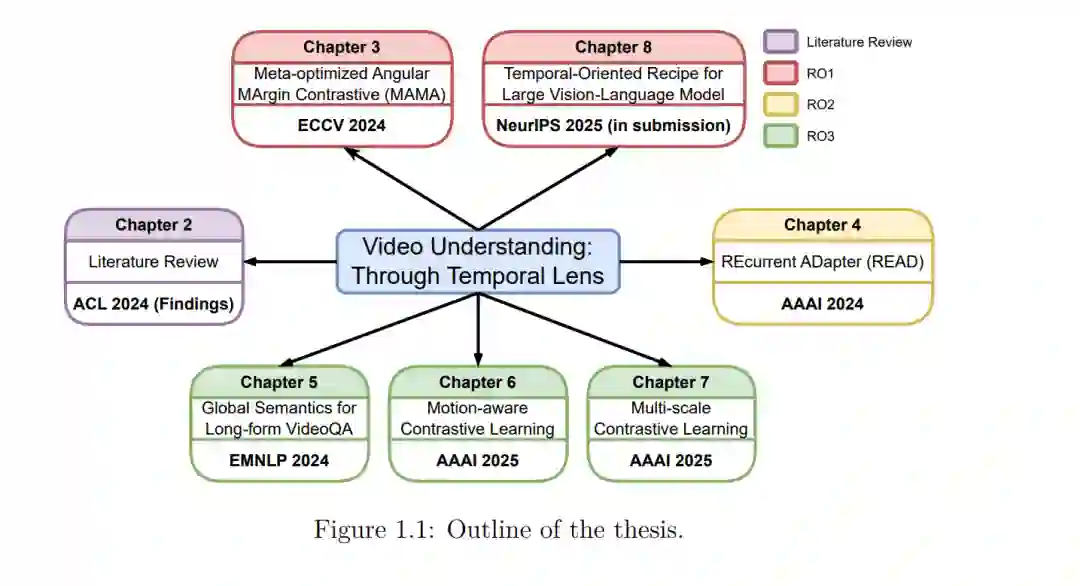
图像与视频的根本区别在于视频引入了时间维度(Temporal Dimension)。这一维度激发了我们对视频元素(如对象位置、帧和事件)之间时间关系(Temporal Relations)的感知。例如,当物体改变位置时,我们将这种位置变化感知为运动;观看视频时,我们在帧流中体验动作。此外,人们在观看电影时会联系不同事件,试图构建连贯的叙事。这些实例表明,视频本质上体现了其元素间的时间关系,因此要求任何视频理解模型都必须具备时间感知能力(Awareness of Temporality)。基于此,本论文旨在解决以下问题: “如何利用视频元素间的时间关系来提升视频理解性能?” 首先,视频理解的性能长期受限于训练数据的规模与质量,这一瓶颈源于获取高质量标注视频数据极高的人力与经济成本。为克服这一难题,我们提出了一种自动标注方法,利用大规模视觉语言模型构建视频帧间时间演进的能力,为视频生成语言标注。考虑到自动生成的标注可能引入噪声,我们提出了一种带有减法角度余量(Subtractive Angular Margin)的对比学习目标,通过正则化手段防止模型在视频表示与其语言描述之间产生“过度完美的相似度”。从直觉上讲,视频及其描述通常传达重叠但不完全等同的信息,我们的方法在理论上证明了这一点的有效性。 其次,在资源受限的场景下,手动和自动方法均难以生成充足的监督训练数据。在这种情况下,对模型参数进行全量更新易导致过拟合与性能退化。为此,我们采用参数高效训练(Parameter-efficient Training)方案,仅微调被称为适配器(Adapters)的有限模块子集。我们为适配器配备了递归计算层,构建出专门用于建模视频帧间时间关系的递归适配器(Recurrent Adapters)。此外,我们将部分视觉-语言对齐目标整合到训练中,确保模型能有效捕捉与任务相关的时间语义。实验表明,该方法在有限训练数据的多任务场景中表现优异。 第三,现有研究多聚焦于包含独立或简单事件的短视频,且大多试图在粗采样元素(如视觉补丁或视频帧)间推断时间关系。然而,对于长视频而言,粗采样难以完全捕获视频内容,而密集采样则会导致计算开销过大。为解决此问题,我们向视频理解模型引入了状态空间层(State Space Layer, SSL),以高效建模密集采样元素间的时间关系,实现长程视频理解。此外,针对目前缺乏真实评估长程视频理解基准的问题,我们推出了两个新基准:一个基于平均长度 18 分钟的第一视角视频(Egocentric Videos),另一个基于时长达 2 小时的电影。我们精心设计了复杂的提示词,指导 GPT-4 生成极具挑战性的问题,要求模型必须同时具备对长视频信息的总结、对比和压缩能力。实验证明,在长程视频理解中,我们的方法优于自注意力机制和递归层。 第四,尽管视频元素间存在时间关系,但相比于视频与其文本描述之间的跨模态关系,研究者对时间关系的关注仍然较少。为填补这一空白,我们首先提出了一种新颖的对比学习框架,驱动模型关注视频中两种动作之间的关系。随后,我们将该框架扩展到捕捉视频片段(Moments)之间的关系。广泛的实验表明,这种显式时间建模方法通过增强表示对细粒度时间关系的感知,显著提升了视频理解能力。 最后,随着具备卓越推理能力的大语言模型(LLMs)问世,多项研究尝试构建大规模视觉语言模型(LVLMs)进行视频理解。遗憾的是,这些模型往往依赖空间归纳偏置(Spatial Inductive Biases),假设空间知识可以平滑地迁移至时间理解,而非显式建模视频中的时间关系。这种依赖限制了现代视频理解模型充分发挥其理解潜能。为突破这一局限,我们进行了深入的实证研究,揭示了影响 LVLMs 时间理解能力的关键组件。研究发现,核心症结在于视觉编码器与 LLM 之间的中间接口(Intermediate Interface)。基于此发现,我们提出了一套时间导向的方案(Temporal-oriented Recipe),包括时间导向的训练方案和升级后的接口。利用该方案开发的最终模型在标准视频理解基准测试中显著超越了以往的 LVLMs。