
防御大规模对抗性无人机蜂群,需要超越传统多智能体优化的有效协调方法。本文提出,通过将经过验证有效的小型防御团队策略,作为模块化组件集成到更大规模的部队中,从而扩展其应用,为此提出了一个框架。动态规划(DP)分解方法将这些组件在多项式时间内组装成大型团队,从而无需穷举评估即可高效构建可扩展的防御体系。由于孤立状态下表现出色的单元,在组合后未必能保持其优势,会在多个候选小团队策略中进行采样。框架在评估大团队结果与改进模块化组件库之间迭代,从而收敛到日益有效的策略。实验表明,这种划分方法可以扩展到规模大得多的场景,同时保持有效性,并揭示直接优化方法无法可靠发现的协同行为。
本研究的主要贡献有四个方面:
(1)一种用于可扩展防御的遗传算法-动态规划混合框架。提出了一个框架,该框架结合了遗传算法(在小规模交战中演化有效染色体)和动态规划(将这些染色体组装成应对更大规模蜂群的策略)。这使得在朴素进化方法无法达到的规模上进行可处理的分析成为可能。
(2)动态规划与分层防御策略的集成。通过将动态规划引导的分配嵌入到分层结构中,我们的方法在子团队层面协调防御者,同时在智能体层面保持异质性,从而在复杂的蜂群遭遇中实现有效的追击-规避动态。
(3)进化搜索的染色体因子分解视角。我们证明了在该领域中,有效的构建模块是整个染色体(启发式方法的组合),而非单个基因,这突显了保持高阶依赖性的重要性。
(4)通过大规模评估进行迭代优化。通过将大规模评估的结果反馈到小团队启发式方法中,我们的方法逐步提高启发式估计的准确性,并收敛到高性能的大规模防御者策略。这种迭代设计不仅提供了问题的解决方案,也为其系统性改进提供了一种经过验证的方法。
问题阐述与设定
将无人机防御场景形式化为一个多智能体协调问题,详细说明智能体动态、目标和交互,并介绍我们通过遗传算法与动态规划混合方法求解的分层启发式策略。环境由一个开放的二维战场和一个固定的关键资产(目标)组成,蓝队必须保卫此目标(见图1)。红队攻击者从随机化的起始位置(相对于目标的半径和角度)出发,沿正弦路径(具有随机化的振幅和频率)试图抵达目标,这种非线性且不可预测的运动方式使得防御者无法依赖简单的线性外推。虽然这并非完全真实,但该设计为评估分层和启发式协调策略创建了一个信息丰富的测试平台。蓝队的目标是最大化胜率——通过阻止红方智能体抵达资产来实现,这与先前许多侧重于智能体奖励[27]或损耗[21, 24]的研究不同。
