
摘要:受地形通行能力与战术风险的双重影响,军用车辆路径规划是一项复杂的决策难题。本文提出一种优化模型,将土壤通行能力与敌方交战风险纳入开阔地域作业规划决策支持体系。虽以军事应用为核心,该模型亦可拓展至野火应急响应、农业作业及越野车辆休闲活动等领域。本研究将路径规划问题构建为基于作战环境离散化表征的最小成本混合整数线性规划模型。各节点代表特定地理位置,节点间通过弧连接,穿越弧所产生的成本由综合风险函数确定,该函数统筹考量土壤强度、与已知敌情活动区及既往车队行进路线的邻近程度。评估土壤强度所需的环境输入数据通过集成外部模型获取,此类模型可估算地形评级锥指数(RCI)的空间变异特征。本文以科罗拉多州北部某区域为案例,结合高分辨率环境数据与模拟战术条件对模型进行验证。情景分析表明,风险权重、车辆机动特性及作战条件的变动显著影响路径几何形态与任务风险水平。基于成本函数中各项系数赋值及车辆属性参数的差异,目标函数值呈现五个数量级的波动。研究结果证实,本框架能够有效量化环境机动约束与战术考量之间的权衡关系。
关键词:路径规划;军事;机动战;优化;最小成本网络;决策支持
现代战场是多域联动的动态环境。地面部队在此类环境中实施机动面临多重不确定性及各类风险,即便在最有利的条件下亦难以顺利通行。此外,在高度机械化与现代化的军事力量时代,高效的战场机动规划往往是决定任务成败的关键要素。鉴于现代战争的复杂性,在作战环境下规划机动行动必须统筹考量诸多(且常相互制约)的因素,而连续平面空间内潜在的行进路线无穷无尽。因此,构建一套能够量化战场路径规划风险并据此提供决策建议的方法论,将有助于实现更稳定、更优的作战成效。尽管既有研究已提出若干辅助开阔地域路径规划的模型,但尚无模型纳入战场指挥官在规划中必须考虑的战术因素[1-6]。
地形通行能力取决于环境特征(如土壤强度、地形坡度)与车辆特性(如重量、履带属性)。军用车辆通常配备装甲及其他专用设备,其重量显著高于民用车辆;因此,实施越野机动对土壤强度的要求更为严苛。土壤强度受土壤组分(或质地)及含水率影响。由于土壤空间异质性及气象条件的时空变异性,土壤强度预估结果天然存在显著不确定性。
在评估开阔地域车辆路径时,必须充分考虑路线的战术影响,以最大限度降低部队面临的动能打击风险。为此,需对友军、敌军及平民活动进行综合分析。近期冲突表明,敌方战斗人员倾向于在平民聚集区部署武器与兵力,规避此类区域既可降低部队风险,亦能减少平民与友军伤亡。情报侦察成果可标识敌情活跃区域,此类信息应在路径规划中予以重点考量。此外,既往车辆行进路线易被敌方掌握,规避历史通行路径将削弱敌方的伏击与爆炸物威胁能力。
开阔地域路径优化在非结构化交通网络外的民用领域亦具有广泛适用性。例如,在野火应急响应中,优化地面人员与重型装备的行进路线可缩短响应时间、提升消防员安全性,并降低陡坡、软弱土体及火势突变等危险环境的暴露风险。在农业生产中,路径优化可支撑重型机械在生产区域内及区域间的调度,减少因机械陷滞导致的作业延误,以及作物与土壤损毁引发的产量损失。此外,全地形车等越野休闲活动亦可受益于兼顾环境保护与使用者安全的风险感知型路径规划。在上述各类场景中,将环境数据与作业约束相融合以构建可量化风险,能够显著提升决策科学性。
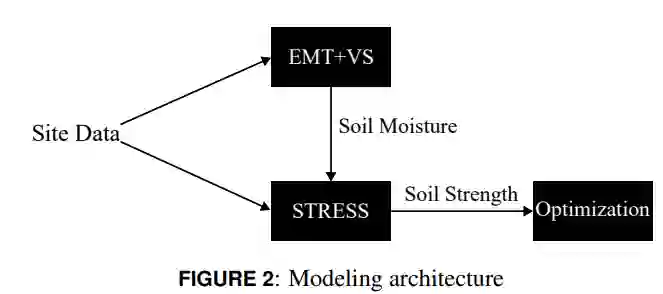
本项目核心目标是构建一种优化模型,该模型利用外部数据源提供的土壤强度信息,优化开阔地域潜在行进路线,其目标函数旨在最小化因车辆陷滞、恶劣地形机动及战术因素导致的任务失败风险。
人工智能(AI)应答引擎如今承担着分析师、学者及公众提出的和平与冲突议题相关咨询的日益增长份额。大语言模型(LLM)在特定条件下存在“幻觉”现象已为人所知,但当其面对冲突相关质询时,此类错误是否存在可辨识的模式?若存在,又能为理解全球冲突信息环境的演变提供何种启示?为解答上述问题,本研究首先就28场冲突向五款主流应答引擎发起系列质询,并将所得5,460条回答与既有实证记录进行比对评分。研究发现,特定冲突的可检索记录越匮乏,引擎虚构、错归因及计数失准的现象就越频发。记录匮乏不仅诱发幻觉,更因这类记录最易被“生成式引擎优化”(GEO)手段扭曲以偏置引擎响应,从而制造出易受错误信息与虚假信息侵蚀的结构性漏洞。通过对人工智能大语言模型提取冲突事实所依据的1,048个网站的解析,我们发现生成式引擎优化源头操纵已现端倪,尽管国家党派主导的数字渗透尚处萌芽阶段,但其扩张势头迅猛。本文将阐释上述发现在生成式引擎优化信息战兴起背景下对学术研究的意义,并从政策层面主张回归深度在地监测与基于翻译的研究范式——此类工作乃人工智能工具无法复刻。文末将探讨这一快速演进领域未来的研究机遇与挑战。
关键词:人工智能(AI);冲突;大语言模型(LLM);生成式引擎优化(GEO);偏见;幻觉;国家主导虚假信息;搜索引擎博弈
若向主流人工智能大语言模型应答引擎询问2025年乌克兰平民死亡人数,各引擎给出的数据均收敛于同一经核实数值。OpenAI、Grok、Gemini、Perplexity及Anthropic均援引联合国监测团的统计,称至少2,514人丧生,与该年度2,514至3,000人的文献记载区间吻合。此类回答通常标注源自联合国或其他权威机构,并对漏报可能性作出限定,其信息准确度大体可达维基百科级别。但若就刚果民主共和国西部蒙博多(泰克-雅卡)族际暴力事件提出相同质询,引擎则会臆测伤亡数字、拒绝作答、凭空捏造数据,或转而论述全然无关的冲突,其应答仅依托训练数据中近似匹配内容生成看似合理实则脱离现实的结论。
当下,学者、专业人士及公众欲获取冲突速览信息时,愈发倾向于直接询问聊天机器人,而非开展深度调研——后者旨在检索既有文献并凝练为一两句概要。独立测试结果令人对这类信息压缩过程难以采信:大语言模型对摘要新闻的引用源出错率逾60%[1],主因在于难以便捷定位权威信源[2]。这是否意味着,在媒体关注度低、信息稀缺的冲突议题上,社会对人工智能大语言模型的依赖加深将导致认知水平进一步滑坡?2025年全球有组织暴力致死人数创1994年以来新高[3],其中大量暴力事件鲜受瞩目。加之全球媒体多样性与内容生产普遍收缩,若可资调用的信息日趋匮乏,个体自主调研时间持续缩减,我们对冲突的认知图景将面临何种风险?
为探究竟,本研究向五款主流人工智能大语言模型征询28场不同冲突的相关信息,系统评估其应答内容及所引素材。研究得出三项核心发现:其一,引擎在媒体报道最薄弱的冲突议题上准确度最低——相关记录越单薄,虚构、错归因及计数失准现象越频繁,“被遗忘的冲突”受害最深;其二,恰恰在报道匮乏之处,引擎对既定可查的事实存在系统性遗漏,此非单纯无力回答无解之问,而是未能检索已知信息;其三,记录最单薄的冲突议题最受生成式引擎优化工具的针对性操纵。尽管此类操纵多源于地方小型媒体为博取曝光与自我宣传,但宣传机构已开始利用人工智能引擎的检索机制,在公众质询低信息量冲突“真相”时定向塑造其认知视野。综上,本研究表明所有主流人工智能大语言模型均在放大国际社会对多数冲突的漠视,文末将探讨如何修复这些系统性缺陷。
