
导读
传统强化学习已经广泛用于无线资源调度、计算卸载、路由控制与网络防御,但它在真实通信网络中始终面临几项共同困难:在线交互代价高,长期时间依赖难以建模,部分可观测环境下状态表示不足,而且用户、链路、任务与移动节点的数量会持续变化。Transformer 的自注意力机制恰好提供了一组互补能力:并行处理长序列、聚合全局上下文、融合异构模态,并对可变规模实体进行关系建模。 这篇综述《Transformer-Enhanced Reinforcement Learning: Fundamentals and Applications in Communication Networks》系统梳理了 Transformer 与深度强化学习的结合方式,并把通信网络中的应用组织为四大板块:资源分配、计算卸载、路由与轨迹控制、网络安全。论文既介绍马尔可夫决策过程、注意力机制和典型强化学习算法,也比较 Transformer 在不同方案中究竟承担状态编码、轨迹生成、多智能体协调还是预测辅助等角色。 本文严格按照原论文的章节顺序展开,并将六幅关键原图放回相应论述位置。阅读重点不只是“Transformer 能否提升强化学习”,而是理解它在何种网络状态结构、决策时间尺度和任务约束下真正有价值,以及当前方案在样本效率、计算开销、可扩展性和工程部署方面仍存在哪些边界。
论文基本信息
- 英文题目 Transformer-Enhanced Reinforcement Learning: Fundamentals and Applications in Communication Networks
- 中文题目 Transformer 增强强化学习:基础原理及其在通信网络中的应用
- 作者 Nguyen Cong Luong、Shaohan Feng、Nguyen Duc Hai、Zeping Sui、Bo Ma、Min Xu、Zhihao Dong、Qiushi Zhao、Nguyen Duc Duy Anh、Nguyen Quoc Khanh、Ngoc Hung Nguyen、Zitian Zhang、Jie Cao
- 论文类型 综述论文
- arXiv ID 2606.05208
- 研究领域 信号处理、机器学习、通信网络、深度强化学习
- 分类 Signal Processing(eess.SP)、Machine Learning(cs.LG)
- 首次提交日期 2026 年 5 月 26 日
- 接收信息 原文未明确说明
- 原文链接 https://arxiv.org/abs/2606.05208
Abstract / 摘要
强化学习长期以来一直是解决通信网络序贯决策问题的重要工具,但传统模型通常依赖大量环境交互,并且在长期依赖建模、部分可观测状态处理和跨实体关系表示方面存在局限。Transformer 通过自注意力机制捕获远距离依赖与全局相关性,同时支持并行训练和异构数据处理,因此逐渐成为增强强化学习状态表示与决策能力的重要架构。 该综述系统介绍强化学习与 Transformer 的数学基础,总结 Transformer 增强深度价值网络、演员评论家、近端策略优化和多智能体强化学习等主要方式,并进一步梳理其在通信网络中的四类核心应用:资源分配、计算卸载、路由与轨迹控制、网络安全。 论文最后总结 Transformer 强化学习的共性优势与现实限制,并讨论其在超可靠低时延通信、智能表面辅助无线系统和车联网中的未来研究机会。
1 Introduction / 引言
研究背景与核心问题
强化学习(RL)与监督学习、无监督学习并列为机器学习的三大范式,为智能体与环境的序贯决策与交互提供了严密的数学框架。凭借其无模型特性,RL在自动驾驶[1]、机器人[2]、推荐系统[3]以及通信与网络领域展现出巨大潜力。随着第六代移动通信系统(6G)的深入发展,RL已被广泛应用于无线网络中的资源分配与功率控制[4]、用户调度[5]、数据感知与收集[6]等任务。尤其在物联网(IoT)、异构网络(HetNets)和无人机(UAV)网络等系统中,由于非线性、不确定性和大规模异构性,精准的数学模型往往难以获得,RL的无模型优势使其成为理想工具[7]。 然而,传统RL及其深度扩展(DRL)在通信应用中仍面临若干核心挑战。第一,多数RL算法需要与环境进行大量交互才能收敛,在真实无线环境中成本高昂且不切实际[8]。第二,以循环神经网络(RNN)或卷积神经网络(CNN)为基础的标准DRL架构,在建模长期时间依赖和全局上下文方面能力有限[9],而这两者在动态无线信道和变化的网络拓扑中至关重要。第三,RL智能体常受困于部分可观测性问题(即无法获取环境的完整信息)以及跨不同网络设置的泛化能力不足[10],导致训练不稳定、性能次优,并在大规模或高动态无线系统中难以扩展。 近期,Transformer架构[11]的出现为上述挑战提供了新的解决路径。Transformer最初作为自然语言处理(NLP)中的序列建模方法提出,其核心自注意力机制能够捕获长程依赖和全局相关性,并灵活建模不同长度的复杂序列。因此,研究者开始将Transformer集成到DRL中,以应对通信系统中的各类难题。具体而言,基于Transformer的DRL可借助其对长期时间相关性、多智能体交互以及结构化决策依赖的捕获能力,解决资源分配问题(如功率控制[12]、带宽分配[13]);在计算卸载问题中,Transformer能够建模高维系统状态、处理异构任务需求以及计算、通信、网络资源的动态交互[14][15];在大规模无线网络中,Transformer架构被嵌入DRL框架以处理路由与轨迹决策,因其能捕获长程依赖、动态拓扑以及由移动性、资源限制和多智能体协作导致的高维动作表示[16][17];此外,基于Transformer的RL在网络安全领域也展现出有效性,能够增强对动态演化攻击的适应性,并处理多智能体和大规模网络安全系统中的部分可观测性问题[18][19]。
现有研究与综述空白
目前,已有若干关于Transformer和DRL的综述或教程,但尚无工作全面阐述Transformer如何与RL融合以解决通信网络中的具体问题。例如,文献[20]提出了一个基于Transformer的新型DRL框架,利用自注意力机制处理IoT设备的异构高维数据以增强状态表示;而文献[21]在3GPP TDL-A信道模型下比较了Transformer与其他神经网络架构在时域信道预测中的性能;文献[22]提出了一个AI增强信道预测的通用框架,并讨论了Transformer在该领域的集成;文献[23]聚焦于生成式AI(GenAI)如何增强DRL(包括基于Transformer的DRL),总结了GenAI增强DRL的优缺点,并给出了近场通信场景下的案例比较。尽管如此,这些工作均缺乏对Transformer-based DRL在通信网络中应用的专门总结与系统梳理。
综述范围与主要贡献
基于上述空白,本文对Transformer如何集成到DRL中以解决通信网络问题进行了全面综述。主要贡献总结如下:
- 提供RL与Transformer的详尽教程,阐述两者的数学基础,并说明不同类型的Transformer如何增强RL方法以应对通信网络中的问题。
- 综述并讨论Transformer在RL中用于通信网络资源分配的各种应用,涵盖无线/传输资源分配、网络接入与连接控制、虚拟网络功能部署、内容感知速率自适应以及计算-通信联合资源分配等问题。
- 调研并分析最新的基于Transformer的RL方法在通信网络计算卸载中的应用,重点关注计算资源分配、联合计算-通信资源分配、移动感知与动态卸载、AI与GenAI服务/大模型导向的卸载等典型问题。
- 综述基于Transformer的RL在路由与轨迹控制中的应用,讨论用于长时域和多智能体路由、轨迹规划、序列建模、风险感知路由与轨迹控制的Transformer-based DRL方法。
- 考察基于Transformer的RL在网络安全领域的最新进展,包括对抗各种攻击(如干扰、数据投毒与注入、对抗攻击、物理层攻击、感知攻击)的防御机制。
- 最后,讨论关键挑战与开放问题,并指出基于Transformer的RL在通信网络中的未来研究方向。
文章组织
本文其余部分组织如下:第II节介绍Transformer与RL的基础知识;第III节讨论基于Transformer的RL在通信网络资源分配中的应用;第IV节综述Transformer应用于RL的计算卸载方法;第V节评述基于Transformer的DRL在路由与轨迹控制中的方案;第VI节探讨Transformer与RL在通信网络安全问题中的集成;第VII节总结关键挑战与未来研究方向,并结束全文。
2 Fundamentals of Transformer for DRL / 面向深度强化学习的 Transformer 基础
强化学习基础
# 马尔可夫决策过程与价值函数
强化学习(RL)通过一个T步马尔可夫决策过程(MDP)形式化描述,定义为元组⟨S, A, P, r, γ, ρ0⟩,其中S为状态空间,A为动作空间,P(st+1|st, at)为状态转移概率,r(st, at)为即时奖励,γ∈(0,1)为折扣因子,ρ0为初始状态分布。智能体在与环境交互中生成轨迹Θ = {(st, at, rt)}Tt=1,目标是学习策略π(a|s)以最大化期望累积回报J(π) = Eπ,P,ρ0[Σγtr(st, at)]。为求解最优策略,RL方法通常估计三种核心函数:动作价值函数Qπ(st, at)衡量在状态st采取动作at后的期望回报;状态价值函数Vπ(st)衡量从st开始遵循策略π的期望回报;优势函数Aπ(st, at) = Qπ(st, at) − Vπ(st)用于降低直接使用Q值带来的方差。当智能体无法观测全局状态时,问题扩展为部分可观测MDP(POMDP),智能体仅能获取局部观测ot。