每个智能体的状态包括其位置(𝑥, 𝑦)、航向𝜃和速度𝑣,其动作由转弯和加速指令定义,这些指令被限制在固定的范围内。智能体对其所有队友和对手具有完全可见性。蓝队的协调通过一个分层启发式框架实现:每个智能体执行一个选定的启发式方法,而一个结合了动态规划的混合遗传算法则优化启发式方法的分配和参数,以最大化团队层面的性能。
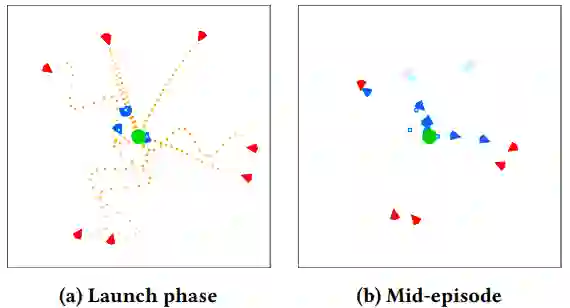
图1:场景中包含10名防御者(蓝色)保护一个目标(绿色)免受8名攻击者(红色)的攻击。在(a)中,攻击者及其朝向目标的进攻路径(橙色)一同显示。在(b)中,已发生碰撞不再参与战斗的无人机颜色变暗。
每个蓝方智能体由一个选定的启发式方法控制,该方法决定了其在环境中的底层动作。团队层面的协调是通过将启发式方法分配给各个智能体而实现的,而不是通过在每一时间步进行显式的联合规划。为了优化这些分配以及任何相关的启发式参数,我们采用了一种结合了动态规划的混合遗传算法,从而能够有效探索可能的团队配置组合空间。蓝方智能体事先对攻击者的轨迹一无所知。防御策略通过遗传算法进行优化,该算法基于评估策略并通过交互进行评估。通过这种方式,我们的方法不依赖于攻击者模型。
图2展示了框架内的流程,说明了如何集成启发式选择、环境交互以及遗传算法-动态规划优化,以最大化蓝队的胜率。仿真本身遵循标准的马尔可夫决策过程(MDP)结构:在每个时间步,所有智能体提交动作,环境相应地进行状态转移,并返回新的观察结果(以及潜在的奖励,尽管此处未使用奖励)。与传统的强化学习方法不同,框架中的所有决策制定纯粹由启发式驱动,协调性产生于遗传算法-动态规划优化,而非基于策略梯度或价值的学习。这种模块化方法使得无需重新训练即可通过重用和组合优化后的启发式方法来实现扩展。
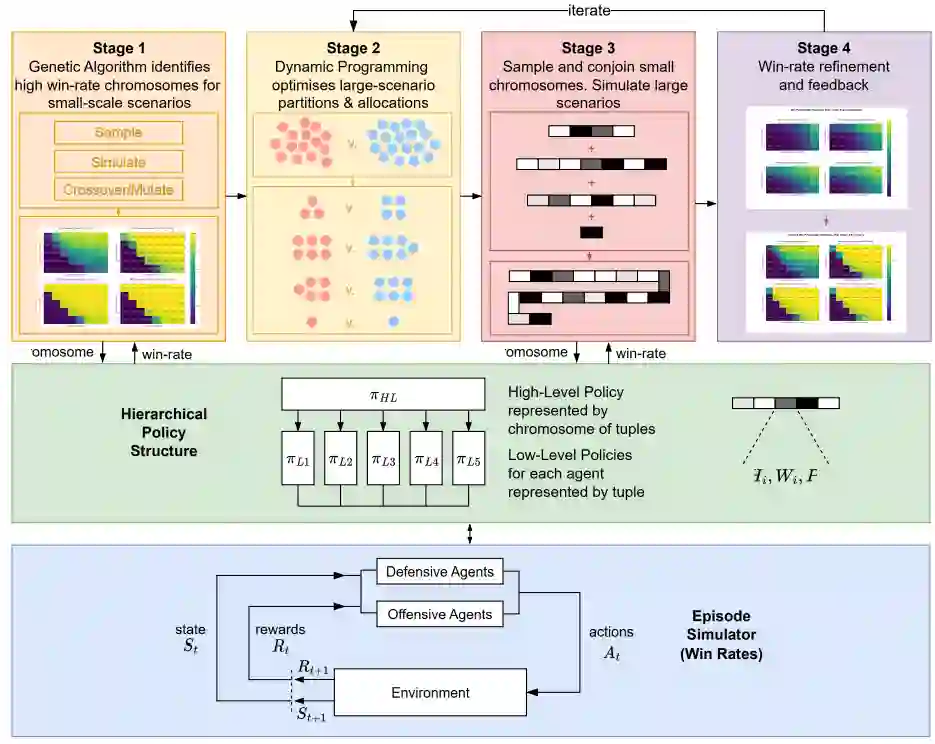
图2:整体混合遗传算法-动态规划框架。四阶段流程(阶段1:遗传算法进化,阶段2:动态规划分配,阶段3:染色体采样,阶段4:优化)在一个分层策略结构上运行,该结构将启发式方法分配给智能体。这些启发式方法驱动所有决策制定。模拟器遵循标准的MDP循环,但未使用强化学习——协调性完全来自启发式分配和遗传算法-动态规划优化。