自主武器系统(AWS)正引发日益广泛的争议,其核心症结在于此类系统是否削弱了人类对武力运用的“有意义控制”。当前关于自主武器系统的讨论多聚焦于未来技术发展,然而深入审视自动化与自主化功能如何已融入防空系统关键流程便会发现,在特定情境下,人类控制实则已名存实亡。本报告主张,在自主武器系统讨论中长期被忽视的防空系统,已然为该类武器的研发与规制树立了重要且堪忧的先例。
本报告详述了具备自动化与自主化特征的防空系统在开发、测试及实战部署过程中,如何在具体目标识别决策环节侵蚀了人类对武力运用的实质性控制,使其日渐流于形式。我们认为这种“无意义性”体现在双重维度:其一,因系统反应速度极快、任务复杂度极高以及操作人员承压过重,人类主体难以对防空系统实施审慎控制(即人类对武力的控制缺乏实质意义);其二,随着机器代理权限的持续递增,人类在具体目标决策中的控制范围与实质内涵被逐步架空,形成累积性效应(即人类控制随时间推移不断弱化)。
防空系统在受控武器参数与预设环境下运行,但在人机交互层面,其关于人类控制有效性的实践暴露出显著缺陷。随着越来越多任务被委派予机器,操作人员角色已从主动操控退化为被动监督。这一转变的累积后果是将人类主体置于一种看似参与实则极度复杂的尴尬境地。人机交互领域的专家已承认此问题的严重性,并推动了部分战术层面的操作调整,却未引发对持续推进防空系统自动化与自主化进程是否妥当的根本性质疑。
这表明,数十年来具备自动化与自主化特征的防空系统的研发与运用,已在潜移默化中助长了一种未经言明的规范默许。规范即指导行为的“合宜性”认知,其未必指向普世标准,往往反映特定行为体在特定语境下的判断。防空系统正助推形成一种界定“合宜”人机交互的新兴规范——而这正是“有意义的人类控制”的核心要素。此种规范被政策制定者心照不宣地接受,先于且平行于2014年以来联合国《特定常规武器公约》框架下的国际辩论。其根本问题在于,它将操作人员目标决策角色的弱化常态化,视为可接受且“合宜”之举,从而背离并消解了当前将“有意义的人类控制”确立为潜在自主武器系统国际新规普遍义务的审慎努力。
本研究基于对全球28款具备自动化与自主化特征的防空系统的定性梳理,并结合对四起误击军民航空器事件中相关系统的深度人机交互分析。本项研究推动关于自主武器系统的讨论超越单纯技术能力视角,转而关注防空系统在“常态化”集成自主功能方面的示范效应,及其对具体目标决策中“有意义的人类控制”内涵的重塑。
通过揭示“无意义人类控制”的浮现,本报告阐明:进一步将自主功能集成至武器系统既非如常理所想的那般可取,亦非不可避免。遵循“停止杀手机器人运动”的倡议,我们支持以“有意义的人类控制”为核心积极义务,制定关于自主武器系统的新型国际法。为确保此类法律保障确能维系对武力的“有意义”而非“无意义”控制,现就联合国《特定常规武器公约》框架下参与致命自主武器系统国际辩论的各利益相关方提出以下建议:
• 各国应在特定武力运用场景中操作具备自动化与自主化特征武器系统的现行实践应予公开并接受审查。诚如本报告所论,此类操作实践直接塑造着“有意义人类控制”的内涵,尤其是人机交互的质量与类型。
• 除防空系统外,亟需就其他现役自动化与自主化武器系统所催生的“有意义人类控制”新兴标准开展深度研究。此类研究可切实揭示自动化与自主化给人机交互带来的现存及未来挑战,若不加明示应对,恐将固化隐性的“合宜性”认知。
• 本研究表明,尽管“有意义人类控制”的技术、条件及人机交互三要素均至关重要,但通过人机交互实现的管控才是确保控制不失其真的决定性环节。此点尤为关键,因为人机交互凸显的是武器系统具体使用节点的控制有效性,而非研发等前期阶段的管控。
• 在裁军辩论中任何关于“有意义人类控制”的成文规范,均应将人机交互管控作为核心要件。我们界定了人类主体行使有意义控制的三个先决条件:(1)对目标识别系统的运作机制及决策逻辑具备功能性认知,包括其已知缺陷(如航迹分类问题);(2)充分的态势感知能力;(3)具备审视机器目标决策的能力,而非过度信赖系统。当然,人类操作人员必须保有中止武力使用的权限。
• 上述确保具体目标决策中“有意义人类控制”的三个先决条件(功能性认知、态势感知及机器决策审视能力),为自主武器系统研发划定了不可逾越的硬性边界,应纳入国际法明文规范。这构成了技术层面的“卢比孔河”,一旦逾越便将使人类控制彻底丧失意义。恪守这些条件不仅有助于维系控制的实质性,亦有望缓解当前防空系统操作人员无意中被置于必然失败境地的压力。
• 人机交互固有的复杂性意味着,在具体目标决策中实现“有意义的人类控制”必然存在局限。确保操作人员接受严格训练是维系控制有效性的必要前提,却非万能良方。这一严峻现实须向所有相关利益方明确昭示。

乌克兰武装部队第九独立无人系统旅“达加兹”分队指挥观察所。图片来源:第九独立无人系统旅
乌克兰武装部队中央科学研究所正式推出“玛莉奇卡(Marichka)”——一款基于人工智能的决策支持系统。据《苏斯皮尔涅》报道,该所所长尤里·克利亚特在新闻发布会上宣布了这一消息。该系统旨在辅助军事主官大幅缩短作战筹划周期内的决策耗时。
当前旅、团级指挥官制定作战方案平均需耗时6至12小时,期间需审阅约20份文件。“玛莉奇卡”系统有望将此流程压缩至数分钟内完成。该系统运行机制与ChatGPT类似:通过集中归集与分析情报信息,研判交战双方战力对比,进而生成多套行动方案。最终决策权仍归属指挥官本人。

“玛莉奇卡”智能信息系统发布会现场,2026年7月22日。图片来源:苏斯皮尔涅新闻 / 尼基塔·哈尔卡
该系统具备数据归集、处理与核验功能,可自动测算兵力兵器对比,评估所需资源及潜在战损,并在交互式地图上构建战场态势模型,随环境变化实时更新。
系统名称取自乌克兰传统女性人名“玛莉奇卡”。据研究所代表透露,该系统已成功通过模拟数据测试。
研发团队目前正持续开展系统测试与神经网络训练,同步推进数据传输信道加密工作,着手集成“仅供公务使用”及“秘密”级涉密文档。下一阶段将重点攻克更高密级信息处理能力。
“玛莉奇卡”系统预计将显著提升旅、军级兵团及战役集群指挥机关与主官的指挥效能。出于安全保密考量,其具体技战术参数尚未公开。
乌克兰武装部队副总司令安德烈·列别坚科准将表示,人工智能技术目前已实际应用于无人机平台及部分武器系统的指挥控制体系中。
新型神经网络将显著加速信息处理、指挥控制及战场决策全流程。
今年5月,曾披露乌军已启动人工智能代理在指挥控制系统中的集成工作,旨在提升海量数据处理效率,包括对敌情研判与己方战力评估等关键领域。
