扩散语言模型(Diffusion Language Models, DLMs)虽具备并行生成的潜力,但在生成质量上仍逊于自回归(Autoregressive, AR)模型。本文将这一差距归结为内省一致性(Introspective Consistency)的缺失:即 AR 模型能够与其自身的生成结果保持一致,而 DLMs 往往无法做到这一点。为此,我们定义了内省接受率(Introspective Acceptance Rate),旨在衡量模型对先前生成的 token 的认可程度。研究发现,AR 训练的结构性优势源于其因果掩码(Causal Masking)与 Logit 平移(Logit Shifting)机制,这些设计隐式地强化了内省一致性。
受此启发,我们提出了内省扩散语言模型(I-DLM)。该范式在保留扩散模型并行解码特性的同时,继承了 AR 训练的内省一致性。I-DLM 采用了一种新颖的内省步进解码(Introspective Strided Decoding, ISD)算法,使模型能够在单次前向传播中,在推进新 token 生成的同时完成对已生成 token 的验证。在系统实现上,我们借鉴 AR 模型的优化技术构建了 I-DLM 推理引擎,并进一步开发了平稳批处理(Stationary-batch)调度器。
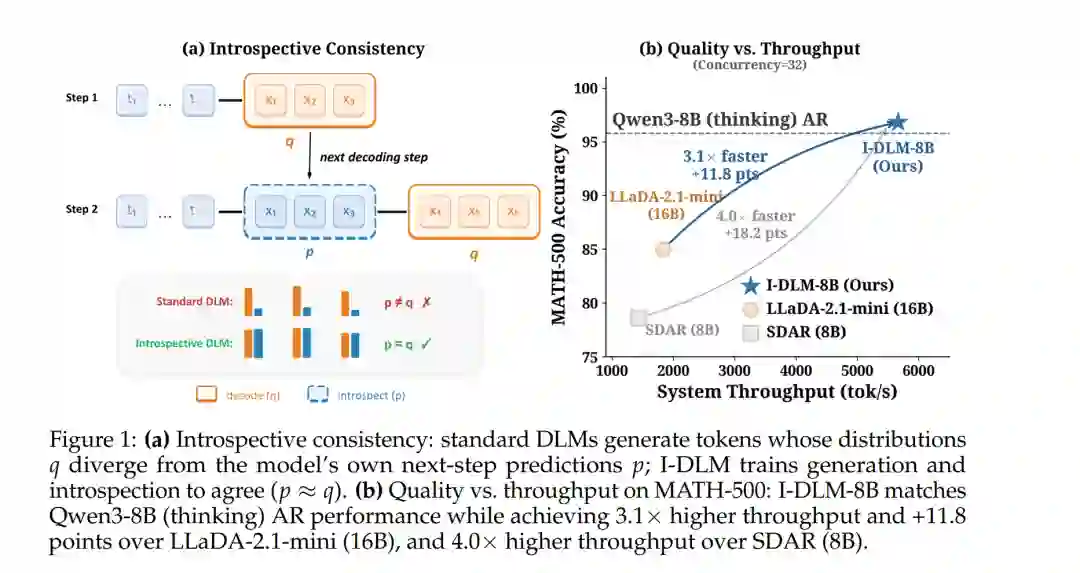
据我们所知,I-DLM 是首个在生成质量上足以媲美同等规模 AR 模型的扩散模型。在 15 项基准测试中,I-DLM 在模型质量与实际服务效率方面均优于此前的 DLMs。具体而言,I-DLM 在 AIME-24 和 LiveCodeBench-v6 上分别取得 69.6 和 45.7 的高分,较之 LLaDA-2.1-mini (16B) 分别提升了 26 分与 15 分以上。此外,针对日益增长的高并发服务需求,I-DLM 的设计使其吞吐量达到了此前最优(SOTA)扩散模型的约 3 倍。
1. 引言
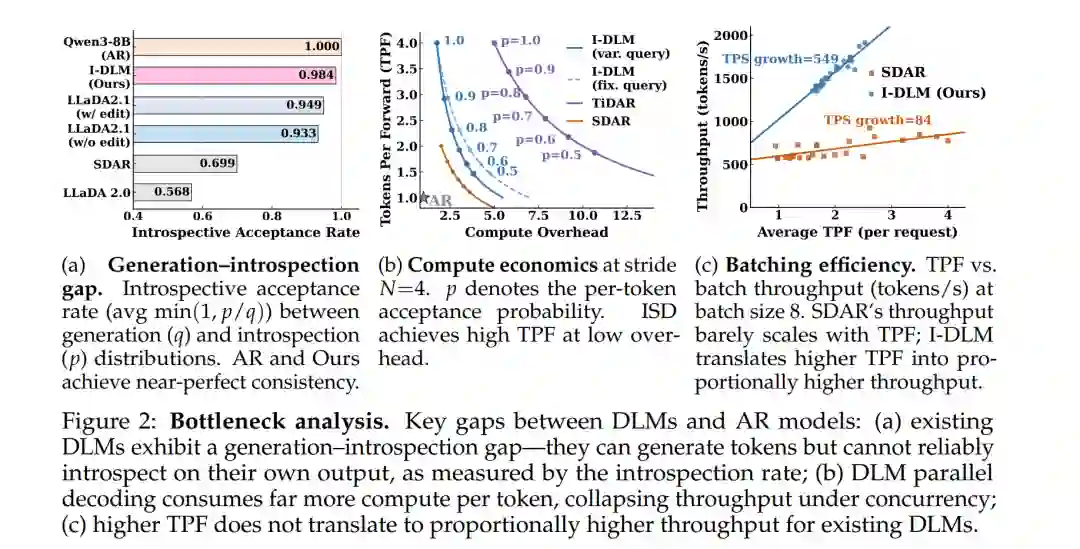
扩散语言模型(Diffusion Language Models, DLMs)(Austin et al., 2021; Sahoo et al., 2024; Nie et al., 2025a; Cheng et al., 2025) 为自回归(Autoregressive, AR)语言模型提供了一种极具吸引力的替代方案:通过迭代优化一组 token 块,它们打破了“逐 token 解码”的序列瓶颈,实现了并行生成。然而,如图 1 所示,这一愿景在很大程度上尚未实现。首先,DLMs 与 AR 模型之间显著的质量差距仍是其应用的主要障碍(§2)。其次,从效率角度看,目前对扩散推理的系统支持有限,导致 DLMs 无法将理论上的并行性转化为实际的加速效果。 DLM 发展的历史轨迹具有启发性。从早期的连续形式化(Li et al., 2022)和均匀状态 DLMs(Austin et al., 2023),到离散扩散模型(Lou et al., 2024);从完全双向注意力机制(Nie et al., 2025b),到分块解码(Cheng et al., 2025; Wu et al., 2025)及因果掩码解码(Liu et al., 2025a),每一代改进都在向离散 AR 语言模型靠拢。为了优化性能与质量,研究者还引入了日益趋向 AR 风格的训练信号(Liu et al., 2025b; Gat et al., 2025; Ye et al., 2025; Tian et al., 2025)。换言之,该领域的大部分研究已隐约收敛于同一种直觉:增强 DLMs 的途径在于使其逐步接近 AR 模型。而在本文中,我们提出了不同的演进路径。我们并非从扩散模型出发探讨如何使其类 AR 化,而是从 AR 模型入手并追问:究竟是什么核心原理使 AR 模型如此强大,以及该原理能否在并行生成范式中得以保留?
