1 引言
视频理解是使模型能够感知并推理周围世界的关键任务。与静态图像相比,视频具有时序连续性(temporal continuity)、视角变化、运动引起的遮挡以及跨帧的远距离依赖性 [1–6],这些特性显著增加了任务难度。从概念视角来看,视频理解可以分为两个互补的层次。在底层(low level),模型旨在恢复几何结构,如深度、相机运动和点对应关系,以描述世界的运动方式 [7–9];在高层(high level),模型力求捕捉语义信息,包括物体、动作、交互以及基于语言的概念,这些信息传达了世界的含义 [10–12]。近期在大规模预训练和基于 Transformer 的架构 [13–15] 方面取得的进展,显著提升了这两个层次的性能,催生了日益鲁棒的视频理解系统。
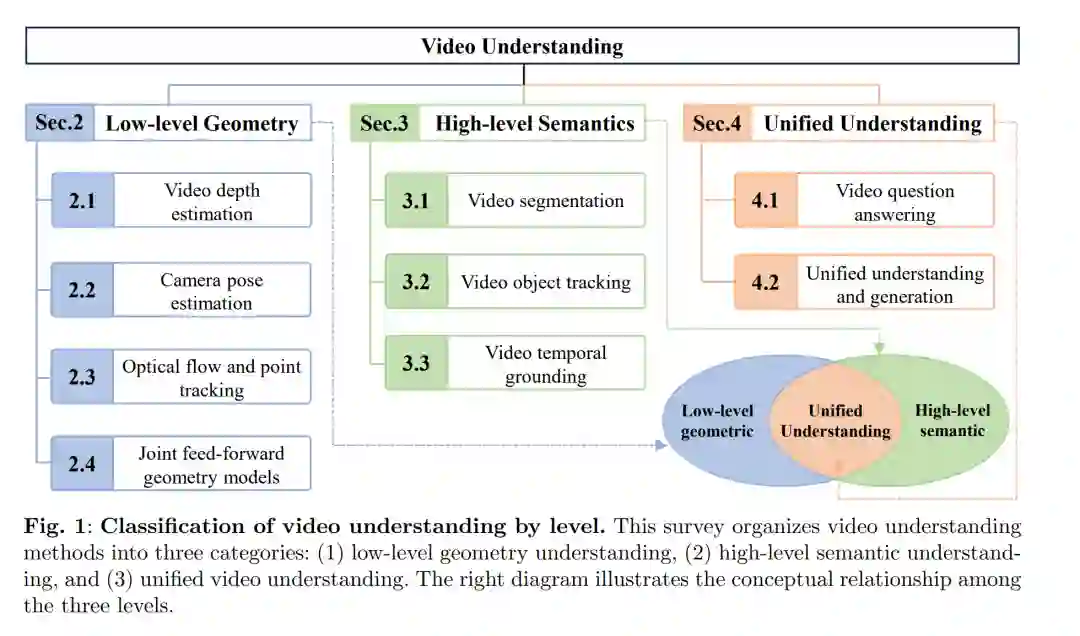
本综述的一个核心观察是:视频理解的进展主要沿着三个交织的方向演进:恢复几何结构、识别并推理随时间变化的语义,以及构建整合二者的统一模型。许多经典流程和现代学习系统 [16–18] 侧重于几何或语义中的某一方面,而新兴的一类统一模型则要求同时兼顾两者。在这种设定下,几何建模提供了底层的物理与时序一致性,而语义理解则在长视频序列中保持了物体身份(Object Identity)和组合意义 [19–22]。据此,本综述围绕这三个互补视角展开,共同构建了视频理解演进格局的连贯视图,如图 1 所示。
底层视频几何理解
综述的第一部分关注视频的底层几何理解,其目标是从视频输入中预测具有物理意义的表征 [13, 23, 24]。代表性输出包括深度、相机位姿(Camera Pose)、稠密光流以及跨帧的长期点跟踪(Point Tracking)。这些几何预测构成了场景重建和几何感知推理的基础,在 2D 视觉观测与底层 3D 场景结构之间架起了一座自然的桥梁 [9, 19, 25]。除了任务特定的预测器外,我们重点介绍了一类迅速增长的联合前馈几何模型(Joint Feed-forward Geometry Models) [7, 8],它们以数据驱动的方式学习几何,并在统一网络中联合预测多个几何原语,从而提升了跨场景和跨视频域的泛化能力。
高层语义理解
综述的第二部分回顾了视频的高层语义理解,其目标是识别、定位并推理随时间演变的具有实际意义的实体和事件 [10, 11, 26, 27]。我们关注三类代表性任务族:视频分割(Video Segmentation)、视频目标跟踪(Video Object Tracking)和视频时序接地(Video Temporal Grounding)。尽管这些任务在公式化定义和监督方式上有所不同,但它们共同要求具备时序相干表征(Temporally Coherent Representations),以保持物体身份、捕捉运动线索并整合跨帧的上下文信息。我们讨论了现代架构和大规模预训练模型如何提高鲁棒性,例如通过引入可扩展设计 [10, 18, 28, 29]、多模态融合 [11, 30–32] 以及大语言模型或视觉-语言模型(VLM)[12, 33]。
统一视频理解模型
综述的第三部分聚焦于明确旨在实现统一视频理解的模型,此类模型要求同时处理底层几何与高层语义。当系统必须回答有关视频的问题而非仅仅分配标签时,这种设定便会自然出现。例如,视频问答(Video QA)模型必须综合推理几何线索(如深度、场景结构和对应关系)与语义信息(如物体身份、意图和交互),以生成正确且具可解释性的回答。同样,新兴的统一理解-生成模型 [34–36] 将视频合成能力(要求细粒度的时空与几何一致性)与面向理解的接口(如依赖语义解释的指令遵循和视频编辑)相结合。我们认为,这些统一模型为下一代**视频基座模型(Video Foundation Models)**提供了一个实践视角,因为现实世界的应用日益需要在一个单一系统中实现几何一致的生成 [37–39] 和组合式的语义控制 [40–42]。
综述结构
按照上述组织逻辑,本综述绘制了该领域的连贯蓝图,从几何原语过渡到语义推理,最后到整合二者的模型。我们首先涵盖底层视频几何理解(第 2 节),包括视频深度估计(第 2.1 节)、相机位姿估计(第 2.2 节)、光流与点跟踪(第 2.3 节)以及联合前馈几何模型(第 2.4 节)。随后回顾高层语义理解(第 3 节),重点关注视频分割(第 3.1 节)、视频目标跟踪(第 3.2 节)和视频时序接地(第 3.3 节)。最后,我们讨论统一视频理解模型(第 4 节),涵盖视频问答(第 4.1 节)和统一理解-生成系统(第 4.2 节)。我们以开放性挑战和未来方向(第 5 节)作为总结。