摘要:将n架通信能力受限的无人机部署至划分为n条两两互不相交闭合航迹的待监测区域,每架无人机对应一条专属航迹。本研究中,若两条航迹间距足够近则存在通信链路,仅当无人机同时抵达链路节点时可建立通信。随运行时间推移,一架或多架无人机可能发生故障,系统通信与连通能力随之下降。本文围绕通信相关的两类核心特性展开研究:隔离性与连通性。其一,针对存活无人机集合诱导的连通分量,提出兼具集中式与去中心化特性的高效求解算法;其二,在概率故障模型下对隔离性与连通性开展分析,结果表明网格场景下系统具备极强鲁棒性,可在故障概率处于较高区间时仍避免无人机陷入隔离状态,维持系统全局连通。
关键词:无人机·同步通信系统·通信图·连通性·概率模型

论文解读 | 医学图像修复中的扩散模型:挑战、分类与未来方向

导读
医学图像修复并不是普通图像补全的医疗版。自然图像修复只要视觉上合理,往往就能满足编辑和美化需求;但医学图像修复必须面对更高风险:被补全的区域可能影响病灶判断、治疗规划、分割结果和下游诊断。换句话说,医学场景中的“看起来像”远远不够,模型还必须尽可能保持解剖结构一致性和临床相关性。 这篇综述《Diffusion Models in Medical Image Inpainting: Challenges, Solution Taxonomy, and Future Directions》聚焦一个快速增长的方向:扩散模型用于医学图像修复。作者系统检索 Scopus、Web of Science 和 IEEE Xplore 等数据库,从 841 篇初始文献中筛选出 60 篇符合条件的研究,分析其模型类别、医学模态、应用任务、数据集、评价指标和实验设置,并提出扩散模型方法分类。 论文的核心结论是:扩散模型已经成为医学图像修复的重要生成式路线,尤其适合产生解剖上合理的重建结果,并支持伪健康组织重建、伪影去除、数据增强和异常检测等任务。但领域仍存在明显短板,包括统一 benchmark 缺失、数据集多样性不足、临床验证有限、评价指标偏图像质量而非诊断有效性等。
论文信息
论文题目:Diffusion Models in Medical Image Inpainting: Challenges, Solution Taxonomy, and Future Directions 作者:Arthur Dantas Mangussi, Joana Cristo Santos, Ricardo Cardoso Pereira, Ana Carolina Lorena, Mário A. T. Figueiredo, Pedro Henriques Abreu arXiv:2607.21904v1 类别:cs.CV 时间:2026 年 7 月 24 日 链接:https://arxiv.org/pdf/2607.21904
一、研究问题:为什么医学图像修复重要
医学影像在诊断、监测和治疗规划中处于核心位置,但真实临床采集中经常出现缺失或损坏信息。例如 MRI 或 CT 可能受到患者运动、设备限制、安全协议、扫描时间约束、金属植入物或不完整投影数据影响。缺失区域可能遮挡关键解剖结构或病灶,进而降低诊断可靠性。 图像修复的目标是在缺失或损坏区域生成合理内容,并与周围组织保持视觉和语义一致。在医疗场景中,这个目标更严格:模型不仅要补得自然,还要避免产生虚假病灶、掩盖真实异常或改变临床判断依据。 扩散模型的优势在于,它通过逐步加噪和反向去噪学习数据分布,训练稳定、样本多样性较好,并能生成高质量图像。相比 GAN,扩散模型较少受 mode collapse 和对抗训练不稳定影响;相比传统自编码器,其生成质量和复杂分布建模能力更强;相比纯 Transformer,它在 U-Net 或混合结构中仍保留了适合图像局部空间结构的归纳偏置。
二、系统综述方法:从 841 篇到 60 篇
论文采用 PRISMA 流程进行系统综述。作者使用 image inpainting、diffusion models、image completion、medical images、clinical、healthcare、radiology 等关键词,在多个数据库中检索 2023-2026 年的相关工作。初始共检索 841 篇,去重后剩 565 篇,经过标题与摘要筛选后剩 141 篇,再经全文评估,最终纳入 60 篇。
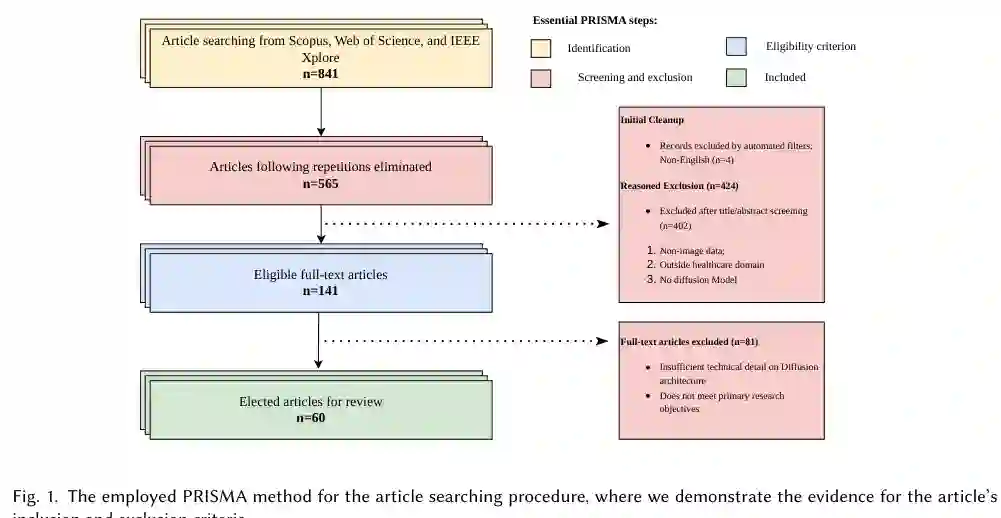
筛选标准也体现了本文范围:研究必须使用扩散式架构,必须处理图像数据,必须面向医疗或健康场景,并且必须涉及 image inpainting。一般医学图像生成、缺失模态合成或与修复无关的扩散模型工作不纳入核心分析。 这一流程使论文不只是“列论文”,而是有明确证据边界的系统综述:它关注扩散模型如何被具体用于医学图像修复,而不是泛泛讨论医学生成模型。
三、扩散模型分类:从 DDPM 到 LDM
论文首先比较了深度生成模型家族:自编码器、GAN、Transformer 与扩散模型。不同模型在质量、多样性和计算效率之间有不同取舍。GAN 生成快但训练不稳定,AE 多样性较好但样本可能更模糊,扩散和 Transformer 模型通常能在质量与覆盖性之间取得更好平衡,但推理成本较高。
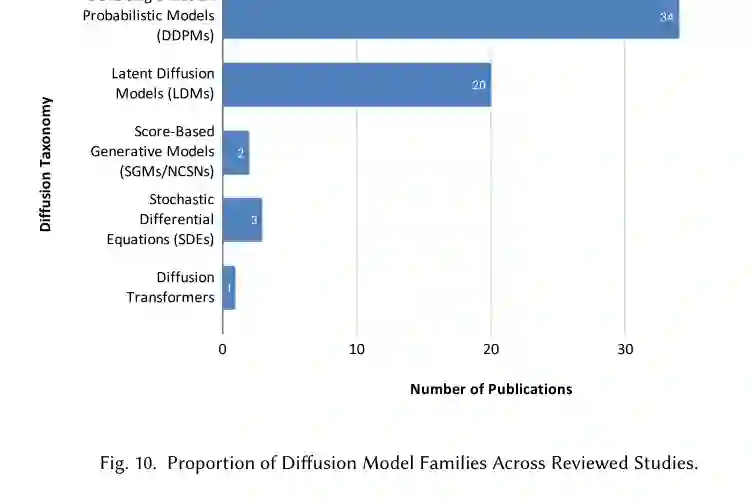
论文提出了扩散模型理论分类,将医学图像修复中的方法归入四个主要家族:Denoising Diffusion Probabilistic Models、Latent Diffusion Models、Score-Based Generative Models 和 Stochastic Differential Equations。
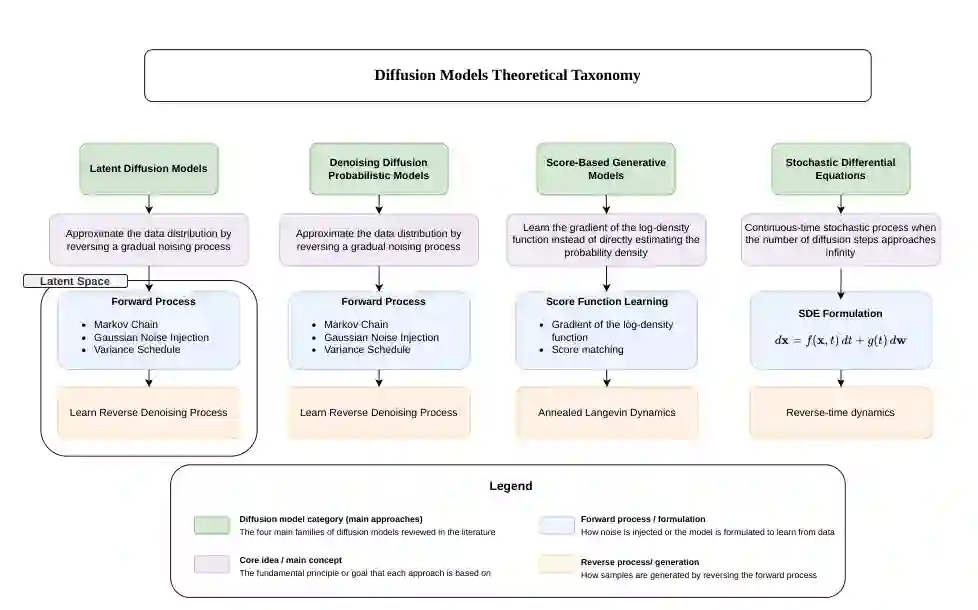
DDPM 通过离散 Markov 链逐步向数据添加高斯噪声,并训练网络反向去噪。LDM 把扩散过程放在潜空间中进行,先用自编码器压缩图像,再在低维 latent 上去噪,从而降低计算成本。Score-based 方法学习数据分布对数密度梯度,通过 score matching 和 Langevin 动力学采样。SDE 方法则把扩散过程推广到连续时间,用随机微分方程统一描述正向扰动和反向生成。
对医学图像修复而言,模型选择并不只是理论问题。DDPM 通常在重建质量上表现稳健,但采样较慢;LDM 更适合高分辨率医学图像,因为潜空间扩散能显著降低资源开销;条件 LDM 可进一步纳入文本、掩码、类别或模态信息;SDE 与 score-based 方法在理论表达上更统一,但实际应用数量相对少。
四、核心架构:DDPM 与 LDM
DDPM 是文献中最常见的扩散模型家族。其基本流程是:正向过程逐步把原始图像变成噪声,反向过程训练神经网络预测噪声或恢复干净图像。在医学图像修复中,模型还会结合 mask、条件图像或上下文区域,使网络只重建缺失或损坏区域。