# 基于价值与基于策略的方法
基于价值的方法(如Q学习、DQN)通过逼近最优动作价值函数Q*(s, a)间接导出策略,通常利用时序差分(TD)误差更新。基于策略的方法(如REINFORCE)直接参数化策略πθ(a|s),通过策略梯度∇θJ(θ) = E[∇θlog πθ(at|st)At]优化。演员-评论家(Actor-Critic)方法结合两者:演员更新策略,评论家估计价值函数以提供低方差优势估计。此外,RL还可分为基于模型与无模型两类:基于模型的方法学习环境转移模型用于规划或数据合成,样本效率高但计算开销大;无模型方法直接学习策略,鲁棒性强但采样效率较低。
# 在线强化学习与离线强化学习
在线RL中,智能体通过与环境实时交互收集数据更新策略,其中同策略(on-policy)方法使用当前策略生成的数据,实现简单但样本利用率低;异策略(off-policy)方法允许重用历史经验,样本效率高但稳定性需额外技术(如经验回放)。离线RL(offline RL)则从静态数据集D中学习最优策略,不与环境交互。该范式在医疗、自动驾驶、机器人操作等场景中具有重要应用,但面临分布外状态与动作的挑战,易导致性能退化。离线RL要求算法从行为策略πβ生成的轨迹中提取足够的环境动态知识,并泛化到测试时分布。
变换器与注意力机制基础
# 变换器架构
原始Transformer由编码器-解码器构成,核心为多头自注意力(MHA)与位置感知前馈网络(FFN)。给定输入X,通过线性映射生成查询Q、键K和值V,缩放点积注意力计算为Attention(Q,K,V)=Softmax(QK^T/√dk)V。多头发散允许模型从不同表示子空间捕获信息。每个子层后使用残差连接与层归一化以稳定训练。由于缺乏序列固有顺序,通过正弦位置编码注入位置信息:PE(pos,2i)=sin(pos/10000^{2i/dmodel}),PE(pos,2i+1)=cos(pos/10000^{2i/dmodel})。这些设计使Transformer能够并行处理长序列,并在自然语言处理等领域取得突破性进展。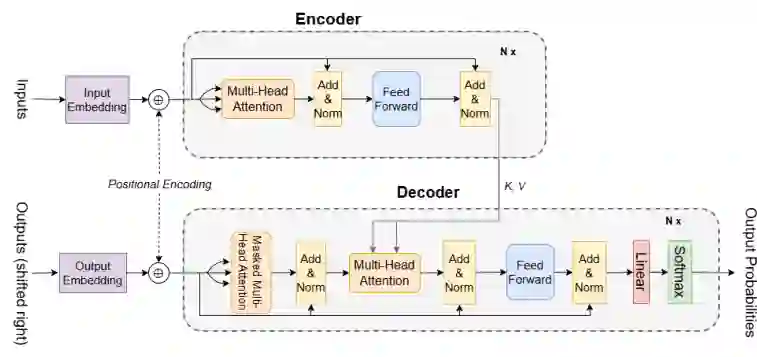
# 注意力机制变体
为降低计算复杂度或引入先验知识,研究者提出了多种注意力变体:(1)稀疏注意力:引入稀疏偏置减少运算量;(2)线性化注意力:利用核特征映射解耦注意力矩阵实现线性复杂度;(3)原型与内存压缩:减少查询或键值对数量;(4)低秩自注意力:利用Nyström方法或低秩核近似;(5)先验注意力:集成可训练先验分布到注意力模块中;(6)改进多头机制:如头行为建模、受限跨度等。此外,Transformer被扩展到视觉(ViT、Swin Transformer)、图数据(GAT、Graphormer)等领域,展现出泛化能力。
基于变换器的强化学习
# 变换器增强的深度价值网络
经典DQN通过最小化TD损失L(θ)=E[(r+γmaxa'Qθ-(s',a')−Qθ(s,a))^2]逼近动作价值函数。Transformer增强的DQN将历史观测、动作与奖励组织为序列,利用自注意力捕获长程时间依赖,从而改善部分可观测环境中的状态表示。代表性工作TransDreamer集成基于Transformer的世界模型学习潜在动态并计算多步价值目标。在通信系统中,这类价值型方法可用于频谱接入、功率控制、计算卸载与路由等需要利用历史信息估计动作价值的任务。
# 变换器增强的优势演员评论家
优势演员评论家(A2C)联合优化策略πθ(a|s)和价值函数Vϕ(s),策略梯度目标为∇θJ(θ)=E[∇θlog πθ(at|st)At],其中At=rt+γVϕ(st+1)−Vϕ(st)。Transformer增强的A2C将演员和评论家的编码器替换为Transformer,处理轨迹片段并改善部分可观测环境中的表示学习。自注意力允许评论家依据较长时间范围的上下文计算价值估计,也可用于表示大规模网络中的跨设备耦合关系。
# 变换器增强的近端策略优化
PPO通过裁剪替代目标LPPO(θ)=E[min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ)At)]稳定策略梯度,其中rt(θ)=πθ(at|st)/πθold(at|st)。Transformer增强的PPO将注意力编码器集成到策略和/或价值网络中,处理轨迹令牌并生成具有上下文信息的动作分布。相关工作将其用于无线资源分配、计算卸载和路由规划,以表示用户耦合、任务依赖及时空状态。
# 变换器增强的多智能体强化学习
多智能体强化学习(MARL)面临可扩展性与非平稳性挑战。Transformer引入智能体间注意力,对实体之间的依赖进行显式建模。以QMIX为例,其通过单调性约束∂Qtot/∂Qi≥0确保全局优化与局部决策一致,联合损失L=E[(ytot−Qtot(s,a;θ))^2]。集成Transformer的TransfQMix将智能体内部状态和环境实体视为协调图中的顶点,利用多头自注意力动态生成协调权重,并保持对实体排列的适应能力,可迁移至智能体数量变化的任务。
# 无线网络案例分析
本案例对比离线Transformer强化学习(采用决策Transformer范式)与标准离线DRL在能量收集无线传感器网络中的功率分配性能。系统状态由信道增益与电池电平构成,动作对应离散发射功率,回报同时考虑传输速率与电池耗尽造成的中断。离线数据由专家、中等和激进策略共同产生,其中专家轨迹只占较小比例,因此数据质量并不均匀。结果显示,标准离线DRL容易学习数据集中的平均行为,并受占比较高的激进策略影响;Transformer增强方法通过最高可达回报进行条件化,能够从混合数据中隔离并模仿专家子策略。其训练损失下降更快,回报分布也更集中于高值区域,并能更稳定地避免电池耗尽状态。该案例说明,回报条件化与序列上下文有助于离线强化学习从含噪轨迹中提取高质量策略。 总体而言,Transformer与强化学习的结合主要体现为两种方式:一类把注意力模块嵌入价值网络、策略网络或评论家网络,以增强历史状态和多实体关系表示;另一类把状态、动作和回报序列直接作为建模对象,将决策转化为条件序列生成。前者延续传统深度强化学习的优化框架,后者尤其适合利用离线轨迹数据。二者共同关注长期依赖、部分可观测性与异构状态表示,但具体收益仍取决于任务结构、数据质量和所采用的强化学习算法。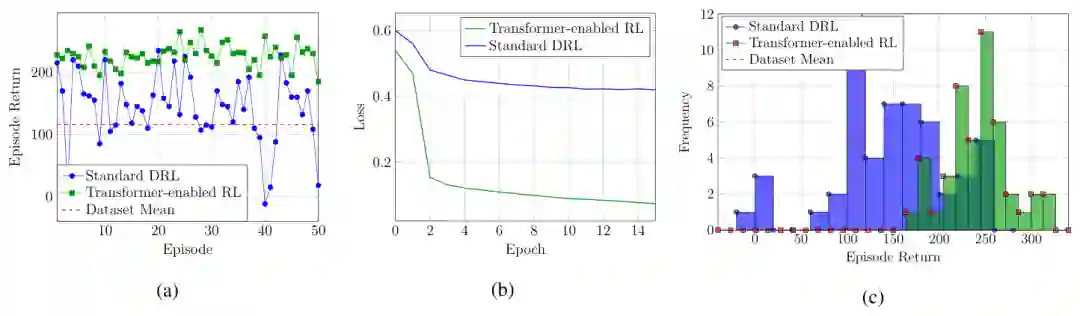
3 Transformer-based RL for Resource Allocation / 基于 Transformer 强化学习的资源分配
资源分配决定了通信网络中无线、网络和服务资源如何根据时变业务需求、信道条件和用户行为进行动态分配。这类问题通常涉及顺序决策、大规模异构动作空间以及跨时间、用户和资源类型的强耦合,对传统深度强化学习方法提出了显著挑战。通过将 Transformer 嵌入深度强化学习框架,近期研究利用基于注意力的序列建模和全局上下文建模,能够捕获实际资源分配中的长期时间相关性、多智能体交互以及结构化决策依赖。本节从五个代表性角度综述 Transformer 增强的深度强化学习方法:1)无线电与传输资源分配,包括功率、带宽、波束成形和调制;2)网络接入与连接控制,涵盖接入、关联、调度和切换;3)虚拟网络功能放置;4)内容感知速率适配;5)计算与通信联合资源分配。综合来看,这些研究表明 Transformer 能够提升基于深度强化学习的资源分配在可扩展性、长时域决策和结构感知方面的能力。
无线电与传输资源分配
近期工作越来越多地将 Transformer 集成到深度强化学习框架中,用于功率控制、带宽分配、波束成形和调制,以处理时间动态性、结构化依赖和高维决策空间。
# 功率控制
针对正交频分复用系统,文献[12]研究时频域的自适应发射功率控制,以最小化长期误码率。一种数字孪生辅助的深度强化学习框架在虚拟信道上预训练智能体,并部署到真实场景进行功率分配,其中基于 Transformer 的虚拟信道生成器预测未来多用户信道状态,实现“预测‑决策”控制并提升稳定性。相比基线方案,该方法误码率降低约60%[12]。不同于[12],文献[102]考虑密集设备部署下的功率控制。针对双向远距离广域网,[102]研究上行发射功率优化以提高数据包投递可靠性和能效。一个全局 Transformer 被集成到演员‑评论员深度强化学习框架中,将所有终端设备的联合状态编码为共享表示,支持跨设备的上下行协调优化。为在有限信息交换下实现分布式功率优化,文献[103]研究基于局部观测的离线多智能体发射功率控制,目标为最大化总速率。一个离线多智能体强化学习框架使每条链路能够从预收集交互数据中学习分布式功率策略,无需在线探索。多智能体决策 Transformer 进行轨迹级的序列建模,捕获长期依赖关系,在部分和延迟信息下改进了功率决策。然而,文献[102]和[103]均未针对高速移动场景设计。针对多连接车载网络,文献[104]提出一种协作式多智能体近端策略优化框架,用于高移动性和非完美信道状态信息下的逐链路功率协调,实现超可靠低延迟通信并降低干扰和能耗。Transformer 通过基于注意力的特征聚合,支持服务于同一用户的多条链路之间的信息共享,从而实现协调的功率分配决策。