我们从算法与系统两个视角重新审视了这一问题。在算法层面,这种视角的转变促使我们重新检查 AR 建模核心中一个看似简单设计:因果掩码(Causal Masking)结合 Logit 平移(Logit Shifting)。除了实现下一 token 预测外,这种训练结构还隐式地教导模型在相同的预测规则下,重新审视并验证其先前生成的 token。实际上,AR 模型被训练为与其自身生成的内容保持一致,这暴露了现有 DLMs 的一个根本局限:尽管它们可以并行生成 token,但通常并未被训练为认可其自身的生成结果(例如,由于多步双向去噪机制的存在)。我们通过内省接受率(Introspective Acceptance Rate)这一概念将这一差距形式化,该指标用于衡量模型在内部接受其先前生成 token 的程度。我们发现,该属性可以作为衡量 DLM 与其自身生成内容保持一致程度的有效代理指标。 在系统层面,现有的 DLMs 往往针对激进的低延迟解码进行了优化,但这以显著增加计算开销为代价。虽然这种开销在内存受限(Memory-bound)场景下可以被部分掩盖,但在需要大批次推理的生产级部署中,系统会迅速进入计算受限(Compute-bound)状态。遗憾的是,目前的 LLM 服务栈与“多查询、多去噪”的模式匹配度较差。 主要贡献: 上述算法与系统间的失配促使我们协同设计了内省扩散语言模型(I-DLM)。这是一种既能保留 AR 内省一致性,又能维持并行特性的新范式。I-DLM 构建于“内省一致性训练”(一种将预训练 AR 模型高效转换为 DLM 的方案)以及一种新颖的内省步进解码(Introspective Strided Decoding, ISD)算法之上。ISD 在单次前向传播中生成 $N$ 个 token,同时根据因果锚点分布(Causal Anchor Distribution)验证先前的 token。我们证明,在训练期间显式强化内省一致性是弥合 DLM 与同规模强力 AR 模型之间质量差距的关键。本文的主要贡献如下: * 核心洞察: 指出内省一致性是先前 DLMs 中缺失的关键原理。我们证明扩散语言模型并未继承 AR 模型的内省一致性,即它们未被训练为认可自身的生成结果。这一属性的缺失从根本上限制了模型充分发挥其底层能力。 * 高质量并行生成的训练新范式: 引入了内省一致性训练,这是一种简单且高效的方案,可将预训练 AR 模型转换为内省 DLM(例如仅需 5B token)。通过显式强化内省一致性,该方法在不牺牲 AR 级质量的前提下实现了并行解码。与以往方法不同,它不需要蒸馏策略或掩码课程学习(Masking Curricula),为构建高质量 DLM 提供了一条稳定且高效的路径。 * 统一生成与验证的单次解码算法: 提出了内省步进解码(ISD),该算法在单次前向传播中同时生成新 token 并修订先前的 token。在 [MASK] 位置,模型提议新 token;在“内省”位置,模型根据其因果锚点分布重新审视先前的 token。这使得输出在证明上能匹配基础 AR 分布,且无需启发式置信度判断或独立的验证过程。 * AR 兼容的推理服务栈: 设计了一个直接兼容现有 AR 服务系统(如 SGLang)的推理栈。此外,我们开发了一套**门控残差适配(Gated Residual Adaptation)**机制,其中 LoRA 适配器仅应用于掩码位置,而验证过程则依赖基础模型权重。该机制支持从近乎无损到严格无损模式的连续切换。 * 全方位的性能验证: 在 15 个基准测试中,证明了 I-DLM 是首个能达到同规模强力 AR 质量的 DLM,同时在模型能力和实际服务效率上均大幅超越此前的 DLMs。我们的研究结果建立了新的“质量-效率”前沿。
我们将开源模型与系统,以促进社区研究与部署。