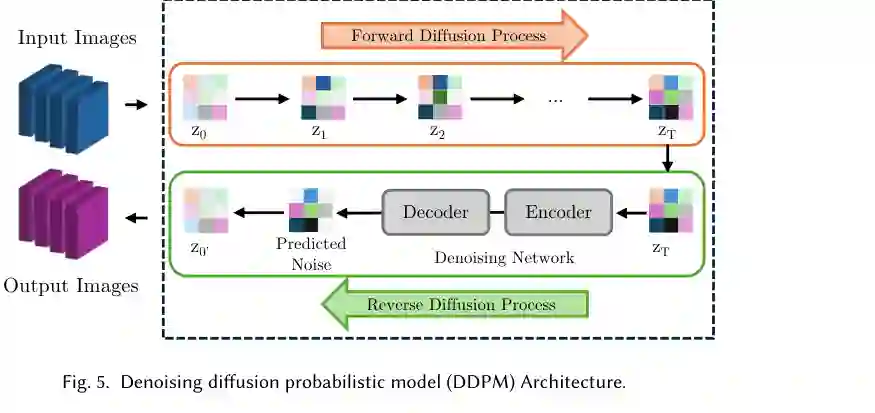
LDM 则把扩散过程移动到潜空间。输入图像先经 encoder 映射为 latent 表示,扩散模型在 latent 上学习去噪,最后通过 decoder 重建图像。由于医学图像常具有高分辨率和大体积数据特点,LDM 的压缩优势非常重要。
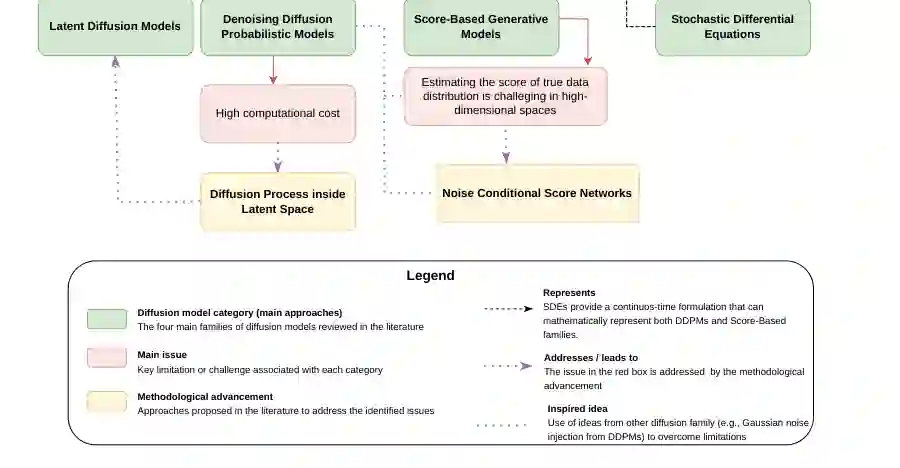
论文指出,在所综述的工作中,DDPM 和 LDM 是主导架构。DDPM 数量最多,说明标准去噪扩散仍是当前医学修复研究的基本范式;LDM 数量紧随其后,反映出领域正在转向更高效、更适合大规模医学影像的潜空间建模。
五、研究趋势与应用分布
论文统计显示,扩散模型医学图像修复研究在 2023-2025 年增长明显。纳入综述的工作中,2023 年有 7 篇,2024 年 16 篇,2025 年达到 32 篇,2026 年截至论文检索时为 5 篇。这说明该方向仍处于快速扩张阶段。
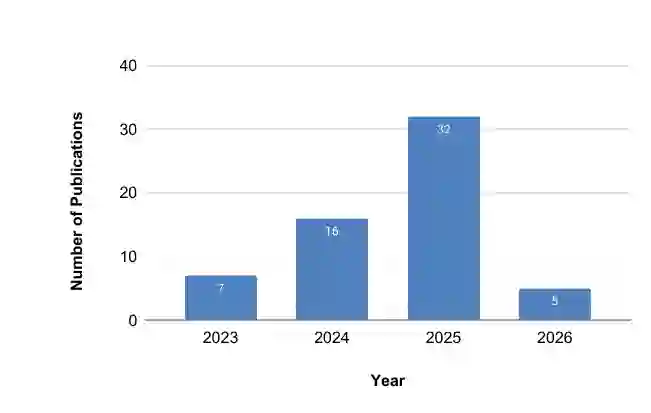
从模型家族看,DDPM 有 34 篇,LDM 有 20 篇,SDE 有 3 篇,score-based 方法有 2 篇,Diffusion Transformer 有 1 篇。当前应用仍以 DDPM 和 LDM 为主体,DiT 类方法在该领域尚处早期。
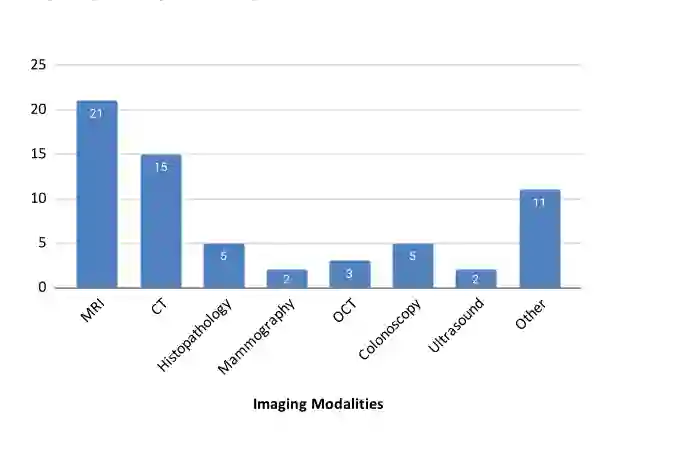
从医学模态看,MRI 和 CT 是最常见的研究对象,分别对应 21 篇和 15 篇;其他还包括组织病理、乳腺摄影、OCT、结肠镜、超声等。这与临床需求和公开数据可得性有关:MRI/CT 数据量较大,且伪影去除、肿瘤修复、缺失区域补全等任务更常见。
论文将应用场景归纳为四类。第一是 artifact removal,即伪影去除,处理运动伪影、金属伪影、不完整采样等问题。第二是 data augmentation,用修复或生成方式扩充数据,提升分割、分类等下游任务。第三是 pseudo-healthy tissue inpainting,即伪健康组织重建,常用于异常检测:把病灶区域修复成健康组织,再通过差异定位异常。第四是其他应用,包括缺失区域恢复、图像补全、模态相关任务等。
六、评价指标与案例研究
医学图像修复评价仍以图像质量指标为主。论文统计发现,SSIM 和 PSNR 是最常用指标,均出现在 53.3% 的研究中;DSC 出现在 28.3% 的工作中,常用于下游分割或结构重叠评价。其他指标虽然频率较低,但在临床相关性、感知质量和任务性能方面有补充价值。 不过,这也暴露出一个问题:PSNR/SSIM 衡量的是像素或结构相似性,不一定等同于诊断可靠性。一个图像可能 PSNR 很高,但关键病灶被弱化;也可能视觉质量好,却在下游诊断上引入偏差。因此,论文强调未来需要更标准化、更临床相关的评价协议。 论文还进行了一个案例研究,在 BraTS 和 TCGA 数据集上统一评测多个公开扩散修复方法,并设置三种缺失机制:MCAR、MAR 和 MNAR,分别代表完全随机缺失、随机缺失和非随机缺失。评价指标包括 PSNR、SSIM 和计算时间。
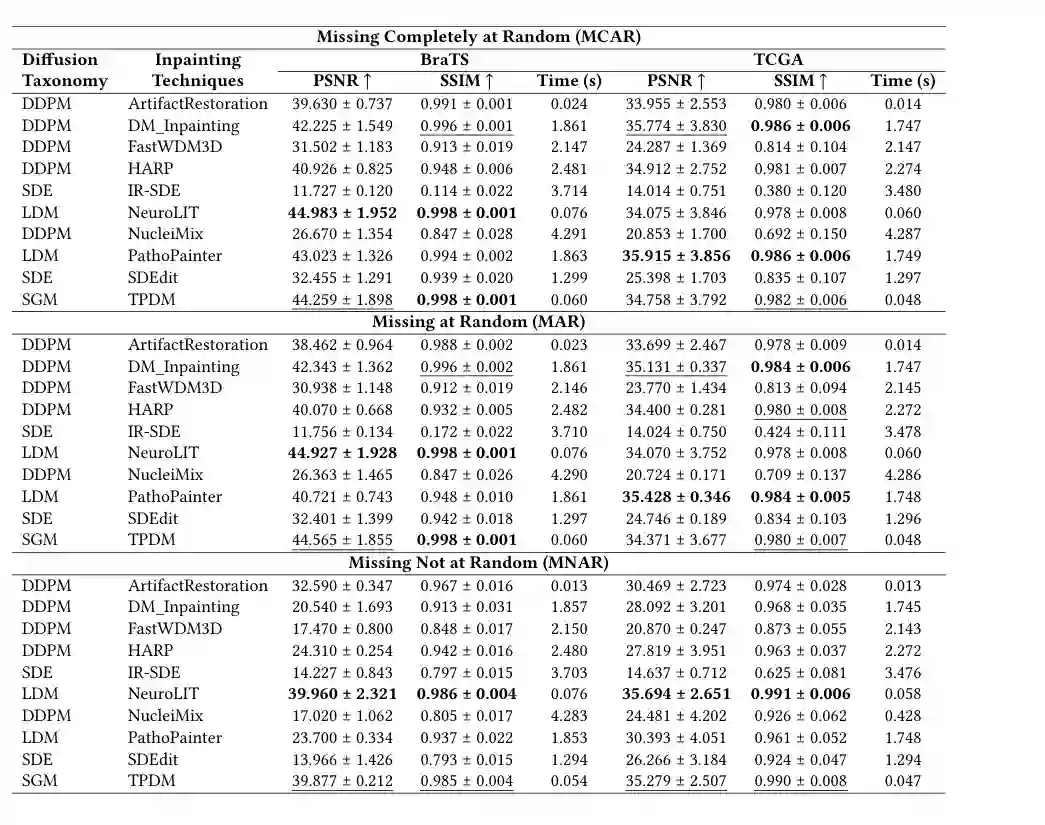
结果显示,不同模型的优势并不一致。NeuroLIT 在多个设置下取得较高 PSNR,TPDM 在 SSIM 和时间方面表现突出,PathoPainter、DM_Inpainting 等方法在特定数据集或缺失机制下也具有竞争力。这说明医学图像修复不存在单一万能模型,模型选择需要考虑模态、缺失机制、目标任务和计算约束。
七、挑战与未来方向
论文总结了该领域的几个关键挑战。 首先是 benchmark 不统一。不同研究使用的数据集、缺失 mask、评价指标和实验协议差异很大,使得方法之间难以公平比较。本文案例研究尝试用统一设置评测多个方法,但领域仍需要更大规模、更公开、更贴近临床场景的标准 benchmark。 其次是数据集多样性不足。当前研究集中在 MRI 和 CT,其他模态如超声、OCT、内镜、病理切片等还不充分。不同模态有完全不同的噪声机制、结构特征和临床任务,不能简单假设一个模型能跨模态泛化。 第三是临床验证有限。很多工作报告 PSNR、SSIM 或 FID,但较少验证修复结果是否真的改善诊断、分割、风险分层或治疗规划。医学修复模型一旦用于临床流程,必须避免 hallucination 式补全,尤其不能生成不存在的结构或抹去真实病灶。 第四是模型效率问题。扩散模型推理通常较慢,医学图像又常常是高分辨率 2D 或 3D 数据,部署成本明显高于自然图像。LDM、加速采样、蒸馏和轻量化网络可能成为未来关键方向。 第五是可解释性和不确定性。医学图像修复需要知道模型在哪些区域可信、哪些区域不确定。未来方法需要输出不确定性估计,或者结合医生可解释反馈,使修复结果能被审查、追踪和校正。
八、总结
这篇综述的价值在于,它把扩散模型医学图像修复从零散方法整理成了一个可讨论的研究地图:从模型家族看,DDPM 和 LDM 是主流;从任务看,伪影去除、数据增强、伪健康组织重建和异常检测是主要应用;从模态看,MRI 与 CT 占据主导;从评价看,PSNR/SSIM 仍是常用指标,但远不能覆盖临床可靠性。 对研究者而言,下一阶段的重点不只是提高图像质量分数,而是建立面向真实医疗场景的完整验证链条:更统一的数据与 mask 生成机制,更贴近诊断任务的评价指标,更广泛的模态覆盖,更高效的推理框架,以及能够量化不确定性的可审查模型。 扩散模型已经证明自己能生成解剖上合理的医学图像修复结果。真正困难的问题在下一步:如何让这些结果可信、可解释、可复现,并最终在临床任务中带来可靠收益。
博士论文 | 从算法到基础模型:强化学习的统一视角

导读
强化学习正在经历一次范式扩展。经典强化学习关心智能体如何在环境中通过试错最大化长期回报;多智能体强化学习进一步引入竞争、协作、均衡与激励;而在基础模型时代,生成模型、扩散模型、视频世界模型和长时序记忆又开始成为决策系统的一部分。Zihan Ding 的 Princeton 博士论文《Reinforcement Learning: From Algorithms To Foundation Models》正是围绕这条主线展开:从算法基础走向基础模型,从博弈中的策略学习走向能建模世界、生成未来、服务规划与控制的新型 RL 系统。 这篇论文不是单一方法论文,而是一组相互衔接的研究:前半部分研究游戏中的多智能体 RL,包括两人零和博弈、复杂视频格斗环境和多人一般和博弈;后半部分研究基础模型时代的 RL,包括扩散世界模型、Consistency 模型作为策略、少步视频生成的 RL 后训练、交互式视频世界模型,以及带记忆的长时序世界模型。 如果要用一句话概括,论文试图回答的是:当强化学习从小规模 MDP 走向复杂交互环境和生成式基础模型时,算法、模型和系统应如何共同演化?这也是当前智能体研究、世界模型研究和生成式 AI 后训练共同面对的问题。
