
导读
当大型语言模型(LLM)与工业自动化相遇,智能体(Agent)系统的范式正在经历一场静默而深刻的变革。然而,这些新兴系统究竟有多“成熟”?它们在工厂车间、能源网络和工程设计中的表现,与传统智能体系统相比有何本质不同?又面临哪些共同的瓶颈?
来自德国VDI/VDE-GMA技术委员会的16位学者,通过一篇严格遵循PRISMA 2020指南的系统性文献综述,为我们提供了迄今为止最全面的答案。这篇论文从2341篇出版物中筛选出88篇高质量文献,系统评估了基于基础模型(FM)的工业智能体在技术成熟度、功能概况和局限性上的全貌。
核心发现令人深思:75%的系统仍停留在原型开发阶段(TRL 4-6),仅有9.1%迈入部署阶段(TRL 7-9)。更值得关注的是,与传统工业智能体相比,新系统在人机交互能力上提升了37%,不确定性处理能力提升了35%,但协商能力却下降了39%——这种“偏向辅助、弱于协调”的范式转换,正在重新定义工业自动化的边界。对于任何关注工业AI落地的研究者或从业者而言,这篇文章提供了不可多得的数据基准和概念框架。
论文基本信息
英文题目 Foundation-Model-Based Agents in Industrial Automation: Purposes, Capabilities, and Open Challenges 作者 Vincent Henkel, Felix Gehlhoff, David Kube, Asaad Almutareb, Luis Cruz, Bernd Hellingrath, Philip Koch, Christoph Legat, Florian Mohr, Michael Oberle, Felix Ocker, Thorsten Schoeler, Mario Thron, Nico Andre Töpfer, Lucas Vogt, Yuchen Xia arXiv ID 2605.02592 类别 cs.AI
Comments/接收信息 35 pages, 8 figures, 1 table. Submitted to Journal of Intelligent Manufacturing for peer review. A comparison of classical agent applications and foundation-model based agents is presented. 原文链接 http://arxiv.org/abs/2605.02592v1