# 带宽分配
针对毫米波集成接入与回传网络,文献[13]研究在时变业务需求下为并发接入链路和回传链路进行动态子信道分配。开发了一种基于 DQN 的框架以最大化长期系统吞吐量,同时考虑干扰和资源约束。Transformer 作为状态表示模块,捕获业务需求和链路条件的时间相关性,从而在大型毫米波环境中实现更有效的子信道分配。相比基线深度强化学习方法,基于 Transformer 的深度强化学习方法平均吞吐量提升超过38%[13]。不同于[13]中的子信道分配,文献[87]关注多运营商环境中的带宽预留。针对时间关键型车辆应用,[87]研究在跨运营商时变价格和覆盖条件下提前预留带宽。采用决斗深度 Q 学习框架,在满足延迟要求的同时最小化长期预留成本。时域融合 Transformer 对时变价格动态建模,支持成本感知和可靠的运营商选择。
# 波束成形
针对室内毫米波集成传感与通信系统,文献[105]研究感知辅助的波束选择,从预定义码本中为多用户提高频谱效率。一个多智能体上下文赌博机框架基于环境感知上下文自适应地选择波束成形向量,其中多模态 Transformer 将 ISAC 感知数据和用户位置特征融合为紧凑表示,实现准确且鲁棒的波束选择。相比传统深度强化学习,该 Transformer 增强框架在接近最优频谱效率策略方面提升了49.6%[105]。不同于[105]的室内场景,文献[106]研究 OFDM 蜂窝系统中基于学习的波束管理,从预定义码本中选择波束索引以提高系统吞吐量。提出一个两阶段学习框架,将波束组选择与细粒度波束索引选择解耦,实现高效波束决策。多模态 Transformer 融合异构感知数据以预测最优波束组,从而缩小强化学习动作空间并加速波束选择。但[106]仅限于单基站波束管理场景。为将波束管理扩展到 MIMO‑OFDM 系统中的多基站协调传输,文献[107]研究位置辅助的协调预编码,通过分层强化学习最大化用户吞吐量,无需信道状态信息反馈。Transformer 编码器学习子载波相关性模式,以支持频域细粒度子带级预编码决策。
# 调制
针对多蜂窝无线接入网,文献[108]研究在时变和频变无线条件下优化调制与编码方案选择的链路自适应。一个离线强化学习框架从历史数据中学习 MCS 策略而无需在线探索,决策 Transformer 将链路自适应建模为轨迹级序列预测,捕获时间依赖。相比行业基线,该 Transformer 增强离线强化学习框架平均频谱效率提升约20.7%[108]。不同于[108],文献[109]考虑高动态飞行自组网,调整调制和波形配置以应对严重的移动诱发多普勒效应。提出一个基于强化学习的框架,根据长期射频观测在 OFDM 和飞行自适应正交时频空波形之间选择,以降低误码率。时域融合 Transformer 作为核心策略模型,捕获长程时间依赖,指导自适应波形和调制决策。
网络接入与连接控制
网络接入、用户关联、调度和切换是无线网络中的基本控制功能,共同决定连接性、资源利用和服务连续性。近期研究越来越多地将 Transformer 集成到深度强化学习框架中,以处理高维度、时间耦合和结构约束的决策过程。
# 网络接入
针对动态无线多址系统,文献[110]研究分布式接入控制,站点在网络规模和流量条件变化时做出二进制传输决策。一个多任务多智能体强化学习框架提升吞吐量和公平性,基于 Transformer 的集中式评论员通过注意力机制聚合可变大小的站点信息,指导分布式决策。该 Transformer 增强深度强化学习方法达到吞吐量上限的95%[110]。
# 用户关联
针对5G蜂窝网络,文献[111]研究节能基站运行,将用户关联与休眠模式选择和天线开关协同考虑。采用离线学习框架,在满足QoS约束下最小化基站总能耗。提示决策 Transformer 从历史轨迹中学习关联和运行策略,无需在线重训练即可在不同网络规模下鲁棒泛化。相比传统深度强化学习基线,该方法用户设备丢联率降低75%[111]。虽然[111]假设每个用户只关联一个基站,但[90]考虑每个用户由多个基站服务。针对完全解耦无线接入网,[90]研究无切换的多连接用户‑基站关联以支持时变速率需求。一个分层深度强化学习框架联合优化用户‑基站关联和下行动率控制,实现无需频繁切换的无缝连接。Transformer 辅助的演员‑评论员模型捕获链路间依赖,协调关联链路间的功率分配,如图3所示。但[111]和[90]聚焦于地面蜂窝网络,不直接适用于包含无人机和卫星的非地面或混合网络。针对无人机辅助太赫兹网络,文献[112]研究高移动性下的动态用户‑小区关联。一个基于深度强化学习的框架联合优化用户关联、波束对准和多普勒补偿,提升链路鲁棒性和吞吐量。Transformer 增强模块通过注意力建模细化信道和波束相关特征,实现更可靠和频谱高效的关联决策。更广泛地,针对混合非地面网络,文献[113]研究无人机‑卫星关联以提升端到端吞吐量并降低能耗。开发多智能体强化学习框架协调动态环境中的无人机关联和移动性决策。基于 Transformer 的多智能体强化学习模型通过自回归决策建模编码联合观测并生成协调动作,实现高效的多智能体关联控制。进一步,在地面‑卫星集成网络中,文献[114]研究用户在地面基站和低轨卫星之间的动态关联,以在服务约束下提升综合能效。使用离线强化学习框架联合优化用户关联和发射功率控制以适应动态网络条件。弹性决策 Transformer 从可变长度轨迹生成决策,实现快速收敛和鲁棒泛化。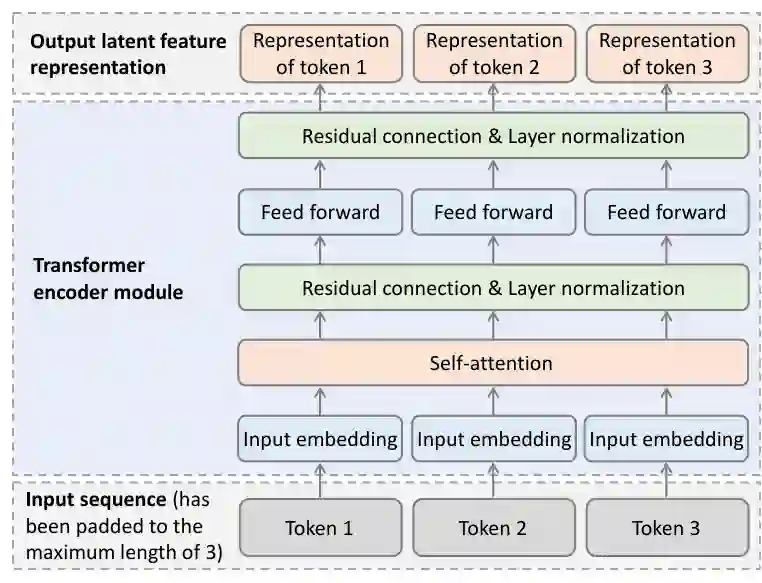
# 调度
针对多用户蜂窝下行系统,文献[115]研究多时隙资源块调度,以联合提升频谱效率和用户公平性。基于 PPO 的深度强化学习框架通过建模用户‑资源分配随时间依赖来优化多时隙调度策略。基于 Transformer 的演员通过注意力机制捕获用户序列与资源块分配之间的依赖,实现可扩展的结构化下行调度。相比传统深度强化学习方法,该 Transformer 增强 PPO 频谱效率提升约10%[115]。不同于[115],文献[116]考虑5G异构业务需求,研究动态资源块分配以降低丢包率和时延违规。一个基于深度强化学习的框架处理跨不同用户数量的逐资源块调度的大规模组合动作空间。一个仅编码器 Transformer 提供全局置换不变的状态表示,支持可扩展的动作分支 Q 学习。进一步将调度扩展到多径流量,文献[117]研究跨异构路径的动态下行流量分配以提升带宽聚合效率。基于深度强化学习的调度器根据路径异构性和时变无线条件自适应调整数据包调度比例。基于 Transformer 的吞吐量预测模块从历史测量中估计每路径可达吞吐量,从而提升调度效率和能量性能。更一般地,针对集中式多链路数据包调度,文献[88]考虑有限缓冲区和严格延迟约束下的数据包传输,丢包由缓冲区溢出和延迟违反导致。开发基于深度 Q 学习的框架,通过跨链路的动态传输调度最小化整体丢包率。仅编码器 Transformer 通过注意力聚合每链路缓冲区和信道状态,实现置换不变和可变链路数量下的可扩展调度。不同于[115]-[88],文献[118]和[119]关注工作模式调度决策。在[118]中,研究雷达工作模式识别的早期决策调度问题,系统决定继续还是停止信号观测以平衡识别准确率和决策延迟。Transformer 捕获脉冲描述字序列中的长程时间依赖,强化学习利用编码表示指导顺序停止或继续决策。在[119]中,提出离线强化学习框架用于5G蜂窝网络节能运行,根据流量条件动态激活或去激活基站小区。决策 Transformer 从历史轨迹学习小区开关控制策略,捕获长期时间依赖,实现无需在线探索的安全节能基站激活调度。
# 切换
针对可重构智能表面辅助太赫兹系统,文献[120]研究感知感知的切换,用户动态关联 RIS 子阵列以维持鲁棒的高频链路。开发了联合传感‑通信‑AI 框架以降低切换开销、增强链路可靠性并改善用户体验质量。基于 Transformer 的生成模型预测感知信息以扩充强化学习状态,实现主动且有前瞻性的切换决策。不同于[120]的室内场景,文献[91]研究5G非地面网络的切换管理,低轨卫星高移动性导致频繁切换并降低服务连续性。采用 A2C 框架在提升服务质量的同时减少不必要的切换。基于 Transformer 的轨迹预测模块提供短期移动性预测,增强强化学习状态。相比传统深度强化学习基线,该方法切换次数减少高达99%[91]。
虚拟网络功能放置