论文信息
论文题目:Reinforcement Learning: From Algorithms To Foundation Models 作者:Zihan Ding 学校:Princeton University 院系:Department of Electrical and Computer Engineering 导师:Chi Jin 论文时间:2026 年 5 月 arXiv:2607.17560v1 链接:https://arxiv.org/pdf/2607.17560
一、强化学习的统一框架
论文第一部分先回到强化学习的基本问题:智能体与环境交互,基于状态选择动作,环境返回下一个状态和奖励,智能体通过策略优化最大化长期累计回报。这个框架看似简单,却可以承载从游戏、网络系统到机器人控制、视频生成和世界模型的多种问题。
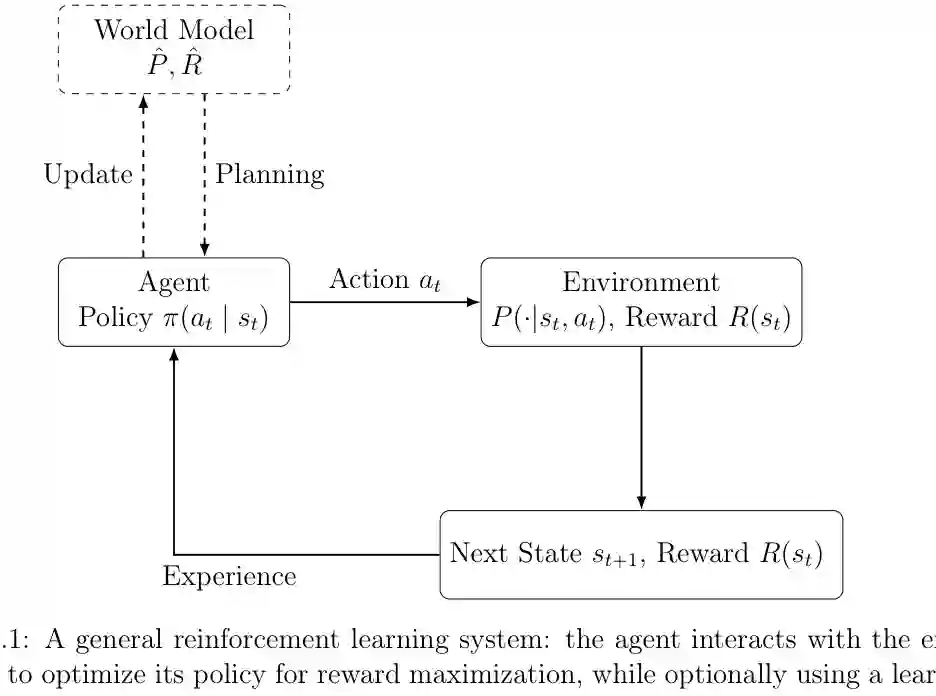
在单智能体环境中,核心对象包括 MDP、策略、价值函数、Bellman 方程、值迭代和策略梯度。论文用这些内容建立统一语言:状态转移描述世界如何变化,奖励定义目标,价值函数评估未来收益,策略优化则把智能体推向更高回报。 但真实智能系统往往不只面对一个固定环境。其他智能体的行为会改变环境,奖励函数可能彼此冲突,最优策略也不再只是单个智能体的最优,而要考虑 Nash 均衡、Markov game、potential game 等博弈结构。论文由此自然进入多智能体强化学习:从“如何最大化自己的回报”扩展到“如何在其他策略也在变化的系统中学习稳定、不可轻易被利用的行为”。 这也是论文标题中“From Algorithms To Foundation Models”的第一层含义:RL 先要有清晰的算法与博弈基础,之后才能进入更复杂的基础模型时代。
二、游戏中的强化学习
论文第二部分聚焦游戏场景。游戏是强化学习的重要试验场,因为它同时具备明确目标、可控环境、多样策略空间和可重复评测。作者先研究两人零和 Markov game,提出 Nash-DQN 与 Nash-DQN-Exploiter,将单智能体 DQN 与 Nash 均衡求解思想结合,试图在连续状态和函数逼近条件下学习更难被 exploit 的策略。 Nash-DQN 的关键在于,不再只学习单个动作价值,而是在每个状态下近似一个两人博弈的 Q 矩阵,并基于 Nash 策略进行行动选择。Nash-DQN-Exploiter 则额外训练一个利用者,让主智能体暴露弱点并被迫改善。这种设计把探索过程与对抗压力结合起来:智能体不是在随机扰动中被动探索,而是在对手不断寻找漏洞的过程中修补策略。 论文随后将这一思想推向更真实的游戏环境,构建 FightLadder 基准。相比棋盘或小型表格博弈,格斗游戏具有像素输入、连续动作节奏、复杂时序依赖和强对抗性,更接近真实多智能体系统中的非平稳学习挑战。

FightLadder 的意义不仅是“多了一个游戏环境”,而是把 fully competitive two-player setting 做成可系统评测的研究平台。论文强调,现有多智能体基准很多偏合作或小规模,而完全竞争环境中,策略之间的可利用性、种群训练、Elo 分布和 payoff matrix 都是重要指标。一个真正好的竞争型智能体,不能只在固定对手上得分高,还要在面对新的 exploiter 时保持稳健。
三、从零和到一般和
在两人零和游戏中,一个玩家收益的增加对应另一个玩家收益的减少,Nash 均衡有相对清晰的结构。但现实系统往往是多人一般和博弈:不同智能体既可能冲突,也可能部分一致;整体系统目标可能是公平性、稳定性、吞吐或资源效率,而不是某个玩家的单独胜负。 论文第五章以网络负载均衡为例研究多人一般和环境。每个负载均衡器只能看到局部观测,需要把请求分配到服务器,同时与其他负载均衡器共同影响系统延迟和公平性。这一问题天然具有部分可观测、多智能体耦合和实时决策属性。
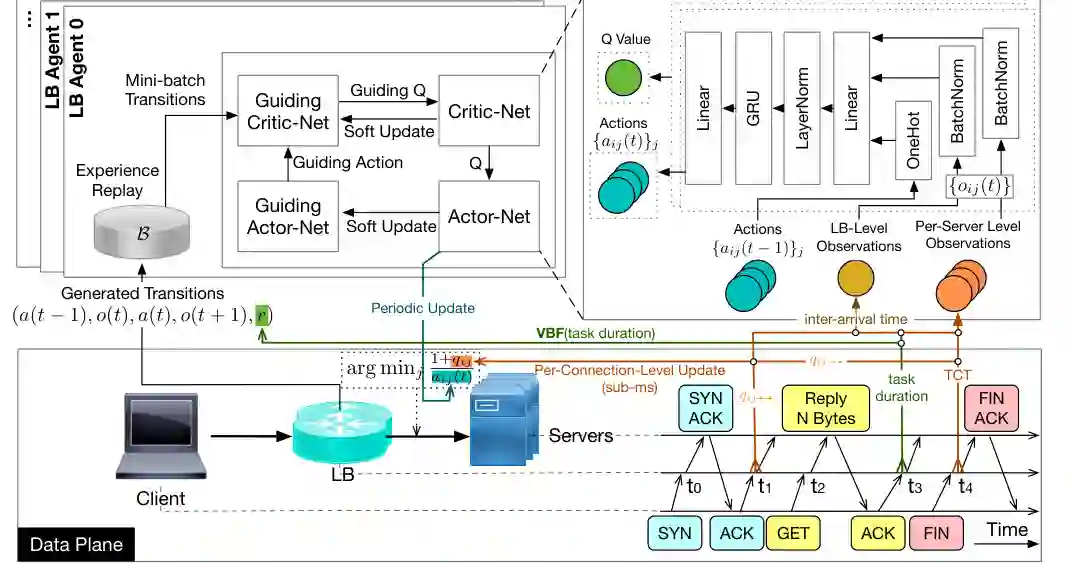
这一章的理论支点是 Markov potential game。它把多智能体的局部激励与一个全局 potential function 联系起来:虽然每个智能体只做自己的局部更新,但如果激励结构满足某些条件,整体系统可以被一个全局势函数刻画。这为分布式 RL 提供了桥梁:不必让每个智能体掌握全局信息,也能通过合适的奖励设计和潜在博弈结构逼近稳定解。 从公众号读者角度看,这部分最值得关注的是“RL 如何进入系统工程”。网络负载均衡并不是漂亮的 benchmark,而是具有延迟、吞吐、公平性和观测限制的真实基础设施问题。论文把一般和博弈、分布式 actor-critic 和系统指标结合起来,展示了多智能体 RL 从游戏走向真实系统的一种路径。
四、基础模型时代的世界模型
论文第三大部分进入 foundation models。这里的关键变化是:RL 不再只从环境交互中学习,也可以借助预训练生成模型和世界模型。基础模型提供先验,世界模型提供未来预测,策略优化可以在“想象出来”的轨迹中进行。 第六章提出 Diffusion World Model。传统 model-based RL 常用一步动力学模型反复 rollout,但长 horizon 下误差会逐步累积。扩散世界模型则试图一次建模多步未来轨迹:给定当前状态、动作和目标回报,模型生成未来若干步状态与奖励,从而降低逐步预测带来的 compounding error。
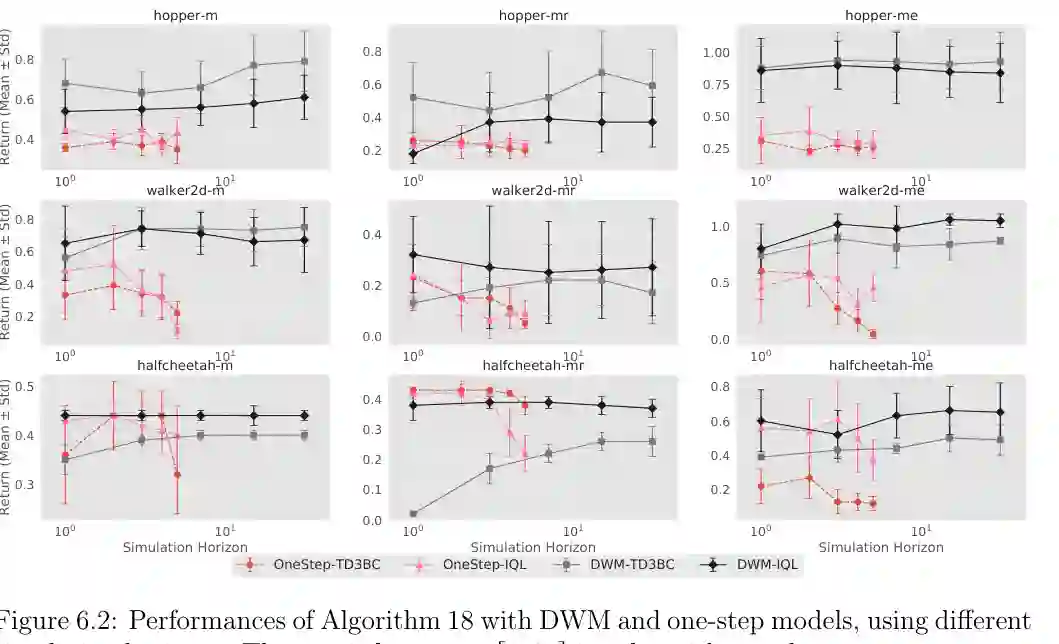
论文把 DWM 接入离线 RL:先用离线数据训练扩散世界模型,再用它生成 imagined data 或做 value expansion,辅助 actor-critic 学习。这里的核心优势有两点。第一,扩散模型能表达复杂、多模态的未来轨迹分布,不必把未来压成单一确定性预测。第二,它能够直接生成多步未来,使规划和价值估计更少依赖逐步滚动。 这部分与今天“世界模型 + 智能体”的讨论高度相关。一个智能体如果能在内部模拟未来,就可以在真实交互成本很高时进行离线规划;而生成式世界模型的作用,正是把环境动态、奖励结构和长期结果压进一个可采样的模型中。
五、生成模型作为策略
