
多轮强化学习(Multi-turn RL)是当前提升LLM在复杂交互任务中推理能力的关键技术。然而,在实际训练中,一个显著且普遍的问题是训练不稳定,甚至演变为训练崩溃(training collapse),严重阻碍了该技术的广泛应用和规模化落地。以往的工作尝试通过细粒度信用分配、过程奖励建模或轨迹过滤等方法来稳定训练,但这些方法要么过于粗粒度,要么依赖间接的奖励塑造,在多轮设置的复杂动态下,其稳定效果非常有限,且对超参数极为敏感。
这篇来自UCLA与Amazon的研究团队(一作为Haixin Wang,通讯作者为Hejie Cui)的Spotlight论文,精准诊断了训练不稳定的根源——低效探索(inefficient exploration),或者说“犹豫(hesitation)”。这种犹豫现象表现在两个层面:在token级别,模型会生成大量信息增益快速饱和的思考令牌,导致过度思考;在turn级别,模型可能过早偏离正确路径,并在后续回合中重复无效行动。针对这一问题,论文提出了T²PO(Token- and Turn-level Policy Optimization),一个创新性的、不确定性引导的探索控制框架。
T²PO的核心创新在于,它不再通过额外的奖励塑造来间接干预,而是直接监控和显式控制探索行为本身。它利用自校准的不确定性信号,在token级别检测到思考不再带来不确定性降低时触发思考干预,在turn级别识别出探索进展可忽略的交互并进行动态重采样。该方法在一系列具有挑战性的多轮Agent基准测试(如WebShop、ALFWorld、Search QA)中,显著提升了训练稳定性和性能。这篇论文不仅为解决训练不稳定问题提供了新的理论视角(识别出“犹豫”是关键),还提供了一个清晰、可落地的技术方案,对于从事多轮RL、LLM推理训练、探索利用平衡等方向的研究者和工程师来说,极具参考价值和启发性。

摘要
近年来,多轮强化学习(RL)显著提升了推理型大语言模型在复杂交互任务上的表现。尽管在稳定技术方面取得了进展,例如细粒度信用分配和轨迹过滤,但不稳定问题仍然普遍存在,并经常导致训练崩溃。本文认为,这种不稳定性源于多轮设置中的低效探索:策略持续生成低信息量的动作,这些动作既不能降低不确定性,也不能推进任务进展。为了解决这个问题,我们提出了T²PO(Token- and Turn-level Policy Optimization),一个不确定性感知框架,能够在细粒度层面显式控制探索。在token级别,T²PO监控不确定性动态,一旦边际不确定性的变化低于阈值,就会触发思考干预。在turn级别,T²PO识别探索进展可以忽略的交互,并动态地重新采样这些回合,以避免浪费的轨迹收集。我们在多样化的环境中评估了T²PO,包括WebShop、ALFWorld和Search QA,结果证明了其在训练稳定性和性能改进方面取得了显著提升,并且探索效率更优。代码已开源:https://github.com/WillDreamer/T2PO。