虚拟网络功能放置是网络功能虚拟化使能系统中的基本资源分配问题,决定服务功能链如何在动态约束下映射到物理基础设施。与无线层资源分配不同,VNF 放置涉及跨节点、链路和服务图的结构化决策空间和组合依赖,对依赖局部或短视状态表示的深度强化学习方法构成挑战。近期,Transformer 被集成到深度强化学习框架中,以增强全局状态建模、长期推理和结构感知决策。作为例证,近期 Transformer 增强深度强化学习方法报告了服务请求接受率提升23%[121]、SFC 编排成功率翻倍[98]、端到端延迟降低66.7%[122]以及系统能耗降低40%[123]。 从节能角度,文献[121]研究 NFV 网络中 VNF 图的动态放置,在资源和能量约束下将所有 VNF 联合映射到物理服务器。基于 Transformer 的演员‑评论员深度强化学习框架在降低能耗的同时最大化服务接受率。Transformer 捕获服务图中的有序依赖,实现一次性放置,提升效率和可扩展性。不同于[121]的通用 NFV 基础设施,文献[98]探索无人机群网络中的分布式 SFC 编排,在无需中央控制的情况下将顺序 VNF 嵌入相邻无人机。一个生成式强化学习框架减少编排时间和资源使用,提升成功率和效率。决策 Transformer 编码历史局部轨迹以提取时间和上下文特征,通过演员‑评论员学习指导稳定且分布式的 VNF 放置。从[98]的无人机群网络扩展到异构空天地基础设施,文献[122]研究卫星‑地面网络中的动态 SFC 部署,VNF 在时变拓扑和资源约束下顺序放置到异构节点。一个多模态强化学习框架通过考虑部署奖励和资源成本最大化长期收益。图 Transformer 编码网络结构和依赖,与 QoS 和全局上下文融合,指导基于 PPO 的放置决策。更广泛地,文献[123]研究5G及未来网络切片中联合 VNF 和虚拟链路放置,受延迟和资源约束。Transformer 增强的演员‑评论员深度强化学习框架提升切片接受率并降低能耗,Transformer 建模切片请求内的全局依赖,实现可扩展的一次性放置。作为在线深度强化学习方法补充,文献[124]采用离线学习在移动边缘网络中进行 VNF 放置,动态将传入 SFC 映射到边缘服务器。一个双深度 Q 网络辅助框架最小化端到端延迟和请求拒绝。决策 Transformer 建模历史放置轨迹以捕获长期依赖,并在高维空间中直接推断动作。
内容感知速率适配
内容感知速率适配根据用户需求和网络动态调整传输信息量。为应对由此产生的决策复杂性,Transformer 越来越多地被引入深度强化学习以增强多媒体传输系统中的时间建模、感知意识和长期决策一致性。例如,相比传统深度强化学习,近期 Transformer 增强深度强化学习方法在边缘视频分析中分析延迟降低27%[125],在360°视频流中用户主观体验提升57%[126]。 针对边缘视频分析,文献[125]提出自适应帧降质后再传输以平衡准确率和延迟。基于 SAC 的深度强化学习框架联合优化帧质量和带宽分配。Transformer 增强的演员‑评论员架构编码历史状态‑动作序列以捕获长期依赖,从而在时变内容特征下实现更好的准确率‑延迟权衡。不同于[125]的视频分析场景,文献[126]关注面向用户体验的360°视频流,进行视口感知的码率自适应。基于 MAPPO 的框架利用预测的用户视点协调区域级码率自适应。一个多模态时空注意力 Transformer 预测视点轨迹和概率,支持鲁棒、细粒度的码率控制。进一步扩展到实时扩展现实视频传输,文献[127]研究在严格延迟约束下联合视频质量选择和无线资源分配。一个分层 MAPPO 框架进行多时间尺度的源‑信道联合优化。多智能体 Transformer 通过基于注意力的协调建模无线资源块间的交互,支持可扩展且一致的多智能体决策。与[127]类似,文献[128]探索协调的码率自适应和无线调度以提升用户体验。一个跨层框架解耦不同时间尺度的优化,Transformer 增强 PPO 模块从历史网络状态捕获时间模式以稳定码率自适应。更一般地,针对混合频段5G网络上的超高清视频流,文献[129]研究在高度变化吞吐量条件下每个视频块的码率控制。基于 SAC 的深度强化学习框架最大化长期用户体验,Transformer 编码历史流状态以捕获时间依赖。不同于上述工作,文献[130]针对水下无线传感器网络,研究传感器精度控制的量化比特自适应。基于 D3QN 的框架调整每节点量化级别以在保持跟踪性能的同时最小化能耗。Transformer 通过自注意力提取结构化状态特征,在动态水下环境中实现稳定高效的比特分配。
计算与通信联合资源分配
计算与通信联合资源分配已成为动态网络条件下的关键问题。与单域资源分配不同,联合优化引入高维决策空间和强资源间依赖,对传统深度强化学习方法构成重大挑战。近期,Transformer 被集成到深度强化学习中以增强全局表示学习、结构化推理和长期依赖建模,从而实现更有效的联合资源管理。 在[131]中,传输功率、带宽和计算资源被联合优化,一个大型推理 Transformer 评论员(ReaCritic)被集成到深度强化学习框架中以增强状态‑动作价值估计和泛化能力,相比原始深度强化学习基线,最终回合收益提升高达170%。不同于[131],文献[132]考虑移动边缘计算网络中的动态任务到达,联合优化任务卸载、缓存和资源供给。一个在线集中式深度强化学习框架在无未来任务先验知识的情况下最小化长期任务执行时间,基于 Transformer 的演员‑评论员处理高维状态‑动作空间,实现可扩展的联合资源管理。从长期调度角度,文献[133]研究边缘‑云环境中的动态资源分配,将传入任务分配到分布式边缘服务器。一个改进的 SAC 框架降低任务拒绝率并提升系统效率,Transformer 模块嵌入演员‑评论员架构以编码长调度序列和全局系统状态,实现更自适应的资源分配。
经验总结
从上述综述研究可以总结出 Transformer 在基于深度强化学习的资源分配中发挥有效性的四个关键因素。 第一,长期时间依赖建模。资源分配决策通常与历史信道、业务负载和先前动作有关。Transformer能够利用自注意力建模较长时间范围内的相关性,为轨迹依赖的资源决策提供上下文。 第二,多智能体依赖建模。自注意力能够聚合不同用户、链路或智能体的信息,支持对大规模网络中实体间依赖关系的统一表示,并适应动态、异构的拓扑。 第三,结构化动作依赖建模。虚拟网络功能放置、资源块调度等问题具有组合决策特征,Transformer可捕获动作之间的结构关系,因此适合处理一次性放置或多资源联合选择。 第四,多源信息融合。基于注意力的融合可以联合利用感知信息、预测结果和数字孪生状态,形成更完整的上下文表示,支持自适应、前瞻性的资源决策。 这四项因素分别对应资源分配中的时间变化、实体耦合、组合动作和异构信息。
4 Transformer-based RL for Computation Offloading / 基于 Transformer 强化学习的计算卸载
计算卸载是边缘智能系统的核心问题之一,传统强化学习(RL)算法虽能有效求解,但在动态、高维的无线环境中常面临训练不稳定、可扩展性有限等挑战。基于 Transformer 与扩散模型的强化学习框架近年来被引入,用于改善复杂动作空间下的状态表征与决策能力。本节按应用场景对文献进行组织,涵盖计算资源分配、计算通信联合优化、移动性感知卸载及面向 AI 服务的卸载。任务依赖关系在各场景中被作为建模特征处理,这种场景驱动的分类有助于全面理解边缘智能系统中的卸载设计。
计算资源分配
本类工作聚焦于以计算为中心的决策问题,如异构边缘-云与数据中心环境下的处理器分配与任务调度。研究的核心问题是如何在资源受限且状态动态变化的环境中,利用 Transformer 增强的强化学习提升对全局工作负载、时间序列特征以及跨模态时空信息的建模能力,从而优化调度策略的稳定性与性能。
# 集中式计算调度与整合
针对软件定义网络(SDN)支持的云环境中虚拟机(VM)整合与资源管理问题,文献[134]构建了一个Transformer增强的深度强化学习(DRL)框架,将Transformer嵌入策略学习过程,以捕捉网络与资源状态之间的长程依赖与相关性。随着计算需求增长与操作约束复杂化,分布式数据中心的层级计算功率调度在[92]中被研究,提出了Transformer嵌入的PPO框架:Transformer在处理变长系统状态的同时,捕获任务间的时序关系。文献[135]研究动态边缘计算环境下的全息视频通信,如图4所示,其架构采用Transformer进行多模态时空特征提取,而决策由分层RL控制器执行。在此设计中,RL处理不同时间尺度上的决策,Transformer作为辅助组件增强时空动态建模,而非直接近似策略或价值函数。此类方案的优势在于通过注意力机制提升对全局状态的理解,局限在于计算开销较高,且层次化控制需精心设计协调机制。
# 分布式或协作式资源分配
在B5G/6G车联网(IoV)场景中,文献[136]针对高并发、时延敏感的运输任务计算资源分配问题,提出了动态自反馈(DSF)资源分配框架,集成Transformer自注意力机制以强调分配过程中关键资源特征。文献[137]引入基于RL的联合概率分布采样神经网络(JPDS-NN),模型采用图Transformer与注意力机制增强的编码器-解码器架构,将路由问题建模为马尔可夫决策过程,并利用PPO进行训练。文献[138]聚焦分布式编码机器学习系统中的工作者选择与工作负载分配,提出基于多智能体Transformer的工作负载分配与工作者选择(MAT-AS)方案,将问题建模为部分可观测马尔可夫博弈,并结合多智能体RL与Transformer模块。文献[139]研究边缘-云环境下异构IoT应用的适应性调度,提出Transformer增强的分布式DRL方法TF-DDRL,在Actor-Critic架构中集成Transformer以捕获相互依赖任务间的长期依赖关系,从而增强决策过程中的时序与结构表征。文献[140]提出基于异构图神经网络的DAG任务重调度方法,采用Transformer架构与Actor-Critic RL。分布式协作方案的优势在于可扩展性与鲁棒性,Transformer帮助建模智能体间依赖,但多智能体训练中的非平稳性及通信开销仍是挑战。
