rollout 中,外部动作源先给出候选动作,世界预测器评估其后果;联合生成中,同一骨干同时预测未来和动作;后预测动作头中,模型先预测未来基座,再用动作头从未来状态中解码动作。三者的差异会直接影响延迟、可控性和逐步推理成本。
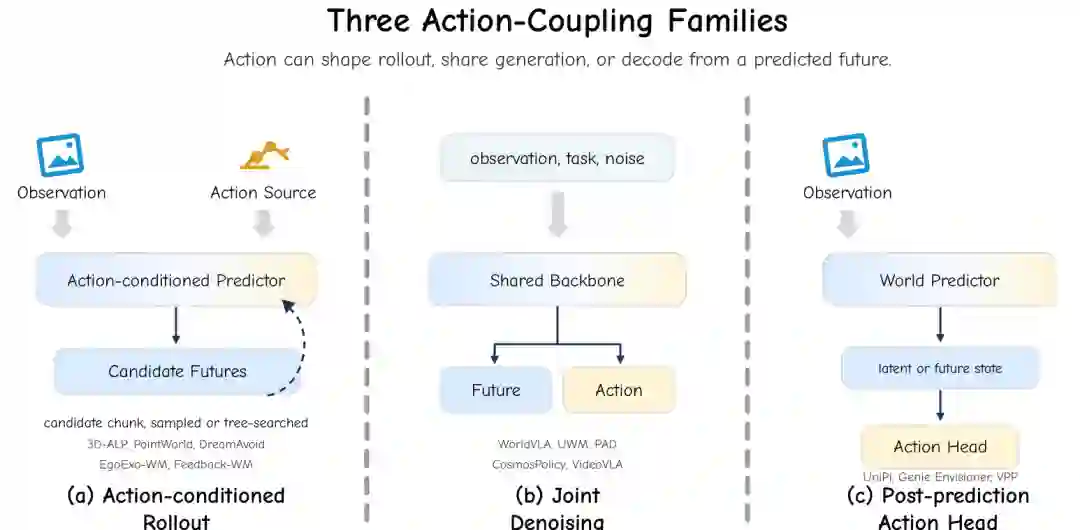
图7:三类动作耦合方式:动作条件 rollout、联合去噪生成、后预测动作头。
架构骨干与部署形态
架构骨干包括视频扩散、next-frame 或 next-token 自回归、JEPA 式联合嵌入预测、生成头加动作头的混合架构,以及 LLM/VLM 骨干。扩散模型表达力强,但多步去噪带来延迟;自回归便于缓存,但序列长度决定实时性;JEPA 不解码图像,推理便宜,但难以用视觉质量直接评估;LLM/VLM 骨干语义强,但需要把抽象 token 与物理动作对齐。 部署形态则决定模型能否进入真实控制环。开放环 rollout 适合生成完整计划,但容易累积误差;chunked closed-loop 每隔若干步重规划,平衡计算与反馈;single-step closed-loop 每一步都更新,反应更快但计算压力最大;interactive simulator operation 则把 WAM 当作交互式世界模拟器或训练环境使用。
5. Core Properties of World Action Models | 核心性质
可交互性
WAM 的预测必须能被动作改变。一个只会播放无条件未来的视频生成器不是 WAM;只有当行动能影响预测路径,预测结果又能反过来指导行动时,模型才具备可交互性。
因果性
行动模型不能只学习相关性,还需要表达“如果执行某动作,世界会怎样变化”。这要求模型区分环境自然变化和动作造成的变化,尤其在机器人接触、抓取、导航和驾驶中,因果混淆会直接导致错误动作。
持久性
物体、状态和任务约束需要在长程预测中保持一致。若模型每一步都生成局部合理但全局不连贯的未来,控制策略会在执行中失去稳定参照。持久性涉及记忆、状态跟踪和长时程一致性。
物理合理性
对具身系统而言,视觉真实不等于物理可执行。WAM 需要尊重接触、碰撞、重力、可达性、动力学约束和执行器限制。论文强调,物理合理性应该通过行动成功率、约束违反率和闭环表现检验,而不是只依赖生成视频的感知质量。
泛化能力
WAM 需要跨对象、场景、任务、机器人形态和感知模态泛化。视频生成预训练带来丰富动态先验,但不同机器人平台的动作空间、控制频率和观测形式差异巨大。未来模型能否从通用视觉动态迁移到具体控制,是该领域的关键问题。
6. Data and Evaluation | 数据与评测
数据来源
WAM 的数据需求复杂,因为不同阶段可能需要不同数据。视频生成或未来预测阶段可以利用互联网视频、机器人视频、模拟器轨迹、多视角数据、接触和触觉数据;动作耦合阶段则需要动作标签、示教轨迹、候选动作结果或交互反馈。 论文指出,一个稳定趋势是:越接近真实控制,数据越昂贵。像素级未来可以从大规模视频中学习,但动作对齐和闭环执行往往需要机器人数据或仿真交互数据。如何让各阶段使用合适数据,是 WAM 扩展的核心工程问题。