摘要
基础模型,特别是大型语言模型,正越来越多地被集成到面向工业任务的智能体架构中,涵盖决策支持、过程监控和工程自动化等领域。然而,关于这些系统的目的、能力和局限性的证据,在不同领域之间仍然是碎片化的。本研究通过一项遵循PRISMA 2020指南的系统性文献综述,筛选了2341篇出版物,最终纳入88篇,并采用结构化编码方案进行综合。结果显示:75.0%的系统处于TRL 4-6的开发阶段,仅9.1%达到TRL 7-9的部署阶段。操作目标最常见的是用户辅助、监控和过程优化,而传统的生产控制目的(如规划、调度)则较少出现。与传统工业智能体系统的基线相比,基于基础模型的智能体在人机交互能力上提升了37%,在不确定性处理能力上提升了35%,但在协商能力上下降了39%。广泛报告的局限性包括缺乏泛化能力、幻觉和输出不稳定、数据稀缺以及推理延迟。此外,本文还提出了一个基于基础模型的工业智能体的工作定义,融合了传统智能体理论、自动化工程标准和基础模型范式。
引言:论文要解决什么问题
尽管基础模型驱动的智能体系统在工业领域(如工程自动化、车间控制、能源系统运行)迅速普及,但该领域面临三个核心问题: 第一,技术成熟度不明。证据分散在不同应用领域、技术成熟度和评估实践中,缺乏一个能够聚合这些信息的统一框架。单个论文可能报告了制造、物流、能源或工程设计中的原型,但无法判断整个领域是否已准备好大规模部署。 第二,功能概况缺乏比较基准。基础模型的引入如何改变了工业智能体的功能画像?与传统基于规则或优化驱动的智能体(如经典的多智能体系统)相比,新系统在哪些能力上取得了真正进步,又在哪些方面存在不足?此前缺乏量化的比较分析。 第三,缺乏连接传统智能体概念与基础模型范式的工作定义。现有定义要么过于宽泛(如仅仅将LLM等同于智能体),要么过于狭窄,无法统一自动化工程标准与新兴的智能体AI概念。这导致了“概念回溯”(conceptual retrofitting)现象,即用传统思想、欲望、意图框架来描述现代基于LLM的系统,尽管两者运行机制存在本质差异。 为解决这些问题,论文作者提出了三重研究目标:评估基于基础模型的智能体在工业环境中的成熟度、功能概况差异,以及持续性局限性。