计算与通信联合资源分配
该类别研究计算卸载中计算决策与通信资源分配紧密耦合的问题。核心挑战在于无线信道、队列状态与计算负载的时变性与相互影响,Transformer在增强状态表征、捕获跨域交叉依赖方面发挥了关键作用。
# 卸载与无线资源联合分配
针对MEC环境中时延敏感IoT应用的卸载问题,文献[14]提出融合Transformer与PPO的计算卸载方法TPTO,通过Transformer增强策略学习,实现动态边缘条件下依赖任务的协同卸载。文献[141]考虑分布式MEC中的时延敏感任务卸载,问题建模包含时变无线条件、异构计算资源及严格时延约束,基于Transformer辅助的DRL框架在策略学习中捕获网络、排队与计算状态间的长程依赖。文献[142]提出约束决策Transformer(CDT)框架,基于离线预训练与在线微调,联合优化自主飞行器轨迹与计算资源分配,在电池容量与服务约束下最大化公平吞吐量。CDT将顺序优化问题建模为约束马尔可夫决策过程,通过将RL转化为序列建模任务实现序列级策略。文献[93]研究卫星边缘计算系统中的任务调度与资源管理,提出基于PPO的调度框架,集成多维注意力机制,RL策略根据注意力增强的状态表征决定调度动作。文献[143]针对MEC中任务数动态变化的情况,提出基于Transformer的DRL框架,支持任务数量自适应的决策,Transformer实现任务序列可扩展建模。文献[144]提出自注意力增强的多邻域PPO框架,通过不同粒度的邻域建模捕获任务与资源间的交互。联合分配方案的优势在于同时优化通信与计算,Transformer有效编码任务-信道相关性;局限是模型复杂度高,且在大规模节点下训练效率仍需提升。
# 分布式系统中的计算通信协同
在工业信息物理系统(ICPS)中,文献[15]提出云边协同的分布式Transformer Actor-Critic(DTAC)算法,应对混合、高维动作空间。Transformer用于增强复杂系统状态的处理与表征,实现可扩展的自适应卸载。文献[145]基于Transformer增强的多智能体深度强化学习(MADRL)提出可迁移联合任务卸载与多信道接入(T2OMCA)算法,仿真显示在变边缘节点与AGV数量场景下平均任务完成率超90%。文献[146]提出JROC框架,集成基于智能合约的激励与自适应Transformer的MARL算法,利用Transformer集中式评论家网络捕获长程依赖与智能体交互。文献[147]在5G专网中引入区块链技术,通过Transformer辅助MARL求解资源分配与卸载问题。协同方案的优势在于跨节点依赖建模,提升全局效率;但多智能体协调机制的设计与计算开销是需要权衡的因素。
移动性感知与动态卸载
移动性感知卸载针对用户、车辆或无人机移动引发的时变系统动态,强调在高度动态、非平稳环境中自适应任务放置与资源配置。Transformer在此类问题中的作用在于编码移动性序列、捕获时空依赖,从而提升策略对时变条件的鲁棒性。
# 用户与车辆移动性感知卸载
文献[148]研究多智能体移动增强现实(MAR)系统中的时效性资源控制,导出AoAI闭式表达式,提出凸嵌入Transformer QMIX(CTQMIX)算法。凸优化确定带宽分配,Transformer架构捕获观测与动作间的时序依赖。文献[89]提出移动性感知生成式计算卸载框架MGCO,基于Transformer驱动的序列到序列深度Q网络,Transformer使能对移动性序列的并行上下文推理。文献[149]提出数字孪生辅助的车辆边缘计算框架,采用基于Transformer评论家的多智能体PPO(TC-MAPPO)算法联合优化数字孪生放置与资源分配,实验显示其最终平均奖励优于标准MAPPO与MADDPG。此类方案的优势在于能主动适应移动模式,Transformer提升序列推理质量;局限是需要数字孪生或预测模型,增加了系统复杂度。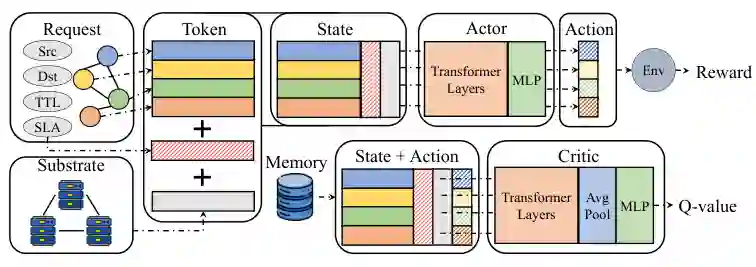
# 无人机辅助动态卸载
文献[95]研究自主飞行器(AAV)网络中深度神经网络分区、边缘卸载与混合动作决策问题,提出Transformer增强的多智能体混合动作PPO(TE-MHAPPO)。仿真结果表明,相比基线MHAPPO,TE-MHAPPO在考虑任务时延与能耗的综合成本至少降低12.1%;随预测时间增加,TE-MHAPPO性能退化幅度控制在基线MHAPPO的55.2%以内,表现出更高的稳定性。文献[150]提出基于异构对齐的时空图强化学习框架HASTG-RL,利用动态时空图持续更新环境状态,通过Transformer异构对齐机制处理UAV异构性,并设计独立评论家网络实现多目标优化。该方案的优势在于处理无人机异构性,但动态图的构建与更新带来额外开销。
# 时变卸载
文献[151]研究多域6G网络中SFC划分问题,考虑时延与资源约束。如图5所示,Transformer层嵌入Actor和Critic网络,编码结构化状态表征并实现序列感知的策略与价值学习。该Transformer赋能的Actor-Critic RL框架使SFC划分决策能够感知序列依赖性。时变卸载方案的优势在于对网络功能链中顺序依赖的精确建模,但需要处理跨域信息交互的额外信令。
面向人工智能服务、生成式人工智能与大模型的卸载
本节聚焦于由AI服务、AIGC应用及大模型推理负载驱动的卸载问题,主要目标是服务级编排,包括模型选择、推理放置与资源感知服务迁移。Transformer在此类场景中或作为DRL的增强组件,或直接作为大模型被集成。
# 大模型推理卸载
文献[152]研究IoV系统中面向大规模数据处理与严格时延约束的任务卸载,将基于Transformer的大模型与DRL集成:DRL管理策略优化,大模型增强复杂卸载条件下的动作推理与适应性。同时引入任务分类框架,按计算复杂度、数据规模与时间敏感度划分任务,实现差异化卸载决策。两阶段方案中,第一阶段基于多智能体PPO确定模型推理与卸载决策,第二阶段基于序列最小二乘优化进行资源分配。该方案的优势是将大模型推理能力引入卸载决策,提升复杂场景适应力;局限是模型规模带来的计算与存储开销。
# 面向生成式人工智能服务的编排
文献[153]研究无线网络中AIGC服务的部署,利用联邦学习实现分布式模型训练、微调与推理,保护用户隐私。文献[154]提出面向车辆元宇宙环境的AIGC服务供应方案,将计算密集型内容生成任务从资源受限车辆卸载至AIGC服务提供商。问题建模为不完全信息下的斯塔克伯格博弈:RL确定博弈互动,Transformer增强博弈中复杂决策依赖关系的建模。此类方案的优势是在隐私保护与服务质量间取得平衡,Transformer帮助建模层次化交互;但博弈均衡求解与实时性要求存在冲突。
# 人工智能驱动的数字孪生管理
文献[155]研究车辆元宇宙中资源分配与车辆孪生(VT)迁移问题,通过基于市场协调的属性感知拍卖机制,联合考虑位置、声誉等货币与非货币属性。两阶段匹配中,RL确定拍卖控制决策,Transformer模型辅助学习自适应机制,而非直接近似卸载或迁移策略。该方案的优势在于利用经济模型与AI结合,但Transformer作为辅助组件的增益需进一步验证。
缓存、内容交付与服务连续体
文献[156]提出云辅助边缘计算中的主动缓存与内容更新策略,结合超维计算、Transformer预测与多智能体RL的HT-PAD框架。RL控制缓存策略,Transformer作为辅助组件增强需求预测。文献[157]针对D2D通信环境中的协作内容缓存,提出基于循环神经网络与基于Transformer的两个学习框架,后者利用注意力机制建模用户需求模式。此类方案的优势在于利用Transformer捕获历史数据中的长程依赖,提升缓存命中效率;但需求预测的准确性受限于数据质量,且缓存替换策略需结合实时反馈。
工作流感知与结构化任务卸载
文献[158]研究IoV系统中基于DAG表示的任务依赖卸载,提出DRL框架结合表征学习编码任务依赖与执行状态,将任务图转化为紧凑表征以便顺序卸载决策。文献[159]针对异构CPU-GPU MEC中的批处理场景,提出分布式Transformer联邦软演员-评论家(TFSAC)框架,Transformer编码器学习智能体间上下文关系,联邦学习协调分布式训练。文献[160]在停驻车辆扩展的MEC架构中,利用Transformer与LSTM集成捕获任务到达的时序模式与容器化节点间关系。此类方案的优势在于显式处理任务依赖结构,提升卸载调度的整体性能;但DAG建模复杂度随任务数增长,且联邦学习引入通信与隐私协调开销。
通用协作式与分布式卸载
通用协作卸载框架关注多个边缘节点或智能体间的分布式决策,不局限于特定系统约束,强调在不确定性与异构性下的协作或分散资源管理。
# 完全分布式协作卸载
文献[161]研究D2D协作内容缓存,提出基于Transformer的框架利用注意力机制建模用户需求模式,Transformer捕获历史数据中的长期依赖,缓存决策由学习模型导出。文献[162]提出通用状态-动作空间自适应DRL框架SASA,利用Transformer多头注意力机制灵活编码变维状态与动作,并与现有Actor-Critic算法无缝集成。基于SASA的任务卸载与资源分配算法SASA-TORA被开发。完全分布式方案的优势在于适应动态节点数与任务数;但完全分布式训练可能面临收敛慢与局部最优问题。