第七章讨论 Consistency Models as Reinforcement Learning Policy。扩散策略能够表示多模态动作分布,但多步去噪带来较高训练和推理成本。Consistency 模型则试图用更少采样步骤得到高质量动作,因此适合作为更高效的策略类。 论文设计了 Consistency-BC 和 Consistency-AC。前者用于行为克隆,后者把 consistency policy 嵌入 actor-critic 框架,并用 BC 正则避免生成离线数据分布之外的动作。实验显示,Consistency-AC 在部分任务上略低于 Diffusion-QL,但在计算效率上更有优势,并能在 offline、offline-to-online 和 online 设置中形成可行的权衡。 这一章的重点不只是“换一种策略网络”,而是把生成模型的表达能力带入 RL 策略空间。传统高斯策略对多模态行为建模较弱;扩散和 consistency policy 能更自然地表示“同一状态下多个合理动作”。这对离线 RL 尤其重要,因为离线数据常由多个行为策略混合而来,动作分布本身就是多模态的。
六、RL 后训练少步视频生成
第八章将 RL 与视频生成结合,研究 few-step video generation。扩散视频模型通常生成质量高,但推理步数多、成本高;少步生成器速度快,但可能牺牲质量、多样性或奖励对齐。论文提出 DOLLAR,将 variational score distillation、consistency distillation 和 latent reward fine-tuning 结合起来,使少步视频生成器在效率和质量之间取得更好平衡。
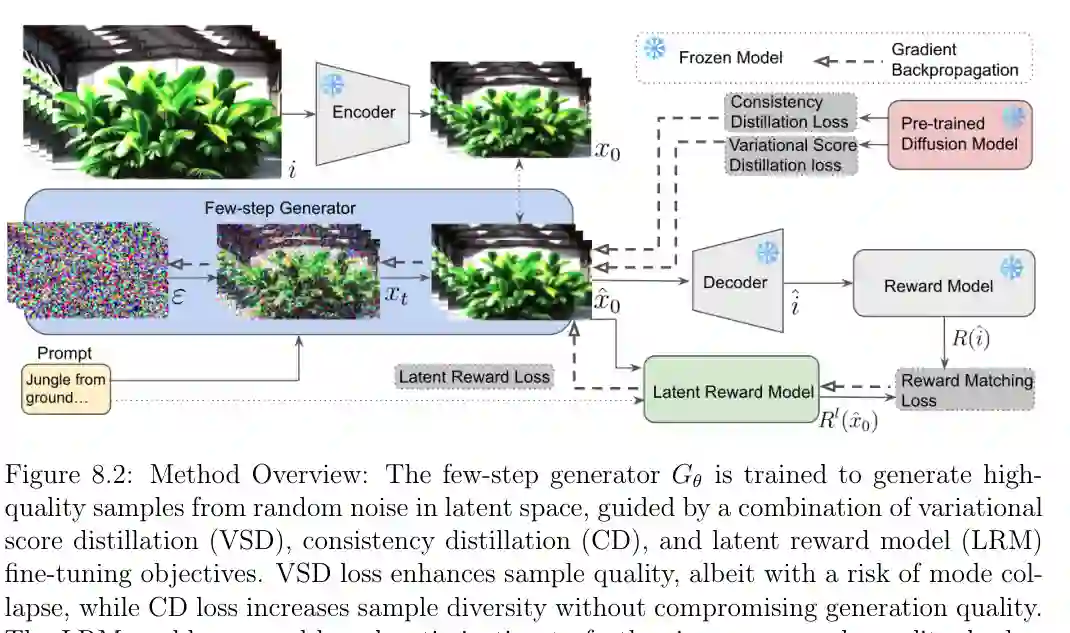
这里的 RL 思想体现在 reward fine-tuning:视频生成结果不只要拟合训练分布,还要满足美学、文本一致性、运动质量或人类偏好等奖励指标。直接在像素空间通过大型奖励模型反向传播会非常昂贵,因此论文引入 latent reward model,在潜空间中近似奖励信号,从而降低显存和计算负担。 这一章说明,RL 在基础模型时代的角色正在变化。它不只是控制智能体在环境中拿奖励,也可以作为生成模型的后训练工具,用奖励模型把少步生成器推向更符合偏好的输出分布。
七、视频世界模型与交互式生成
第九章研究 Video World Model,重点是交互式长视频生成。普通视频生成模型往往给定提示后生成一段视频,但世界模型需要更强的交互性:动作会影响未来观察,历史状态需要被记住,长期生成还要避免误差累积。 论文提出 VRAG,即 Retrieval Augmented Video World Model with Global State。它在视频生成中引入全局状态条件和记忆检索机制:历史帧、动作和状态被保存在 buffer 中,模型通过相似性检索获取相关记忆,再作为上下文参与 DiT block 的自注意力。
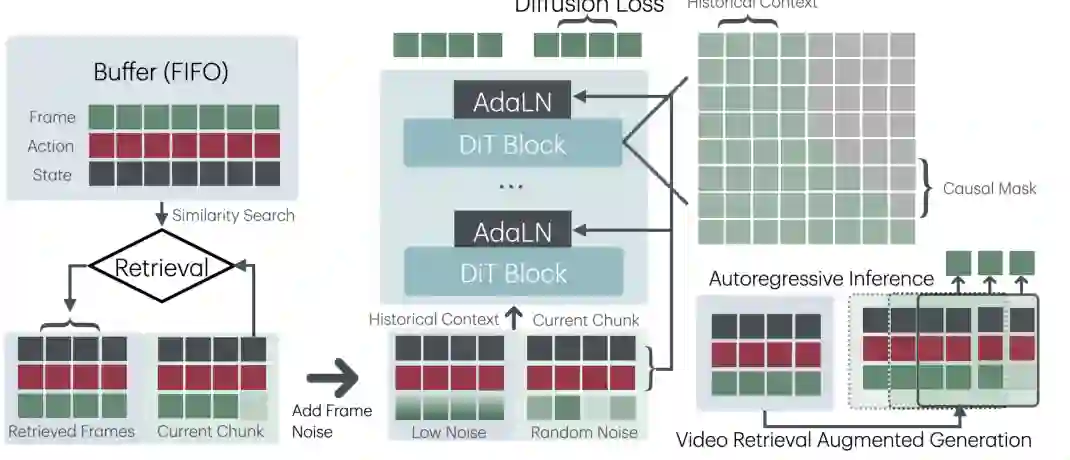
VRAG 的核心问题是长期一致性。视频世界模型如果只依赖有限上下文,很容易在长时间生成中忘记早期状态;如果简单扩大上下文,又会带来训练和推理成本。检索增强提供了折中:不是把所有历史都塞进上下文,而是动态取回对当前生成最有用的记忆。 这与 LLM 中的 RAG 有相似精神,但对象从文本变成了视频世界状态。对于具身智能、游戏 agent、长时序模拟和交互式视觉环境来说,模型不仅要“看起来真实”,还要在动作干预下保持可控和连贯。
八、带记忆的长时序世界模型
第十章继续推进长期世界建模,提出 Recurrent Autoregressive Diffusion。普通 DiT 视频模型擅长空间与局部时序建模,但长序列生成需要一种能跨越窗口传递信息的记忆机制。RAD 在 DiT block 中加入 RNN memory block,并结合 spatial attention、temporal attention 与 recurrent state,让模型在生成长视频时保留全局记忆。
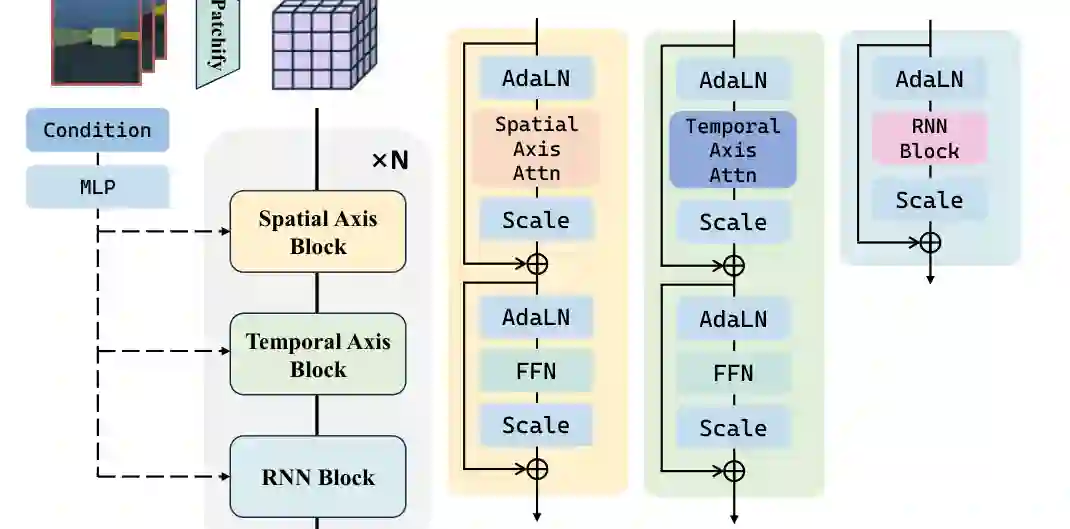
论文还比较了 chunk-wise 与 frame-wise 两种自回归方式。chunk-wise 把视频分块处理,效率更高但时间依赖更粗;frame-wise 逐帧递归,能更细粒度地传递隐藏状态。为了提高训练效率,论文还设计 hidden state prefetch,使 frame-wise RNN 可以更好地并行注意力计算。
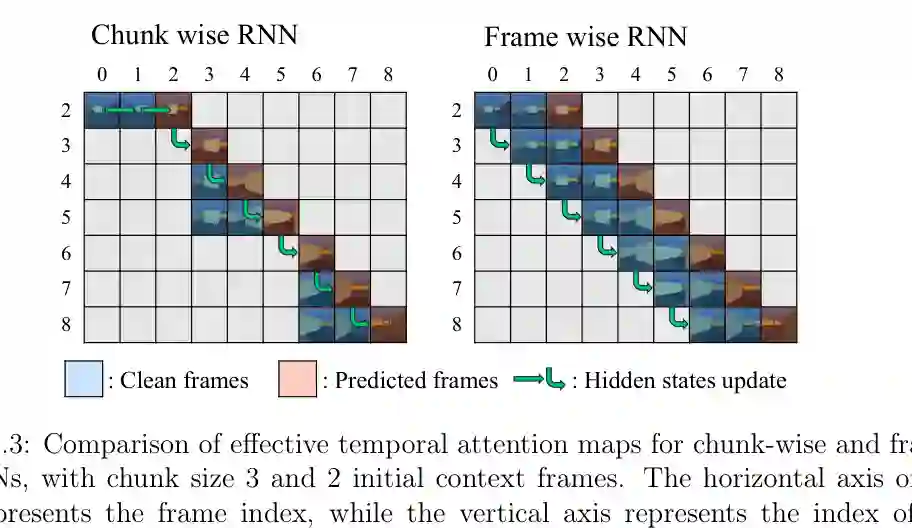
这部分的长期意义在于:世界模型不是短视频生成器,而应成为能持续滚动、记忆过去、响应动作并预测未来的动态系统。对于通用智能体来说,记忆不是额外插件,而是世界建模架构的一部分。
九、总结
这篇博士论文的贡献可以分成两条线。第一条线是算法与博弈:从单智能体 RL 出发,进入两人零和博弈、竞争型视频游戏和多人一般和系统,强调策略学习必须面对非平稳性、均衡、可利用性和分布式激励。第二条线是基础模型与生成式世界建模:从扩散世界模型到 consistency policy,再到少步视频生成、VRAG 和 RAD,强调预训练生成模型可以成为规划、控制、策略表示和长期模拟的核心组件。 更重要的是,论文把强化学习放在了一个更大的智能系统图景中。经典 RL 提供目标驱动的适应机制,博弈论提供多智能体交互的稳定性语言,基础模型提供强先验和生成能力,世界模型提供面向未来的内部模拟。未来的智能体很可能不是单靠其中某一块,而是在这些组件之间形成闭环:观察世界、建模未来、用奖励或偏好调整行为,并在多智能体环境中保持稳健。 从研究趋势看,这篇论文也提示了几个值得继续关注的方向:多智能体 RL 如何在真实系统中稳定落地;生成模型策略如何在表达能力和推理效率之间平衡;视频世界模型如何从“生成好看视频”走向“可交互、可控制、可长期一致的环境模拟”;以及 RL 后训练如何成为基础模型对齐、控制和智能体化的重要机制。 强化学习的下一阶段,或许不再只是寻找更强的单一算法,而是把算法、生成模型、世界模型、记忆和多智能体系统整合成能够长期行动的基础设施。这正是这篇博士论文最值得读的地方。
现代战争正在以机器速度被重新定义。随着威胁变得更加迅捷、分散且依赖数据驱动,全球各国防力量正纷纷转向自主无人机与蜂群无人机,以期获取决定性优势。从边境监视到争议空域的作战任务,军用无人机已不再是可选的支援资产,而是日益成为各国军队开展筹划、感知与打击行动的核心要素。
本文系统梳理了国防领域最重要的自主无人机系统,阐释了军用蜂群无人机技术的工作原理,并就国防采购团队、系统集成商与技术领导者在这一高速发展领域最常提出的核心问题予以解答。

何为国防领域的自主无人机?