方法:核心思路与技术路线
本文采用PRISMA 2020指南进行系统性文献综述,整个方法流程分为四个关键部分。
Section 3.1:Working Definition / 工作定义
为了让筛选具有可重复性,论文提出了一个严格的工作定义:一个基于基础模型的工业智能体是一种封装在硬件或软件中的实体,在工业系统背景下行动,能够自主行动以满足指定设计目标,并使用基础模型作为上下文解释、决策、动作选择和执行的核心组件。 这个定义融合了三重来源:Wooldridge的经典智能体概念(自主行动、环境感知)、VDI/VDE 2653自动化工程标准(封装实体、控制目标)、以及基础模型特性(大规模预训练、可适应多种下游任务)。定义要求:系统必须展示超出纯文本生成的自主行为,且基础模型必须参与决策循环(如解释上下文、规划、选择动作或协调工具调用)。
Section 3.2:Data Sources and Search Strategy / 数据源与搜索策略
检索覆盖四个文献和预印本源:Scopus、Semantic Scholar、arXiv 和 OpenAlex。检索时间范围从2020年起,截止到2025年9月8日。检索词由三个概念块组成:(1)基础模型/LLM相关术语;(2)智能体或多智能体系统术语;(3)工业背景术语(制造、生产、物流、能源、工程等)。最终获得3025条结果,去重后得到2341条唯一记录。
Section 3.3:Screening and Eligibility / 筛选与资格标准
资格标准严格要求:(1)论文必须描述具体应用、实现或案例研究(排除纯概念性或综述);(2)系统使用一个或多个LLM/MLLM/FM作为智能体架构的一部分;(3)应用背景为工业或工业相关。 由于初始语料库规模较大,标题与摘要筛选由LLM辅助完成——LLM为每条记录分配相关性分数,阈值通过人工标注样本校准,低于阈值的子集经人工审查以控制假阴性。通过筛选的记录进入全文评估阶段,由作者根据工作定义判断最终资格。资格标准排除了纯概念性工作和高层愿景论文。
Section 3.4:Taxonomies and Coding Scheme / 分类法与编码方案
论文采用Reinpold等人建立的“目的-属性-能力”分类框架。系统目的描述操作目标类别(如规划、调度、控制、监控、用户辅助等);能力描述系统展示的具体功能技能(如交互、通信、协调、推理等);属性则聚合能力证据以支持语料库级别的比较。因为每个系统可能服务多个操作目标,目的被编码为多标签指标——最终88篇论文共产生230个目的分配。