引言:论文要解决什么问题
论文首先指出了多轮强化学习在训练agent进行推理、行动和自进化方面的巨大潜力。然而,当前的多轮RL训练管线在有效性和效率上都面临相互交织的挑战。一方面,长程交互结合稀疏的奖励信号使得信用分配(credit assignment)本身就很困难。另一方面,轨迹收集计算成本高昂,因此催生了低精度推理和异步采样等加速技术,但这些效率导向的方法不可避免地引入了离策略漂移(off-policy drift)和策略陈旧效应(stale policy effects),进一步放大了训练不稳定性,并经常导致臭名昭著的训练崩溃。 为了缓解训练不稳定性,先前的工作探索了多种策略,包括细粒度信用分配、内部或过程奖励建模,以及轨迹层面的失败交互过滤。这些方法旨在提供更密集的学习信号或移除无效轨迹,并在稳定优化方面取得了部分成功。然而,大多数现有解决方案要么在粗粒度的轨迹层面运作,要么通过奖励塑造进行隐式控制。在本质上复杂的多轮设置中,这种粗粒度或间接的干预使得训练动态对超参数和轨迹分布高度敏感,因此常常导致训练崩溃。
论文的核心洞察在于,通过分析代表性训练轨迹,作者识别出探索不足(insufficient exploration) 是根本原因,这反映了探索-利用权衡的系统性违背。作者将这种失败模式称为“犹豫(hesitation)”:
-
在Token级别 LLM agent经常表现出过度思考,生成长序列的token,其信息增益很快饱和,而采样噪声却在不断累积。
-
在Turn级别 LLM agent可能在早期就偏离了成功的动作空间,却在后续持续执行大量重复且无用的回合,在有限的预算内几乎没有恢复的机会。这种行为会给信用分配引入大量噪声,导致梯度不稳定和策略更新的高方差。
论文基于此提出,训练有效性和效率并非不可调和的对立面,一旦正确识别了不稳定性的根本原因,就可以通过控制探索行为来共同优化。T²PO正是通过捕获探索变得低效前的内在信号来控制探索,从而克服“犹豫”问题。
方法:核心思路与技术路线
T²PO的核心思路是构建一个不确定性引导的探索控制系统,在token和turn两个层级进行显式干预,以消除低效探索。其技术路线可以分解为以下几个关键模块:
1. 冷启动与基础设置 (Cold-start)
论文采用拒绝采样微调(RFT, Rejection-based Fine-Tuning) 作为冷启动策略。RFT基于环境反馈,从模型自身采样的trajectory中过滤掉那些失败或低质量的轨迹,只保留成功的高质量trajectory用于初始微调。这为后续的强化学习提供了一个更稳定、更有效的起点。 2. 注意力信号 (Attention Signal)
这是T²PO整个机制的基础。论文构造了一个自校准的不确定性信号,这是通过融合熵(Entropy) 和置信度(Confidence) 得到的。这个信号在agent与环境交互的轨迹收集过程中,被用作一个实时的监控信号。