自主无人机是指能够在极少甚至无需人工干预的情况下执行任务的无人驾驶航空器(UAV)。与需要专人操控每一个飞行动作的遥控无人机不同,自主系统依托机载传感器、边缘计算与人工智能,能够实时做出决策——独立完成地形导航、规避障碍、识别目标及调整飞行路径。
在国防作战中,自主性绝非仅为便利之举,更是力量倍增器。如今,一名操作员即可同时监控数十架飞行器;通信延迟不再阻滞关键决策;即便在GPS或数据链遭干扰、拒止的环境下,平台仍能持续运行。
定义现代国防自主无人机系统的核心能力包括:
- 基于惯性导航、视觉定位与地形匹配的自主导航能力
- 由机载机器学习模型驱动的实时目标识别能力
- 可根据环境变化自适应调整航线的自愈式任务规划能力
- 适用于争议性电子战环境的拒止GPS环境运行能力
- 融合雷达、光电/红外(EO/IR)、激光雷达及信号情报的传感器融合能力
蜂群技术的崛起
如果说自主无人机代表了单体平台的智能水平,那么蜂群无人机技术则代表了集体层面的智能。蜂群系统可部署数十、数百乃至数千架协同作业的无人机,这些无人机通过实时通信实现互联,在不存在单点故障的前提下分布式执行任务、共享传感数据,并自适应调整编队与行为模式。
这种从单体平台自主向网络化、协作式自主的转变,堪称过去数年间无人防御技术领域最具颠覆性的变革。
蜂群的战略价值
- 冗余带来的韧性——个别单元的损毁不会导致任务失败
- 饱和攻击能力——蜂群可压制专为追踪有限数量单个威胁而设计的敌方防空系统
- 分布式感知——相比单一高价值平台,蜂群可覆盖更广地域并获取更丰富的情报
- 成本非对称优势——由低成本无人机组成的蜂群可牵制或摧毁成本高昂得多的防御资产,从而改变现代冲突的成本经济学
各国军事规划者日益将蜂群无人机视为既定现实,而非未来概念,目前多战区已开展相关实战测试与列装部署。
军用蜂群无人机技术工作原理
任何蜂群系统的核心都是网状通信网络,使无人机能够持续交换位置、传感与任务数据。每个单元通常运行轻量级AI模型以实现本地决策,而更高层级的蜂群算法则统筹集体行为——其原理类似于鸟群或鱼群在没有中央控制的情况下自发协调运动。
最先进的军用蜂群无人机技术依托分层架构实现:
- 单机边缘人工智能——支持目标检测、避障与威胁分类,无需持续连接指挥中心
- 蜂群智能算法——统筹编队控制、任务分配与群体目标优先级排序
- 弹性网状组网——即使个别节点损毁或部分通信中断,仍能确保蜂群持续运行
- 人机协同接口——赋予指挥官高层控制权(如任务目标、交战规则),而具体执行由蜂群自主管理 该架构使蜂群能够执行复杂任务,如协同侦察扫荡、多角度同步打击或周界防御——所需人力仅为传统作战的一小部分。
人工智能赋能的国防无人机:边缘端的智能
人工智能赋能的国防无人机是单体自主与蜂群协同得以实现的基础。机载人工智能可处理以往需人工分析师事后研判的影像数据——如今这一切均在飞行中实时完成。
现代国防无人机中的核心AI功能包括:
- 基于计算机视觉的物体与车辆分类
- 用于识别异常部队或车辆调动的异常检测
- 基于生活模式分析的预测性威胁建模
- 即便在遮挡或规避机动中仍能保持锁定的自主目标跟踪
- 自然语言任务下达,允许操作员发布高层指令而非手动飞行指令
向机载AI处理的转型还减轻了卫星与无线电带宽的负担,因为无人机仅需传输经过预处理的关联情报,而非原始视频流——这在通信受限或带宽紧张的环境中具有关键优势。
自主作战无人机系统:核心评估要素
对于评估自主作战无人机系统的国防机构而言,区分成熟可用平台与原型样机的关键因素包括:
- 自主等级:系统涵盖从部分自主(武器发射需“人在环内”)到完全自主(“人在环上”,仅保留监督控制权)。当前大多数国防部署仍遵循国际规范与交战规则,保留人类对致命行动的最终授权。
- 生存性与隐身能力:低雷达散射截面设计、降噪声学特征及抗电子战能力,决定了平台在争议空域的生存概率。
- 载荷灵活性:支持情报监视侦察(ISR)传感器、电子战设备或精确弹药的模块化载荷舱,使单一机体具备多任务能力。
- 续航与航程:滞空时间与作战半径直接影响单次任务可覆盖的地域范围,直至需加油或更换电池。
- 互操作性:能否与现有指挥控制系统、北约数据链标准及联合作战网络集成,往往是采购决策的决定性因素。
面向现代军事任务的人工智能蜂群无人机
人工智能蜂群无人机在现代军事场景中的实战任务集持续拓展: • 情报、监视与侦察(ISR):蜂群可同时覆盖广阔地理区域,向指挥中心回传统一的实时态势图。 • 电子战与干扰:分布式蜂群可在宽大正面压制敌方雷达与通信。 • 诱骗与佯动作战:低成本蜂群单元可模拟大规模编队,诱使敌方开火并消耗昂贵的拦截导弹。 • 边境与周界安防:持久蜂群巡逻可消除疲劳导致的监控盲区,探测并追踪入侵行为。 • 战区搜救:蜂群可快速扫描广阔区域定位人员,降低搜救分队的风险。 • 协同打击行动:多架无人机从不同方向同时突防,打乱敌方防御反应节奏。
面向情报与作战任务的高级自主无人机系统
领先防务技术供应商正趋于一个共识:构建融合长航时ISR平台与可损耗蜂群打击无人机的高级自主无人机系统,打造分层、梯队化的力量结构。
这种梯队化部署通常包括:
- 用于持久ISR与战略级态势感知的高端长航时自主无人机
- 用于班排级战术侦察的中层战术无人机
- 用于饱和攻击、诱骗或打击任务的大规模低成本可损耗蜂群单元
该分层结构使军队能够平衡成本、风险与能力——将昂贵的高价值资产保留用于战略任务,同时对可损耗蜂群单元保持更高的风险容忍度。
国防机构的获益
采用自主与蜂群无人机技术的机构已收获可量化的作战优势:
- 在高威胁环境中降低人员风险
- 通过AI实时处理的情报加速决策周期
- 相比传统载人平台降低全寿命周期成本
- 在不成比例增加人力的前提下实现可扩展的力量投送
- 通过分布式冗余系统提升任务持久性
挑战与考量
尽管技术进步迅速,防务领导者仍需应对现实挑战:
- 规范自主武器使用的法规与伦理框架
- 网络化蜂群通信伴随的网络安全风险
- 对手正在发展的反无人机与反蜂群防御手段
- 与传统指挥控制基础设施集成的复杂性
- 大规模人机协同所需的训练与条令建设 采购团队评估供应商时,应优先考虑具备成熟互操作性、透明AI决策逻辑及强健网络安全架构的系统。
常见问题解答
问:自主无人机与蜂群无人机有何区别 答:自主无人机依托机载AI独立完成导航与决策,而蜂群无人机是由多架自主单元组成的群体,通过相互通信与协同行为共同完成共享任务目标。
问:当前军用无人机是否已实现完全自主
答:当前现役军用无人机多采用混合自主模式——具备导航、目标识别、避障等自主功能,但根据现行交战规则,武器发射决策仍保留“人在回路”或“人在环上”机制。
问:人工智能赋能的国防无人机如何提升任务成效
答:它们能够在机载端实时处理传感数据,相比依赖人工地面分析的系统,可实现更快速的威胁检测、降低带宽依赖并加快决策速度。
问:各国军方为何投资蜂群无人机技术
答:蜂群具备韧性、成本效益高的规模化优势,并能压制传统防空系统,使其成为高价值有人/无人平台极具战略价值的补充力量。
问:哪些行业研发自主作战无人机系统?