# 联邦或学习式分布协调
文献[163]在动态IoV网络中引入数字孪生辅助框架,集成自适应联邦学习(AdFL)、多智能体深度RL与生成AI。条件变分自编码器(CVAE)生成上下文感知表征,Transformer层捕获长程依赖。该方案的优势在于结合联邦学习的隐私保护与Transformer的序列建模能力;但联邦学习与RL的联合优化面临通信效率与异构数据挑战。
# 不确定环境下的混合系统级卸载
文献[164]研究动态内容分发网络中的自适应缓存,提出基于Transformer的RL模型T-CacheNet,RL确定缓存策略,Transformer增强内容需求时序相关性建模,优化缓存与替换决策。混合方案的优势在于适应时变需求,但缓存的非平稳性要求模型具备持续学习能力。
经验总结
上述研究表明,计算卸载正在从孤立的计算调度转向系统级设计。随着场景扩展到无线边缘计算、云边端协同和移动性感知系统,核心挑战是建模高维、时变且相互关联的系统状态。Transformer增强学习主要用于捕获任务依赖、时间动态、变长输入和智能体间交互,从而改善卸载策略的可扩展性与鲁棒性。 与此同时,大模型推理和生成式人工智能等面向人工智能的服务正在推动卸载设计转向服务感知编排。现有研究仍以具体应用为主要驱动,对方法的泛化能力与收敛性质尚缺少充分的理论理解。
5 Transformer-based RL for Routing and Trajectory Control / 基于 Transformer 强化学习的路由与轨迹控制
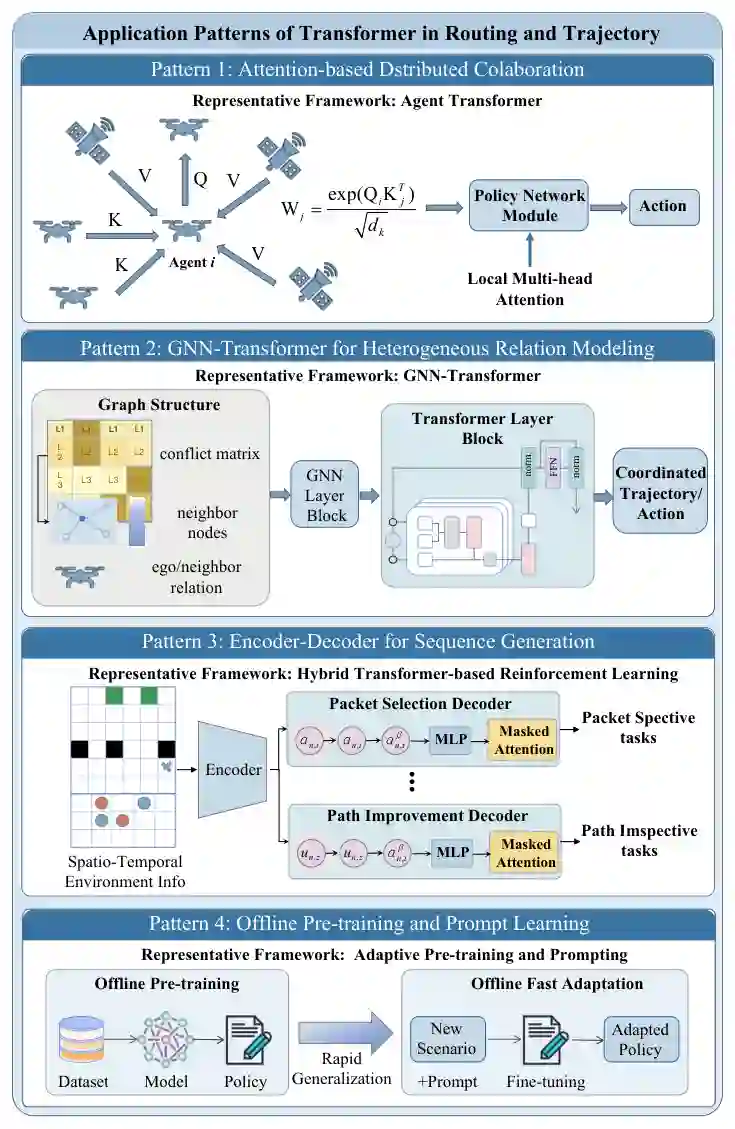
长时域与多智能体路由及轨迹控制
大规模无线、机器人及空中系统中的路由与轨迹决策面临长时域规划、强时空耦合以及多智能体与网络实体间的复杂交互挑战。传统深度强化学习(DRL)方法,尤其是基于多层感知机或循环架构的策略,在捕捉长程依赖、动态拓扑变化以及由移动性、资源约束和多智能体协调所导致的高维联合决策空间方面存在不足。针对这些问题,近期研究将Transformer架构嵌入DRL框架,利用自注意力机制建模长期时间相关性、空间关系以及智能体间的依赖关系。相关工作覆盖从单智能体运动规划到多无人机协调、再到动态不确定环境下的网络级路由,表明Transformer能够为可扩展且鲁棒的长时域控制提供有效表征。代表性文献总结于表VIII。
# 长时域轨迹规划
早期Transformer增强的DRL研究聚焦于提升动态环境中移动智能体的长时域轨迹表征。通过自注意力机制,文献[16][17][165]捕捉了传统MLP或RNN策略难以建模的时间相关性与空间依赖性,使得机器人、无人机及自动导引车(AGV)的轨迹决策更加平滑和鲁棒。具体而言,[16]将自注意力集成到软演员-评论家(SAC)框架中用于自主机器人导航,通过序列激光雷达观测捕捉长程时间依赖,提升了轨迹平滑度、导航成功率以及在动态部分可观测环境中的泛化能力。[17]将这一思路拓展至空中网络,提出基于注意力的循环多智能体强化学习(MARL)框架,用于流体天线系统(FAS)赋能无线网络中三维无人机轨迹和定位优化。在协作学习框架下,该方法捕捉了空间相关性以及无人机运动与可重构天线状态之间的耦合,实现了更准确的3D轨迹决策。[165]则针对可变规模的多无人机覆盖率控制任务,通过Transformer组织变尺寸的蜂群状态,实现了置换不变决策和跨蜂群规模的自适应。 后续研究将这一范式扩展到资源耦合场景,其中轨迹规划与带宽分配、能量收集或信道分配联合优化。文献[166]–[169]表明Transformer表征能够捕捉随机约束下移动性与通信资源之间的长期耦合。[166]研究了李雅普诺夫引导的Transformer增强DRL,用于能量收集移动群智感知系统中的联合带宽分配与多无人机轨迹优化,利用李雅普诺夫漂移加罚框架将随机优化问题转化为可处理的在线控制,实现了能量不确定下的高效长时域轨迹规划。[167]研究无线电力传输辅助物联网中的无人机轨迹优化,提出基于注意力机制的DRL框架用于大规模资源约束规划,图注意力编码器从图结构物联网输入中捕捉空间相关性和异构服务需求,在联合能量与存储约束下生成可扩展且能效优化的轨迹。 在连续资源分配之外,[168]研究了事件驱动的Transformer强化学习框架,用于多无人机通信系统中的联合轨迹设计与信道分配。事件触发机制选择性更新轨迹与频谱分配动作,在捕获长期时空依赖的同时降低了控制开销。[169]进一步研究了Transformer增强DQN用于基于信息的任务(如能量和目的地约束下的无线电地图更新)中的无人机轨迹优化。将该问题建模为具有稀疏奖励的有限时域MDP,通过将Agent Transformer集成入dueling DQN,捕捉无人机状态与测量位置之间的依赖关系,并利用奖励塑造缓解稀疏奖励问题,实现了长时域规划。 层次化Transformer增强DRL通过将长时域规划与细粒度轨迹执行解耦来提升可扩展性。代表性应用包括仓库AGV调度与无人机辅助通信,其中层次化决策结构和基于序列的策略学习使得在长规划时域下实现高效协调[170][99]。[170]提出层次化Transformer强化学习框架用于大规模仓库中的AGV调度与轨迹协调。两级结构包括高层Transformer策略(负责长时域任务分配与拥塞模式建模)和低层控制器(负责细粒度执行),通过自注意力建模AGV间交互和时间依赖,比扁平DRL方法提升了可扩展性和调度效率。[99]进一步采用Decision Transformer(DT)用于动态用户群体下的无人机辅助通信,将联合无人机轨迹规划与用户调度重构为序列建模,引入注意力机制、提示条件化和能量感知令牌,处理了长时域信息年龄(AoI)优化和长期能量约束,并在未见部署场景中表现良好。 近期研究体现出Transformer作为长时域轨迹优化的统一表征的趋势,从移动控制扩展到资源耦合和层次化决策。本文总结的四种应用模式见图6。然而,仍存在明显空白:多数工作聚焦于单智能体或弱耦合多智能体环境,完全分布式和大规模协作的轨迹与路由问题研究不足;许多Transformer增强DRL框架依赖任务特定架构和手工状态表征,限制了跨移动性场景和网络场景的迁移能力;此外,关于随机约束下基于Transformer策略的收敛性、稳定性和样本效率的理论理解仍然有限,尤其在安全关键应用中。这些挑战凸显了对更具泛化能力、理论扎实且通信感知的Transformer增强RL框架的需求。
# 多智能体与冲突感知轨迹控制
随着轨迹优化向多智能体与高密度耦合方向发展,Transformer增强DRL被拓展为显式建模智能体间交互与协调约束。在协作无人机部署与监控中,Transformer通过基于序列的决策建模捕捉智能体间的长时域空间依赖,实现稳定且覆盖率感知的轨迹生成[96]。为应对异构无人机网络中的冲突消解,层次化图Transformer DQN框架显式地将无人机间交互与碰撞风险编码到多级决策过程,提升了密集空域中的可扩展性和鲁棒性[97]。同时,社会Transformer架构被探索用于多智能体轨迹预测,提供交互感知运动建模以支持下游轨迹规划与决策[171]。 文献[96]研究Transformer增强RL用于协作无人机部署与轨迹优化,将多节点监控建模为序贯决策过程。自适应Transformer架构捕捉无人机间的长时域空间依赖并生成协调部署动作;通过将策略学习转化为序列预测,该方法相比传统DRL实现了更稳定的部署和更好的覆盖性能。 针对密集空域中的冲突感知轨迹控制,[97]提出层次化图Transformer强化学习框架用于异构无人机网络。图Transformer建模无人机间交互、碰撞风险及时空耦合,多级决策结构将冲突消解分解为层次化控制层,相比扁平多无人机DRL方法提升了可扩展性和鲁棒性。在感知层面,[171]提出簇内增强社会Transformer用于拥挤环境下的多智能体轨迹预测。簇内注意力显式建模社会交互,捕捉细粒度时空依赖和智能体级影响模式,为下游多智能体规划和冲突感知决策提供了交互感知运动预测。
