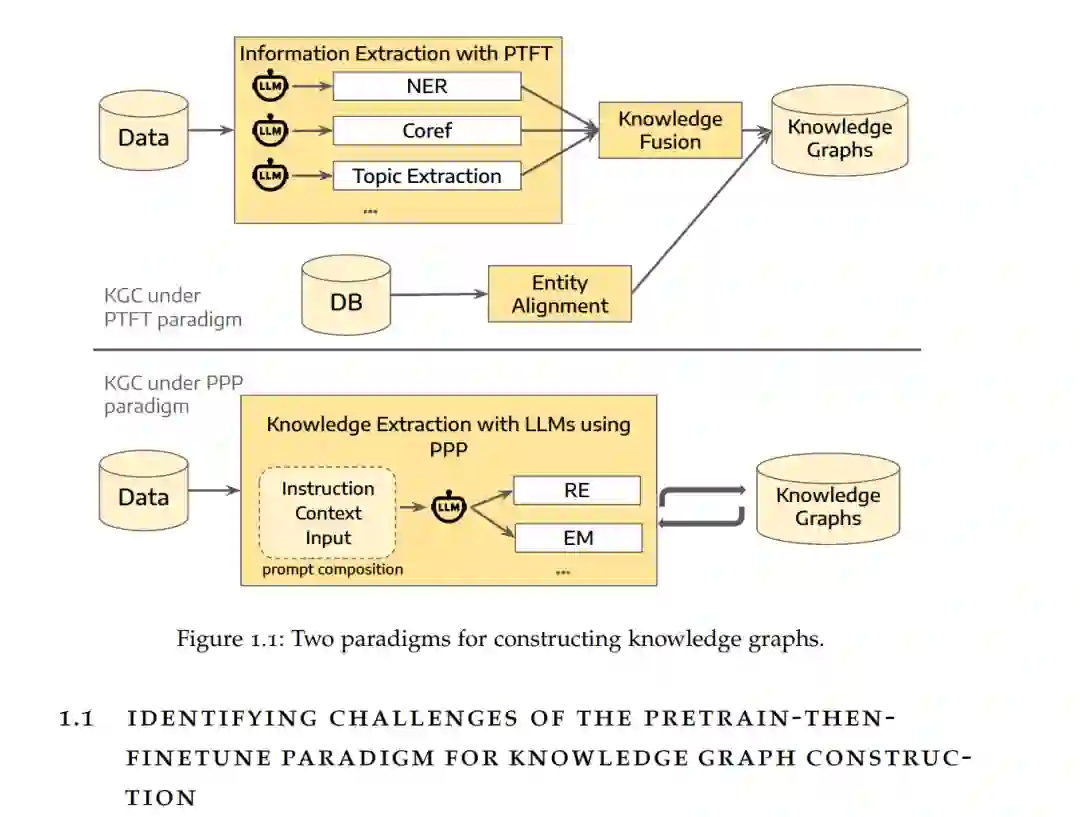
摘要—知识图谱(KG)提供了结构化、机器可执行的信息表示,支撑着搜索、推理及决策过程。然而,在组织级对话等复杂领域中,由于数据存在噪声、动态演变且高度依赖语境,构建知识图谱仍面临挑战。
本论文通过两个互补视角探讨了知识图谱构建(KGC)如何适应这些条件:(i) 分析了“预训练-微调”(PTFT)范式在应用于对话数据时的局限性;(ii) 探索了新兴的“预训练-提示-预测”(PPP)范式如何提供更灵活、更具成本效益的工作流。 在第一部分中,我们调查了基于 PTFT 的信息抽取模型在现实世界变化下的脆弱性。研究表明:命名实体识别中的分布偏移会导致预测性能大幅下降;静态主题模型虽然在语义上连贯,但难以检测新主题的涌现;而多方邮件中的跨篇章指代消解则暴露了当前方法的持久性弱点。这些发现突显了特定任务模型在面对输入偏移、时间演变和长对话结构时的局限性。 在第二部分中,我们转向基于 PPP 的工作流,利用大语言模型(LLM)的提示工程(Prompting)而非微调。我们证明,只要对图谱模式(Schema)知识进行精心编码,经过指令微调的 LLM 就能在关系抽取中取得具有竞争力的结果。我们引入了“以知识为中心的提示词构建”方法来引导上下文学习(In-context Learning),研究表明,融合了模式约束和示例的提示词能显著提升抽取质量。最后,我们提出了一种用于数据准备的混合系统 TableSwift,该系统在 LLM 生成的代码与确定性回退机制之间路由任务,从而在保持转换、错误检测和实体匹配准确性的同时降低成本。 综上所述,本论文描绘了 KGC 领域的一个关键范式转变:从依赖专门化模型的 PTFT 流水线,转向可提示(Promptable)、可适应且具备成本意识的 PPP 工作流。通过诊断 PTFT 的缺陷并设计基于 PPP 的解决方案,本论文为在复杂的现实领域构建可靠的知识图谱提供了实证见解与实践架构。