Section 3.5:Comparative Analysis and Baseline / 比较分析与基线
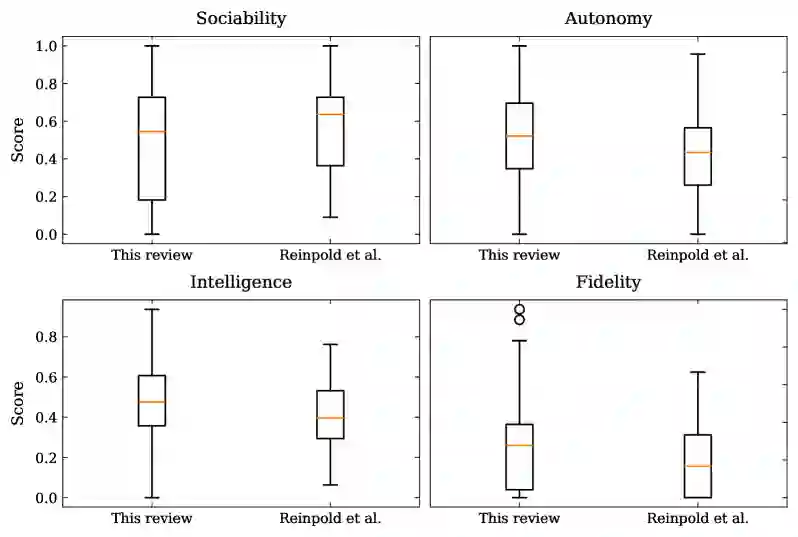
为了回答功能概况的差异(RQ2),论文使用Reinpold等人对145篇论文的系统性综述作为定量基线。该基线提供了相同分类法下的目的和能力复合分数,使两者能够在同一框架下进行直接比较,从而量化基础模型集成带来的能力变迁。
实验:设置、指标与结果
本文是综述论文,原文未进行新的统一实验。但其结果部分实际上相当于大规模的比较分析实验,主要评估维度如下。
评估方式:定量比较分析与TRL评估
评估并非通过统一的基准测试集完成,而是通过对88篇论文的标准化编码和聚合,与既有基线进行统计比较。技术成熟度采用NASA的九级TRL量表,分为三档:研究(TRL1-3)、开发(TRL4-6)、部署(TRL7-9)。
主要结果
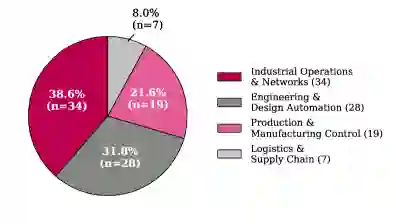
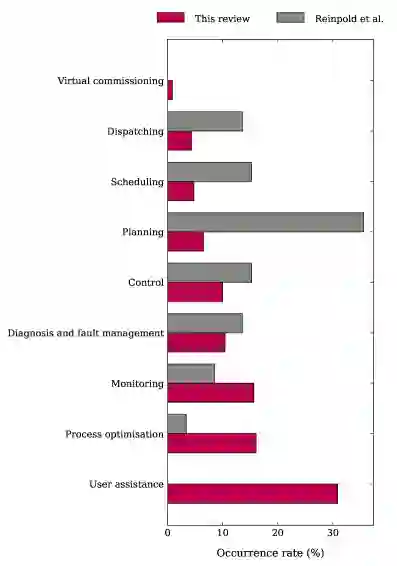
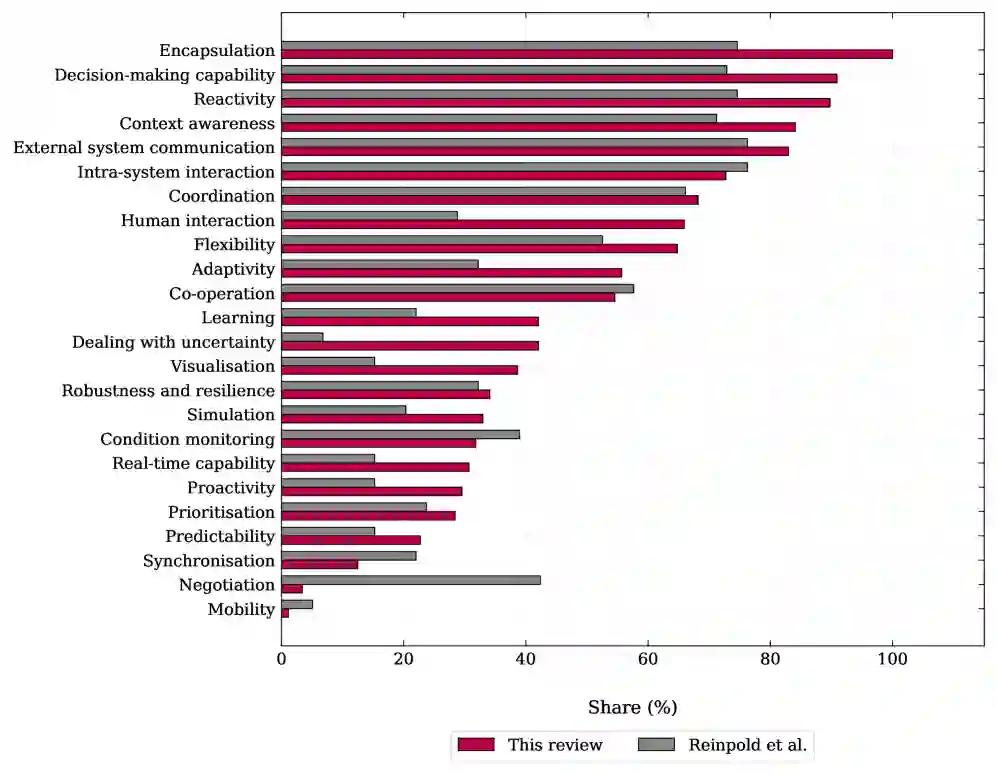
技术成熟度分布:75.0%的系统处于TRL 4-6(开发阶段),15.9%处于TRL 1-3(研究阶段),仅9.1%处于TRL 7-9(部署阶段)。这表明大多数系统仍停留在实验室原型和早期验证阶段,从原型到部署的“最后一公里”尚未被广泛跨越。 应用领域分布:最大的集群是工业运营与网络(38.6%),涵盖电网运行、能源管理、IT运营、自动驾驶等;其次是工程与设计自动化(31.8%),包括电子设计自动化、仿真建模、产品设计等;生产与制造控制占比21.6%;物流与供应链占8.0%。 系统目的变迁:用户辅助最常被报告(30.9%),这一类别在传统基线中完全不存在。过程优化(16.1%)和监控(15.7%)紧随其后。而传统生产控制目的如调度(4.3%)、规划(4.3%)和分派(3.5%)则明显减少。这表明基础模型的引入显著扩大了智能体的应用范围,从传统的生产控制任务转向以辅助和决策支持为中心的任务。 