# 网络级路由与联合资源优化
超越运动级控制,近期研究将Transformer增强DRL扩展到动态拓扑和组合决策空间下的网络级路由与联合资源优化。在AAV辅助交通网络中,基于Transformer的策略与原始-对偶PPO集成,用于在能量和移动性约束下联合优化轨迹规划、内容路由和无线资源分配[172]。在LEO卫星系统和超密集无人机巡检等大规模动态网络中,基于图和编码器-解码器的Transformer捕捉长程拓扑依赖和优先级感知路由结构,实现了可扩展路由[173][174]。最新工作提出对比图Transformer PPO,提升了对拓扑变化和链路故障的鲁棒性,表现出更强的跨异构网络泛化能力[175]。 文献[172]研究Transformer增强DRL用于AAV辅助交通网络中的联合路由与轨迹优化。通过将多尺度生成Transformer嵌入原始-对偶PPO框架,模型在能量和移动性约束下联合优化空中轨迹规划、内容路由和无线资源分配。Transformer捕捉移动性和网络层间的长程时空依赖,使动态交通环境中的自适应路由成为可能。 为应对大规模且快速变化的拓扑,[173]研究LEO卫星网络中的分布式路由,采用基于Transformer-MIX的多智能体DQN框架。将该架构集成到协作多智能体学习中,能够建模长程时间动态和星间依赖,在频繁拓扑变化下实现可扩展路由。[174]进一步研究超密集无人机巡检中的可扩展路由,将巡检规划建模为带优先级的旅行商问题,其基于Transformer的路由方法结合图分割、编码器-解码器Transformer、并行RL和自适应大邻域搜索,捕捉长程空间依赖和优先级感知路由,同时降低复杂度并保持解质量。 超越可扩展性,[175]提出对比图Transformer PPO框架以提升动态拓扑和链路故障下的路由鲁棒性。通过将边增强图Transformer集成入PPO路由策略,并引入对比组路由进行跨拓扑对齐,该方法相较于传统基于GNN的DRL路由方法,在泛化能力和鲁棒性上有显著改善。 现有研究显示出从运动级轨迹控制向网络级路由与联合资源优化的转变,Transformer增强DRL方法(特别是多智能体DQN和PPO)利用注意力捕捉长程拓扑依赖和跨层移动性-通信耦合。然而,多数框架仍依赖全局状态信息的集中式训练,部分可观测下的分布式路由和轨迹优化研究不足;路由、轨迹和资源决策通常在同一时间尺度优化,多时间尺度Transformer架构尚未充分研究;跨异构网络的拓扑不变和分布鲁棒路由策略仍然缺乏。此外,在随机拓扑演化和资源约束下的收敛性、稳定性和安全性的理论保证仍显不足,阻碍了在安全关键场景中的部署。
序列建模与风险感知路由及轨迹控制
# 基于序列的路由与决策
近期工作进一步将Transformer增强RL拓展至序列建模范式,路由与轨迹决策被重构为条件序列预测,而非逐步策略学习。Decision Transformer和编码器-解码器Transformer架构直接将状态-回报-约束序列映射到动作轨迹,提升了训练稳定性和长时域信用分配。这些方法在无人机控制、车辆路由和无线资源调度等不同问题规模和目标下展现出强泛化能力。 早期研究主要在通信-轨迹联合控制中探索DT风格的学习。[176]通过将联合轨迹与相移控制建模为序贯决策过程,采用带因果掩码的DT处理非马尔可夫状态转移。基于序列的策略相比DDPG减少了训练轮次,同时保持了有竞争力的传输性能。类似地,[177]提出基于DT的自适应架构用于联合无人机航迹设计、工作负载调度和用户关联,序列建模使得云预训练和边缘微调成为可能,加速收敛并提升跨场景泛化。 在无线通信控制之外,序列建模Transformer还被应用于带结构约束的组合路由。[178]解决带时间窗的电动汽车路径问题,用基于异构交叉注意力的Transformer替换RNN解码器,在充电站和客户节点之间建模,提升了长程依赖建模和跨实例规模的泛化能力。[179]进一步将基于Transformer的策略融入多目标车辆路由,序列感知表征使得旅行成本和服务满意度同时优化,相比传统DRL在训练复杂度降低的同时取得更优的Pareto性能。 尽管有这些进展,基于序列建模的Transformer RL仍面临若干局限。多数研究依赖离线或半离线的轨迹风格训练信号,且假设序列分布相对稳定,限制了在快速变化环境中的适应性。此外,约束处理和安全性保证通常通过隐含学习而非显式强制实现,在实时路由和控制中产生可行性风险。发展在线自适应DT、显式约束集成以及更强分布偏移鲁棒性仍是一个开放方向。
# 风险与约束感知的路由和轨迹优化
另一个新兴方向将Transformer增强DRL整合到风险感知、约束驱动和多目标的路由与轨迹优化中。这些研究在约束马尔可夫决策过程(CMDP)、能量、安全、拥塞或多目标权衡下建模路由与控制,利用Transformer架构捕捉约束、目标与智能体状态之间的依赖,提升了协作路由、无人机蜂群和拥塞感知网络控制中的鲁棒性和约束满足能力。 早期工作出现在显式风险与约束感知路由中。[180]研究无人机与无人车(UAV-UGV)的协作路由,考虑随机燃料消耗,将任务建模为约束MDP并集成编码器-解码器Transformer策略,其中多头注意力捕捉任务点与资源风险之间的关系,相比启发式基线降低了任务时间和约束违反。 基于Transformer的约束感知RL也被应用于目标驱动和感知受限导航。[181]在GPS拒止环境中用Transformer模块增强PPO,改进了高维部分可观测状态下的决策。[182]进一步引入目标引导Transformer,根据目标状态调节场景编码,提升了数据效率、鲁棒性和仿真到现实泛化能力。 多项研究将通信和能量约束纳入Transformer增强控制。[183]联合优化无人机轨迹和RIS相移用于移动群智感知,改善了长时域能量-吞吐量权衡。[185]结合基于Transformer的时间序列特征提取与基于RL的路径选择和带宽调度,用于电力物联网多路径拥塞控制,提升了吞吐量、时延和丢包率。[184]类似地将时序融合Transformer预测器与DQN路由集成,用于软件定义网络中的拥塞自适应控制。 风险与约束感知建模进一步扩展到多智能体与对抗性蜂群问题。[186]将Transformer自注意力集成到多智能体RL中用于无人机蜂群对抗,缓解了稀疏梯度和局部最优问题。[187]将Transformer RL应用于对抗性无人机蜂群资源调度。[188]–[190]进一步将Transformer协调扩展到受限空中走廊、协作多目标检测和AoI感知多无人机轨迹生成,突显了在复杂蜂群控制中的可扩展性。 尽管有这些进展,仍存在若干局限。多数约束感知Transformer RL方法依赖软惩罚或奖励塑造而非显式可行性保证,限制了在严格约束路由和控制中的安全性。风险和约束信号通常以隐含方式嵌入注意力特征,缺乏结构化推理,降低了可解释性和可验证性。因此,开发具有显式约束建模、可验证安全边界和在线风险适应的Transformer-RL框架仍然是一个重要研究方向。
经验总结
基于上述研究,可提炼出关于Transformer架构在深度强化学习中对路由与轨迹控制的若干共同经验。首先,基于Transformer的策略显著提升长时域依赖建模和跨实体耦合表征能力,这对于延迟奖励和结构化状态空间的任务至关重要。注意力机制在捕捉时空相关性和交互结构方面效果突出,而这些是MLP或RNN策略难以编码的。其次,当决策依赖结构化上下文(包括多智能体交互、图拓扑、资源约束和目标条件状态)时,Transformer增强DRL具有明显优势。图Transformer、层次化Transformer和Decision Transformer能使模型结构与问题结构对齐,提升了跨不同网络规模和智能体数量的可扩展性和泛化能力。第三,DT风格的序列建模通过将策略学习重构为条件序列预测,降低了训练不稳定性,通常能改善收敛性和跨场景迁移,尤其在预训练或离线轨迹数据可用时。然而,Transformer增强DRL也带来了模型复杂度、训练成本和数据需求的增加,且约束处理通常依赖奖励塑造或软惩罚,无法保证可行性、安全性或可解释性。未来工作应将Transformer表征与显式约束建模、结构化先验和轻量自适应机制相结合。
6 Transformer-based RL for Network Security / 基于 Transformer 强化学习的网络安全
在分布式网络实体间进行协作决策时,通常需要跨多样协议交换大量异构数据,这不仅扩大了攻击面,也使得管理和安全防护变得极为复杂[191]-[193]。在此类动态对抗环境下,安全威胁可被组织为以下分类:(i)数据完整性攻击,破坏信息的机密性、完整性或来源(如窃听、注入、虚假数据操纵)[194],[195];(ii)面向学习的对抗攻击,针对决策与学习/推理管线(如对抗路由/操纵、对抗性机器学习行为)[196],[197];(iii)资源与基础设施攻击,耗尽带宽、计算或能量(如资源耗尽)[198]-[200];(iv)通信与干扰攻击,在部分可观测条件下降低链路可靠性或保密性[18],[194];(v)其他安全问题,包括故障和微架构泄露,破坏边缘设备的信任锚点[201],[202]。为应对这一演进中的对抗格局,基于学习的防御策略[203]-[205]被广泛采用。监督方法在标签充足时能实现高精度,但难以应对新型或持续演变的攻击;无监督与半监督异常检测虽降低标签需求,但在高度非平稳环境中假阳性偏高。基于RL的防御通过交互学习自适应策略,能够实现主动缓解与资源感知的运行时决策。近期工作进一步将Transformer架构融入DRL,以更好编码高维观测并捕获长程依赖,由此催生了Transformer增强DRL的分类体系与对比总结(表X)。
面向学习的对抗攻击