评测指标
WAM 不能只用 FVD、视频清晰度或预测误差评估。真正重要的是预测是否改善行动。评测应报告任务成功率、闭环稳定性、动作延迟、重规划成本、内存占用、因果敏感性、物理约束违反、跨域泛化和长程一致性。 作者特别强调,评价要把“未来质量”和“行动质量”连接起来。一个未来看起来不完美,但保留了控制所需信息,可能比一个逼真但不可行动的视频更有价值。
7. Open Challenges | 开放挑战
该多做梦还是多行动
最核心的权衡是生成多少未来。渲染更多未来带来可解释性和丰富表征,但消耗计算、内存和延迟;生成更少未来更适合控制,却可能丢失关键物理线索。未来 WAM 需要学会按任务动态决定预测粒度。
各阶段应该学什么数据
未来预测、动作耦合和闭环控制可能需要不同数据分布。互联网视频适合学习视觉动态,机器人轨迹适合动作对齐,仿真环境适合大量交互。如何把这些数据源组合起来,仍然缺少统一范式。
记忆能否跟上
长程任务需要持久记忆,而视频或 token 序列会迅速膨胀。模型必须在压缩历史、保留关键状态和实时推理之间折中。记忆不仅是上下文长度问题,也是状态抽象问题。
如何泛化
WAM 要面对不同机器人、不同场景、不同任务语言和不同物理条件。泛化不能只看离线预测,还要看闭环执行是否稳健。跨具身形态的动作表示和跨域动态迁移,是未来关键方向。
抽象动作如何落地
很多 WAM 在高层计划、视觉轨迹或 affordance 图上预测未来,但真实机器人需要低层控制。如何把抽象动作稳定映射到可执行控制,并在失败时修正,是部署中的难点。
什么样的未来才算物理
模型可能生成视觉上合理但物理上不可能的未来。该领域需要更强的物理约束、接触建模和可执行性验证,也需要能检测“行动上不可用未来”的评测协议。
评测应该报告什么
作者呼吁评测不只报告任务成功率,还应报告延迟、显存、动作标签成本、重规划频率、未来基座类型和闭环控制设置。否则不同 WAM 看似同名,实际部署代价可能完全不同。
8. Conclusion | 结论
这篇综述给 World Action Models 提供了一个清晰定义:WAM 是让预测未来进入行动路径的具身预测-行动模型。它不同于普通 VLA,也不同于单纯世界模型或视频生成模型;它的关键在于未来必须服务于动作生成、动作评分、动作验证或动作训练。 论文的两套组织框架尤其有价值。第一套是三种设计哲学:Render-and-Decode、Latent-Only、Video-Generation-Free;第二套是四轴解剖:预测基座、架构骨干、动作耦合、部署形态。前者帮助读者理解“模型承诺生成什么”,后者帮助研究者比较“模型如何把未来变成行动”。 从整体趋势看,WAM 领域正在从“生成完整未来”走向“保留行动所需未来”。这并不是降低目标,而是更贴近机器人控制的现实:控制环需要的是低延迟、可验证、可交互、物理合理且能泛化的未来表征。少做不必要的梦,才能更快、更稳地行动。