能力比较(vs 基线):与Reinpold等人提供的基线相比,基于基础模型的智能体在人机交互能力上提升37%,在不确定性处理能力上提升35%。然而,协商(negotiation)能力下降了39%——这是传统多智能体系统中核心的交互机制,但在基础模型驱动的系统中明显弱化。多数系统展示了封装、决策能力和反应性(超过90%),以及外部系统通信能力(超过80%)和上下文感知。
消融/分析
原文未报告消融实验。但论文通过两个维度的分析替代了传统消融:一是“目的-能力-属性”框架下的整体能力分布分析,揭示了FM引入后的结构性能力变迁;二是对工作定义的回顾性评估,验证了其捕捉文献中系统的充分性——90%以上的系统满足封装、决策和反应性要求,表明定义整体上是有效的,但可能存在边界案例(如纯粹的对话式知识检索接口是否满足“自主行动”标准)。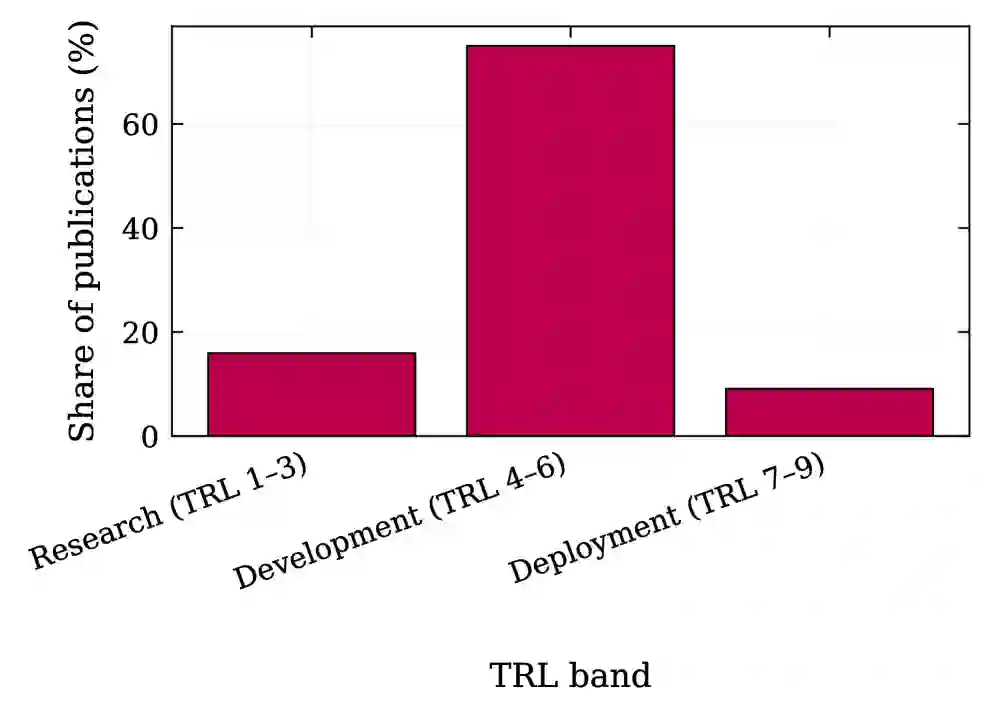
结论:贡献、局限与启发
主要贡献
- 首次系统性地绘制了基于基础模型的工业智能体的技术成熟度地图,提供了跨领域、跨应用的可量化概览。
- 提出了一个可操作的工作定义,连接了传统智能体理论、自动化工程标准和基础模型范式,为未来研究和评估提供了概念基础。
- 通过与既有基线的定量比较,揭示了FM集成带来的能力变迁——人机交互和不确定性处理的大幅提升,以及协商能力的显著下降。
讨论与局限性
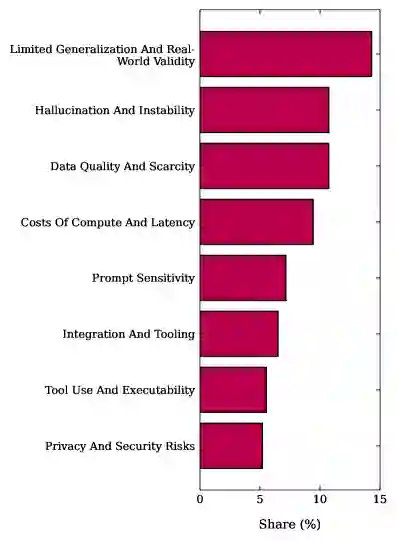
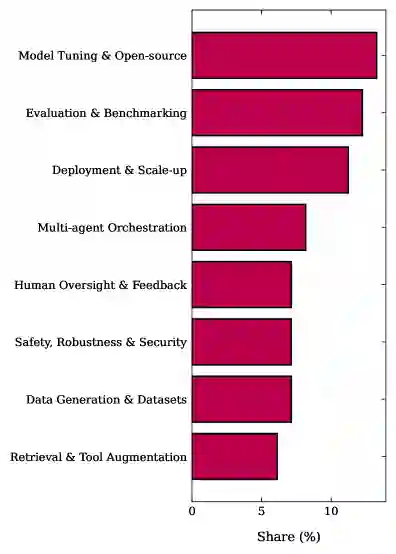
威胁有效性:筛选策略排除了纯概念性工作,可能导致TRL 1-3的研究被低估;同时,更高成熟度的系统(TRL 7-9)可能因知识产权保护而未在学术文献中公开。 局限性综合分析:最广泛报告的限制包括缺乏泛化能力、幻觉和输出不稳定、数据稀缺、推理延迟。可靠性和安全问题是主要工业部署障碍,特别是与工业自动化基础设施的接口挑战。目前超过一半的系统未能通过全面的现实世界部署验证。 启发:对于工业部署而言,集成、延迟和安全保障是当前关键瓶颈——许多系统不仅受限于基础模型本身,更受限于端到端的可靠动作执行和监督工程。对于评估而言,需要更一致的报告标准(涵盖鲁棒性、失败模式和操作约束)。对于架构设计而言,语言介导的交互和知识密集型推理是当前FM智能体的突出价值主张,而协商密集型模式尚未充分发展。