
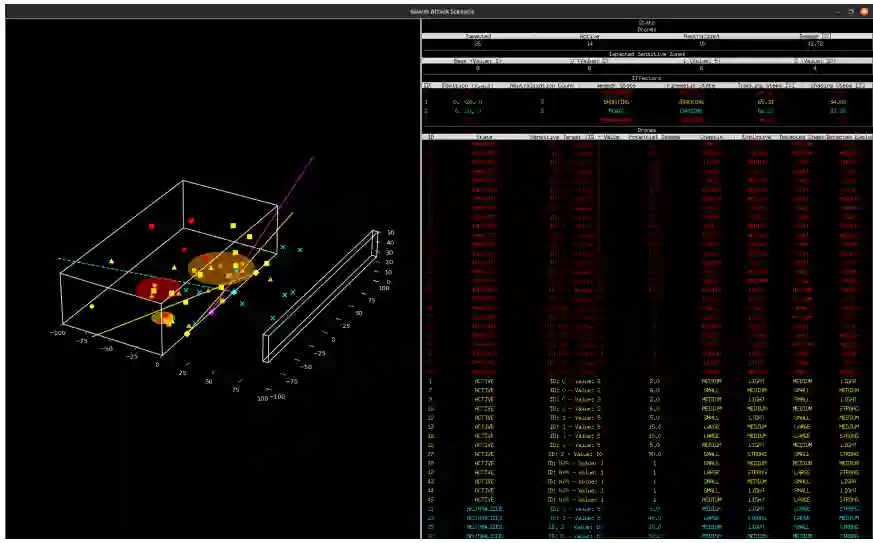
低成本自杀式无人机蜂群日益增长的威胁,对需要快速、战略性决策以跨多个效应器和高价值目标区域优先进行拦截的现代防御系统,提出了严峻挑战。本研究提出了一项案例研究,展示了强化学习在应对这一挑战方面的实际优势。引入了一个高保真仿真环境,该环境捕捉了现实的操作约束,一个决策级强化学习智能体在此环境中学习协调多个效应器以实现最优拦截优先级排序。该智能体在离散动作空间中运行,根据观测到的状态特征(如位置、类别和效应器状态)为每个效应器选择要接战的无人机。在数百个模拟攻击场景中,将习得的策略与手工制定的基于规则的基线策略进行了比较评估。在保护关键区域方面,基于强化学习的策略始终实现了更低的平均损伤和更高的防御效率。本案例研究凸显了强化学习作为防御架构中战略层的潜力,可在不取代现有控制系统的情况下增强系统弹性。所有代码和仿真资源均已公开发布,以确保完全的可复现性,并提供了视频演示以说明策略的定性行为。
关键词:强化学习,无人机蜂群防御,决策支持系统,智能控制,基于仿真的评估,关键基础设施保护
本文其余部分结构如下。第2节回顾了无人机蜂群防御和决策支持背景下的强化学习的相关背景与工作。第3节描述了仿真环境、系统架构以及控制问题的形式化定义。第4节详述了强化学习的公式化表述,包括智能体设计、动作空间和奖励函数。第5节介绍了实验设置,并对习得策略与基于规则的经典基线策略进行了性能比较。第6节探讨了强化学习在安全关键系统中的作用。最后,第7节对全文进行总结并概述了未来的工作方向。
成为VIP会员查看完整内容
相关内容


最新内容
相关VIP内容
相关资讯