3. 不确定性量化与犹豫识别
T²PO通过监控这个融合的不确定性信号的动态变化来识别“犹豫”行为:
- Token级犹豫 如果模型持续生成token,但其不确定性没有显著降低(即边际不确定性变化低于某个阈值),说明模型的思考已经趋于饱和,继续生成纯属积累噪声,这就是token级别的犹豫。
- Turn级犹豫 如果一个agent在多个回合中表现出相似的不确定性模式,意味着它可能陷入了重复无效行动的循环,这就是turn级别的犹豫。
4. Token级控制:思考干预
在token级别,T²PO持续监控不确定性动态。一旦检测到“边际不确定性变化”低于预设的阈值,即判断模型进入了过度思考阶段,此时会触发一个思考干预(thinking intervention)。这个干预将强制性地结束当前的思维链条,鼓励模型直接输出动作,从而避免在信息增益饱和后继续浪费计算资源。 5. Turn级控制:动态重采样
在turn级别,T²PO通过识别那些在不确定性模式上与先前回合相似、探索进展可以忽略的交互交互,来定位低效回合。一旦识别出这种“无效”交互,系统会执行动态重采样(dynamically resample)。这意味着,模型会丢弃这个无用的回合,并尝试从一个历史上下文(例如,一个相似但更成功的状态)开始重新采样,从而避免浪费整条轨迹。 6. 稳定训练的技巧
为了进一步稳定训练过程,论文还引入了以下辅助机制:
- 记忆上下文窗口 引入一个记忆上下文窗口,来缓解长程交互带来的训练压力,让模型能够更好地利用历史信息同时控制token长度。
- 格式惩罚 严格执行一个严格的格式惩罚,确保模型输出符合预期的结构化格式,这在多智能体交互中至关重要。
- SOTA策略更新 最终,采用最先进的策略更新方法来进行优化。
简而言之,T²PO的方法论是通过显式地、细粒度地控制探索过程,在token和turn两个层面消除无效或低效的探索行为,从而恢复一个平衡的探索-利用机制,并从根本上提升训练的稳定性。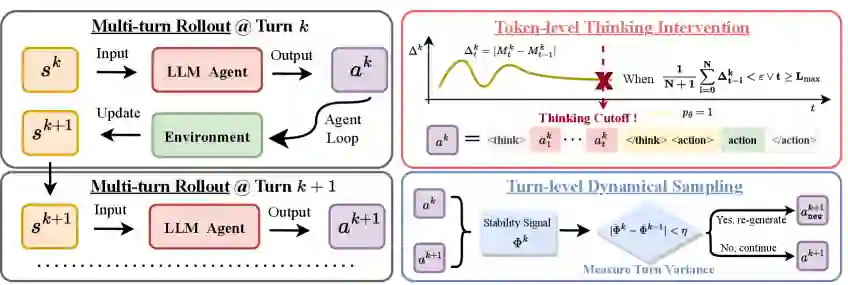
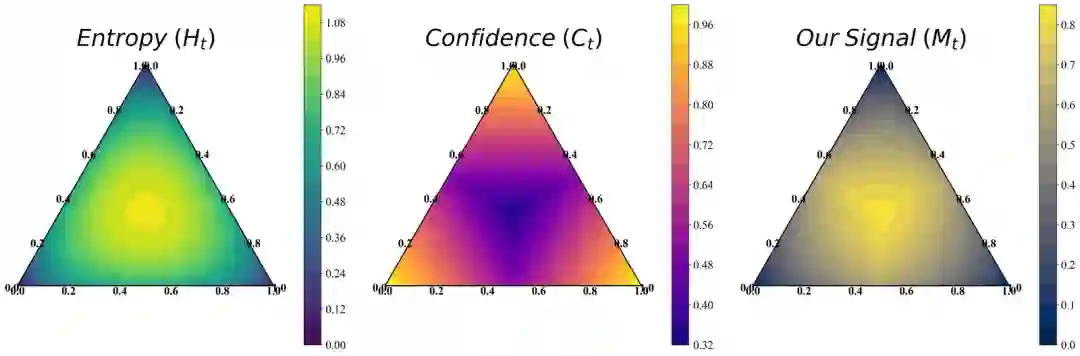

实验:设置、指标与结果
本文在三个具有代表性的多轮Agent基准环境中进行了评估。原文并未详细给出所有的实验超参数和基线方法的完整列表,但实验结果的核心洞察是清晰的。 数据集与环境
论文在三个环境上进行评估:
- WebShop 一个模拟在线购物的环境,agent需要通过与网页交互来满足用户的特定需求,涉及多轮决策和检索。
- ALFWorld 一个基于文本的家庭机器人任务环境,agent需要理解自然语言指令(如“将苹果放在桌子上”)并执行多步操作。
- Search QA 一个面向复杂信息检索的问答环境,agent需要通过多轮搜索和推理来回答用户问题。