深度学习网络极易受到对抗性攻击者的威胁,这类攻击者通过精心构造的噪声降低模型性能并改变推理结果。已有大量攻击方法被提出用于破坏深度学习与人工智能系统,其主要目标是通过未经授权的干扰(操纵模型输入或改变系统处理信号)违反系统完整性,最终导致错误预测与错误决策[197]。 在D2D通信场景中,文献[196]针对对抗路由攻击,提出一种融合图注意力网络(GATN)的量子多智能体强化学习(QMRL)框架。注意力机制编码动态路由上下文与恶意行为模式,使DRL智能体能够学习绕过受损节点、维持网络连通性的自适应路由决策。现代网络环境日趋复杂与分布式化,网络威胁数量持续增长。另一方面,文献[207]将Transformer与门控循环单元(GRU)、长短期记忆(LSTM)和循环神经网络(RNN)模型结合,为训练和评估基于DDQN的DRL对抗智能体提供多样化的架构基础,从而更全面地评估模型在自适应规避攻击下的鲁棒性。文献[208]中,无人机可能暴露于试图通过观测飞行轨迹推断真实任务目标的对抗性智能体。为解决此类直接对抗威胁,作者提出一种融合RL的欺骗性路径规划框架。具体地,将针对多智能体的局部注意力机制与演员-评论家策略梯度算法结合,使无人机既能学习竞争策略也能学习合作策略。训练后的策略在不同环境中展现出强泛化能力,无需额外微调。 在文献[206]中,作者将航天器威胁规避建模为基于DRL的决策问题。集成基于Transformer的注意力机制以关注关键威胁目标,从而改善状态表示,提升策略学习。该组合增强了多目标与集群场景下的规避效率、策略泛化能力和资源利用率。然而,由于现代系统的动态性、攻击的长期持续、间歇性与隐蔽行为,以及攻击者的自适应学习能力,这些方法在应对不断演变的威胁时效果逐渐降低。在此背景下,基于Transformer的PPO和RL–XGBoost凭借其连续在线学习能力以及在执行防御动作前捕获系统状态的能力,已成为未来对抗检测与缓解的极具前景的方向。模型的动作先被收集作为Transformer的输入,随后馈入单个智能体(称为通用防御蓝方智能体)[205]。
资源与基础设施攻击
Transformer增强的DRL也被应用于操纵或耗尽通信、计算和能量资源的攻击。在电动汽车充电基础设施中,文献[203]不仅将攻击视为对抗学习问题,还将其视为对系统资源信息的操纵。具体地,作者将荷电状态(SoC)捏造建模为零和博弈:攻击者与防御者之间。采用基于PPO的Transformer策略联合训练入侵检测机制与鲁棒充电调度器,从而减轻对共享能量资源的恶意利用。在卫星-地面边缘系统中,文献[209]利用带有自注意力的高维PPO智能体,在多个相互冲突的目标(时延、能耗、可靠性)下优化隐私保护任务卸载,使系统能够抵御对抗性或错误配置的资源需求。 在基于SDN的安全领域,文献[212]提出一种强化Transformer学习框架,用于检测边缘云中的极短间歇分布式拒绝服务(VSI-DDoS)攻击。通过将时间注意力机制与DQN结合,该方案捕获导致服务质量下降但能逃避传统检测方法的短时突发流量模式,从而增强边缘环境中服务层DDoS弹性。此外,Deep-Shield[211]在一个SDN平台上进行评估,该平台主要作为实现动态重构(如IP随机化)的使能基础设施,而非解决SDN特定控制平面漏洞。核心贡献在于将基于Transformer的攻击感知模块与层次化DRL集成,以协调对抗高级持续性威胁(APT)的多阶段移动目标防御。因此,该工作更准确地被描述为AI驱动的自适应基础设施防御机制,而非SDN原生或物理层安全解决方案。 为提升异步联邦学习的效率,文献[210]提出一种基于Transformer的PPO,以应对计算资源有限、能耗以及安全威胁等问题。主要方案基于两阶段DRL与Transformer编码器PPO(TS–TEPP)。其中,演员网络和评论家网络均接收经过Transformer编码器预处理的输入数据,这有助于提供最相关的信息以产生正确的动作和状态值。该模型在少量回合内快速收敛并达到期望的效用值。
通信与干扰攻击
文献[18]通过将层次化DRL与基于Transformer的控制相结合,在MEC开放无线网络(MEC-O-RAN)中实现了更高性能的抗干扰任务调度。该工作使用基于Transformer的A2C,其序列决策的预测误差相比标准DRL方法极低。在低空无人机场景中,文献[194]提出一种Transformer增强的SAC算法,这是一种生成式人工智能技术,用于解决最大化保密速率同时最小化无人机能耗的多目标优化问题。面对动态海事环境固有的强时间相关性和高维决策空间,作者集成基于Transformer的学习策略,利用自注意力机制捕获跨状态和动作序列的全局依赖关系。该架构采用位置编码提供时间上下文,并使用多头注意力分解复杂动作维度,有效防止策略陷入局部最优。所提方案在无人机运行的保密速率和能耗方面展现出高性能。考虑智能反射面(IRS)辅助的编织式车联网(CIoV)上行通信,文献[199]通过Transformer架构增强的多智能体DRL框架解决问题。系统由两种类型的多个异构智能体组成,每个智能体代表一个车辆用户。每个智能体包含一个Transformer模型,处理总结的历史经验记忆信息,并将其输入IMPALA(重要性加权演员-学习者架构)框架。在此方法中,Transformer在提升DRL性能方面发挥了关键作用,特别是在增强通信安全性方面。
数据完整性攻击
许多研究进一步探索了这一攻击范式,其中基于深度RL的方法获得了显著关注。例如,文献[213]提出一种Transformer增强的联邦Q学习(FedQL)框架,用于检测联网自动驾驶车辆(CAV)轨迹识别中的投毒攻击。通过集成区块链实现安全的模型更新,并利用Transformer从轨迹数据中提取时间特征,该方法在保护隐私的同时有效识别恶意传感数据。针对车联网(IoV)中的数据安全与可扩展性问题,文献[204]引入一种基于Transformer的联邦强化学习(TFRL)方法用于生产规划。Transformer模块增强了表示学习的能力以处理高维状态空间,而联邦学习框架使分布式智能体能够在无需共享本地原始数据的情况下学习协作策略,从而降低数据泄露风险。
其他安全问题
对于无人机集群,文献[201]将基于图的DRL与自注意力相结合,用于检测分布式传感器与执行器中的不平衡故障,提升了安全关键任务中罕见事件的检测能力与F1分数。除无线信道外,微架构威胁(如硬件木马、侧信道泄露、推测执行滥用)破坏了边缘设备的物理信任锚点。近期研究探索了RL智能体,通过监控底层性能和功耗计数器检测与微架构和物理层攻击相关的异常模式,并动态调整防御机制(如缓存分区、推测节流、执行随机化)。虽然这些方法在资源受限硬件上面临训练成本与部署开销的挑战,但它们凸显了基于学习的策略如何能够补充安全设计微架构与运行时监测器,在物理层守护感知与计算[202],[214],[215]。
经验总结
原文将Transformer增强强化学习在网络安全中的作用总结为四点。第一,强化学习负责从动态交互中学习自适应防御策略,Transformer负责建模长期时间依赖并提取状态表示,因此适合持续性、隐蔽性攻击下的轨迹决策。第二,多智能体强化学习提供分布式决策框架,自注意力则用于表示大规模实体之间的关系,支持动态异构环境中的协作防御。第三,强化学习可处理资源分配和多阶段防御等复杂优化,Transformer能够捕获结构化动作之间的依赖,帮助形成组合式决策。第四,注意力融合可整合传感、预测和系统状态等多源信息,使防御控制具有更强的上下文感知能力。
7 Conclusions and Future Works / 结论与未来工作
核心结论
本文系统回顾了基于 Transformer 的强化学习方法及其在通信网络中的应用。现有方案主要分为两类:一类是架构增强,即以 Transformer 替代传统循环单元,捕获复杂时间依赖;另一类是序列建模,即把强化学习视为条件轨迹生成任务。论文进一步从资源管理、计算卸载、路由与轨迹控制、网络安全四个领域梳理了这些方法的实现方式。 综述归纳出 Transformer 增强强化学习的四项主要优势。第一,自注意力能够捕获全局上下文和长期时间关系,适合时变信道下的持续决策。第二,架构可以处理不同类型的数据模态,为物联网和未来移动通信场景形成更丰富的状态表示。第三,置换不变注意力有助于协调数量变化的网络实体,例如无人机或卫星节点,而不受固定输入维度限制。第四,离线序列建模能够从含噪数据集中提取高质量策略,并在相关研究中表现出较快的收敛。
面向时延敏感与可靠性关键应用的变换器强化学习
超可靠低时延通信等应用要求在动态网络条件下快速、准确地决策。论文认为,注意力机制能够捕获用户与网络状态之间的复杂依赖,使智能体获得更充分的决策信息。与此同时,Transformer具有高度可并行化的结构,相比顺序处理模型更适合快速推理,因此是时延敏感无线应用中值得研究的强化学习架构。
面向智能表面辅助无线系统的变换器强化学习
未来无线网络预计将广泛部署可重构智能表面和堆叠智能超表面,以改善信号传播与覆盖。此类系统的配置优化非常困难,因为可控单元数量庞大,表面参数与无线信道之间又存在强耦合。论文指出,基于 Transformer 的强化学习可以通过注意力机制建模网络状态与表面配置之间的复杂交互,从而提高智能表面辅助无线系统中的优化效率。
面向车联网的变换器强化学习
未来车联网将利用雷达、视觉、激光雷达和定位信息等多模态传感数据,增强通信与感知能力。基于 Transformer 的强化学习能够建模高动态车辆场景中的时间相关性,并利用历史观测改善预测与决策。论文认为,这种能力可用于提升未来高移动网络中的目标跟踪和资源分配。
原文信息
- 论文题目 Transformer-Enhanced Reinforcement Learning: Fundamentals and Applications in Communication Networks
- arXiv 2606.05208
- PDF https://arxiv.org/pdf/2606.05208
- 摘要页面 https://arxiv.org/abs/2606.05208