评价指标
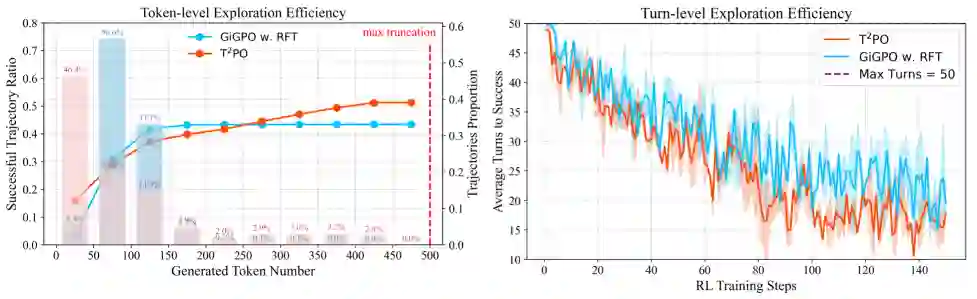
评估的核心指标是成功率和训练稳定性。作者通过监控训练过程中success rate的变化、KL散度的爆炸情况以及梯度范数的波动,来综合判断训练是否稳定。原文中未提供具体的、单一数值的对比表格,而是提供了图1来展示训练曲线,直观地对比了基线方法和T²PO的稳定性差异。 主要结果与对比
论文通过与SOTA基线方法的对比,证明了T²PO取得了训练稳定性和性能的显著提升,并表现出更优的探索效率。图1是文章的核心证据,展示了在不同环境初始化随机种子下,基线方法(如未使用T²PO的算法)会出现success rate急剧下降、内部信号(KL散度、梯度范数)爆炸的不稳定现象(图中橙色背景区域),而T²PO则有效地抑制了这种现象,保持了稳定且持续上升的性能曲线。 消融与分析
原文未明确说明,但从方法论的逻辑可以推断,作者可能通过消融实验来验证token级干预和turn级干预各自的贡献。然而,在提供的论文材料(包括摘要和引言)中,并未包含任何消融实验或深入分析的具体细节。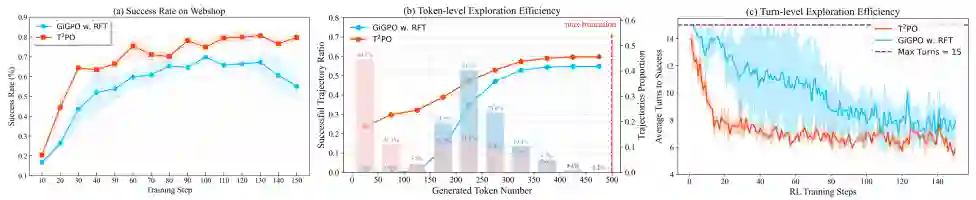
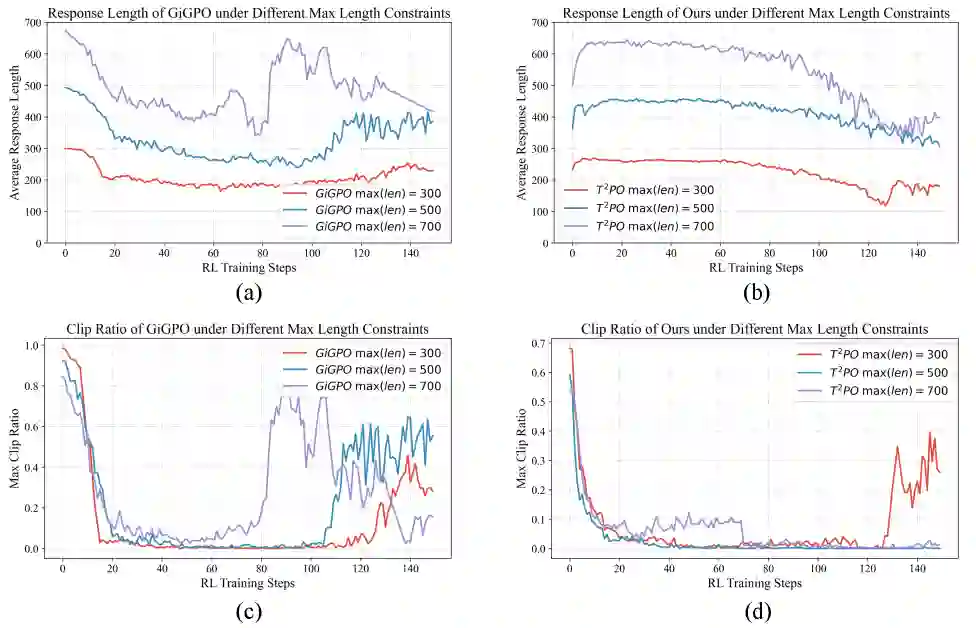
结论:贡献、局限与启发
贡献总结
- 问题诊断 首次明确地将多轮RL中的训练不稳定归因于“低效探索(hesitation)”,并细化为token级别的“过度思考”和turn级别的“重复无效行动”。
- 方法创新 提出了T²PO,一个新颖的、不确定性引导的探索控制框架。它直接控制探索过程,而非通过间接的奖励塑造,从而更有效地稳定训练。
- 技术贡献 构建了自校准的不确定性信号,并设计了token级思考干预和turn级动态重采样两个具体机制。
- 实证价值 在三个具有挑战性的多轮Agent基准上,证明了T²PO在提升训练稳定性和任务性能方面的显著优势,为后续研究提供了可复现的基线和方法。
局限与未来工作
原文未明确说明其局限性。但基于论文内容,可以推测一些潜在的局限:例如,对阈值设置的敏感性、在更复杂或开放域环境中的泛化能力、计算开销(不确定性监控和动态重采样)的控制等。这些也是未来可以探索的方向。 启发
T²PO的工作为多轮RL领域带来了重要启发。它提醒我们,在解决复杂训练问题时,深入到模型的内部动态(如不确定性信号)进行分析,比仅仅在外部奖励或轨迹层面进行修补更有价值。通过直接“治理”无效探索行为,而不是被动地适应它,是实现稳定、高效训练的关键。这种方法论视角对未来的算法设计具有重要的指导意义。
原文信息
论文:T²PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning 原文链接:http://arxiv.org/abs/2605.02178v1