答:主要研发主体包括大型防务承包商、专业无人机制造商,以及专注于国防的AI与机器人公司,它们通常与政府研究机构及武装部队合作开展测试与集成。
结语
自主性、人工智能与蜂群协同的融合,正在从战场侦察到战略威慑的各个层面重塑国防作战。随着国防自主无人机系统日趋成熟,随着军用蜂群无人机技术从试验阶段迈向实战部署,率先投资具备互操作性、AI赋能平台的防务机构,将在未来冲突中占据最佳优势地位。
对于防务技术提供商、系统集成商与采购决策者而言,信息已然明确:自主与蜂群无人机能力已非新兴趋势,而是正在成为现代军事战备的基础要求。
参考来源:https://www.defence-industries.com/articles/best-drone-technologies-for-defense
摘要 随着人工智能(AI)赋能系统与人类操作员的融合日益深入,各领域对无缝协作的需求愈发迫切。精准的人类行为建模可使人工智能系统预判人类决策,并主动调整自身行为以辅助人类完成复杂任务。现有研究多聚焦于个体人类行为建模,本文则针对面向协作目标的异构团队内部人类行为进行建模。此类团队成员通常具备各异的技能、知识与认知水平,这些因素显著影响其决策过程。本文将团队行为建模为一种次优的混合式多智能体强化学习范式,通过融合集中式训练与“集中式/分散式”混合执行机制,模型能够刻画从完全集中式到完全分散式乃至中间状态的连续团队行为谱系。本文对各团队成员的认知水平与沟通能力进行了量化建模,实现了基于观测数据对上述参数的逆学习推断。数值实验验证了该框架在不同场景与团队构成下的鲁棒性与准确性,凸显了其在模拟复杂人类交互行为方面的有效性。
关键词:逆学习;多智能体强化学习;人类行为建模
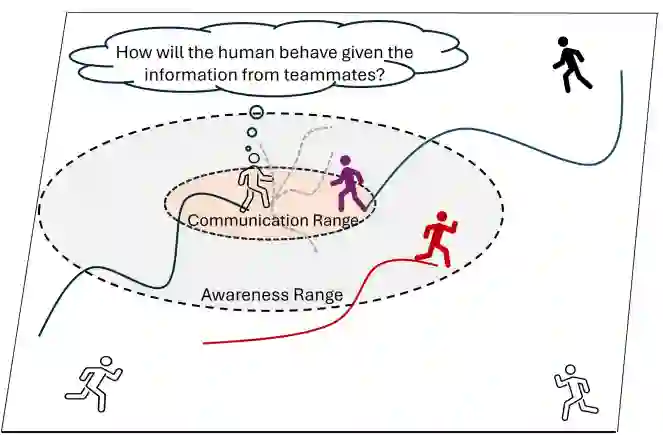
图1 团队场景下人类沟通范围与认知范围示意图。位于中心位置的个体可与紫色智能体(处于沟通范围内)进行信息交互,并能观测到红色智能体(处于认知范围内)。
随着人工智能系统日益融入传统由人类主导的领域,实现人机高效协作变得至关重要。典型案例包括:网络空间内协助人类检测并抵御对抗攻击的人工智能系统(Sarker, 2023;Kazeminajafabadi和Imani, 2023);制造业中与人类协同作业以提升效率与精度的机器人(Matheson等, 2019);未知环境中由自主系统辅助人类导航与分析的人工智能驱动勘探任务(Wu等, 2019;Shafti等, 2020;Imbiriba等, 2019);以及灾害响应等场景中辅助关键决策的安全应用(O'Neill等, 2022;Unhelkar等, 2020)。因此,构建精准的人类行为模型是实现无缝人机协作的基础,有助于人工智能体预判人类行动,进而提升安全性与协作效能(Hong等, 2020;Lin等, 2024)。
近年来涌现出多种人类行为建模方法,包括通过监督学习模仿人类动作的模仿学习(Le Mero等, 2022),以及推断驱动人类决策潜在奖励函数的逆强化学习(Arora和Doshi, 2021;Hoffman等, 2024;Casper等, 2023)。其中,最大熵逆强化学习(Ziebart等, 2008)等代表性方法通过建模最大化奖励与熵的行为来处理不确定性。此外,生成对抗模仿学习(Ho和Ermon, 2016)利用对抗训练机制模拟人类行为。然而,这些方法主要设计用于个体行为建模,依赖于个体执行相似任务的轨迹数据,已广泛应用于自主导航(Vasquez等, 2014;Alali和Imani, 2024)、人机交互(Liu等, 2022)及博弈场景(Cao和Xie, 2022;Hosseini和Imani, 2024),其优势在于单智能体行为刻画(Wilder等, 2021)。尽管这些方法在个体建模上成效显著,但由于团队动力学的复杂性,将其拓展至多智能体场景仍面临挑战。
近期将逆强化学习拓展至多智能体场景的研究,旨在将单智能体模型推广至人类团队。然而,这些方法往往只能捕捉同质团队行为,即所有成员均在完全集中式或完全分散式模式下运作。集中式模型假定所有成员能够持续、完整地获取彼此信息(Natarajan等, 2010;Suresh等, 2024),但这在复杂的现实环境中并不现实——个体通常仅掌握局部或角色特定的队友信息(Zarei和Shafai, 2024)。另一方面,完全分散式模型(如基于QMix(Rashid等, 2020)或多智能体近端策略优化(PPO)(Yu等, 2022;Ahmad等, 2024)的模型)将团队视为孤立个体的集合,成员间不交换信息,亦不了解队友状态。此类模型同样无法反映真实人类团队的异质性,即成员在沟通技巧、知识储备与认知水平上的差异。这些属性显著影响团队内部的互动与决策过程,导致复杂的团队动力学,是单纯的集中式或分散式模型难以充分刻画的(Tabrez等, 2020;Zhang等, 2025;Iftikhar等, 2023)。
本文提出一种创新性混合框架,旨在解决现有团队动力学建模的局限性。该框架提供了一种灵活且鲁棒的模型,充分考虑了异构人类团队协作决策中个体差异化的认知水平与沟通能力。例如,部分成员可能与队友频繁交流信息,而其他成员则可能仅掌握有限的队友信息甚至一无所知。本模型重点捕捉影响人类决策的两大核心特征:认知水平,反映个体对队友状态的掌握程度;沟通能力,表征个体共享任务相关信息的广度。我们假设沟通围绕团队需协同完成的一组子任务展开,从而实现对团队高层共享心智的有效建模。模型采用集中式训练与“集中式/分散式”混合执行机制,能够学习适配不同认知水平与沟通技能的团队行为策略。基于可获取的观测状态序列数据,本研究构建了逆学习框架,以估算最能解释观测数据的全体成员认知水平与沟通能力参数。分析结果表明,完全集中式与完全分散式模型均为本文模型的特例,而所提模型能够覆盖更广泛的团队行为谱系。此外,本文还论证了代表个体决策随机性程度的人类理性水平如何影响团队建模性能。数值实验验证了该框架在不同团队构成与场景下的鲁棒性与适应性,证明了其在精准建模复杂异构人类交互行为方面的有效性。
摘要
现代指挥、控制、通信、计算机、网络、情报、监视与侦察(C5ISR)环境对任务指挥官(MC)的注意力分配提出了极高要求。在这类高风险、高代价的复杂场景中,注意力分配失当可能引发严重后果。本研究依托高保真模拟军事指挥中心,探究了基于注视驱动的注意力引导(含纯视觉与多模态两类)自适应决策支持工具(DST)的有效性,以及影响任务指挥官绩效的潜在注视动力学机制。为解析被试与注意力引导型自适应决策支持工具交互过程中的注视与注意力动态特征,研究采用递归量化分析(RQA)方法处理眼动追踪数据,并运用基于贝叶斯信息准则(BIC)的逐步回归模型识别可预测绩效得分的递归量化分析指标。回归结果显示,多模态自适应决策支持工具的绩效表现显著优于纯视觉注意力引导型自适应决策支持工具。递归量化分析指标中,平均对角线长度(L)与绩效水平呈负线性相关,而熵值(ENTR)与绩效呈正线性相关。此外,递归率(RR)、确定性(DET)与熵值(ENTR)均与绩效存在非线性二次关系,其中递归率与确定性呈现符合耶克斯-多德森定律的倒U型曲线特征。上述发现表明,动态任务环境要求决策者兼具结构化扫描行为与动态化扫描策略,方能实现最优绩效。
关键词:决策支持工具;递归量化分析;指挥与控制
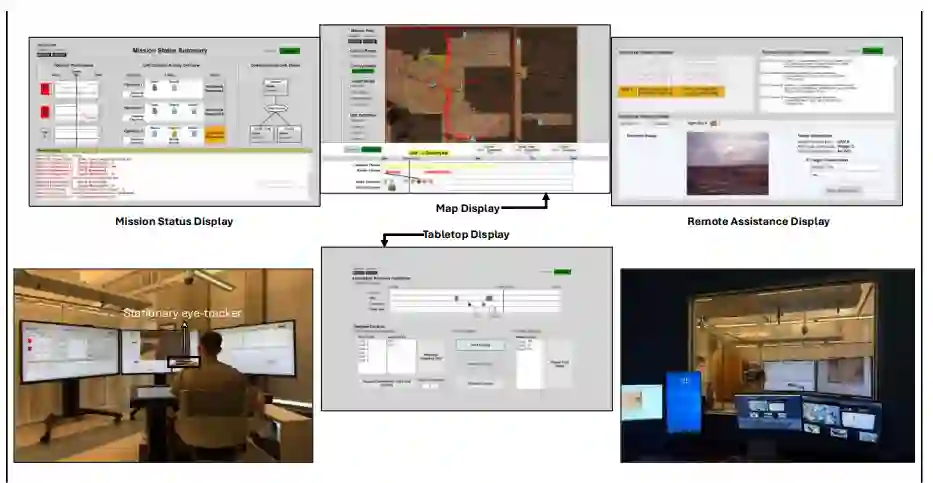
图1 模拟测试平台及其显示布局。任务指挥官依托模拟无人机与E-3空中预警与控制系统获取的信息开展监控并制定决策。
现代指挥、控制、通信、计算机、网络、情报、监视与侦察(C5ISR)环境已呈现数据饱和态势,对任务指挥官的认知极限构成了前所未有的挑战。尽管人工智能与实时传感技术的进步旨在提升战场态势感知清晰度、降低认知负荷,但海量数据的涌入速度往往超出人类信息处理能力的上限。在此类场景中,维持态势感知(SA)已不再仅仅是获取数据访问权限的问题,更关乎视觉注意力资源的高效分配,直接关系到任务成败(Demir等,2023;Endsley,2001;Endsley等,2003;Humr等,2023)。当任务指挥官需要在高信息密度的界面中进行导航时,“信息漏检”风险便成为决策链路中的关键脆弱点(Curts和Campbell,2001;Endsley和Garland,2000)。
信息过载易在现代军事指挥体系中形成注意力瓶颈(Giles,2019;Shackelford和Lily,2026)。学界已充分证实,人类认知资源具有有限性与易耗竭性(Rogers,2023;Tsotsos等,1995),且在信息过载状态下注意力会自然分散(C. D. Wickens,1976)。在C5ISR这类高风险场景中,注意力分散可能导致作战链路阻塞。虽然选择性注意机制有助于任务指挥官优先处理高价值信息,但也可能诱发“隧道视觉”效应,导致关键边缘信号漏检、响应显著延迟或态势感知丧失(Endsley等,2003)。C5ISR环境要求任务指挥官同时监控多个视觉显示屏,这对注意力管理能力提出了严峻考验。在此类动态环境中,精准的注视行为与有意识的认知投入——二者均以合理的注意力分配为前提——是构建有效信息处理闭环、支撑及时决策的必要条件。当分散注意力的需求超出任务指挥官的认知容量时,由此产生的认知摩擦将导致决策失效,表现为重要数据虽被感知却未被加工为决策输出。因此,当代战场与C5ISR环境迫切需要能够引导人类指挥官注意力的辅助工具。 眼动追踪是人因工程文献中研究注意力分配最常用的方法。多数眼动研究聚焦于静态兴趣区(AOI)内的注视次数、注视时长等时间汇总指标。然而,这类常规方法往往忽略了人类注视行为固有的时间依赖性与动态组织特征(Mahanama等,2022)。通过引入时间维度,眼动分析能够揭示视觉注意力动态中更为精细的特征,例如扫视路径结构、注视(不)稳定性及注视回归模式。因此,视觉注意力动态特征不仅可作为区分不同实验条件的差异化指标,更能成为预测整体决策绩效的可靠依据。
在Jei等(2026)的前期研究中,作者测试了面向地面车队护航任务监督任务的、具备自适应注意力引导功能的决策支持工具。实验结果表明,自适应注意力引导决策支持工具显著提升了被试的整体绩效,且该效应在具备相关经验的被试群体中更为显著。但前期研究存在一个局限:注意力引导仅以视觉形式呈现。在指挥官需从多块显示屏获取信息的场景中,部分屏幕可能完全处于指挥官的视野范围之外。此时,无论视觉引导的显著性多高,相关信息仍可能被漏检。因此,亟需研发多模态自适应注意力引导决策支持工具。根据多重资源理论(MRT;Wickens,2008,2021),当信息通过同一通道(如视觉)呈现时,人类认知资源消耗速度更快,因为多条信息需竞争同一认知资源池;而当信息通过不同通道(如视觉与听觉)呈现时,认知资源竞争概率显著降低。此外,不同形态的信息呈现方式还能提升信息的离心度与显著性(C. Wickens,2008,2021)。N-SEEV模型指出,人类操作员注意到某事件或信息的概率随信息离心度与显著性的提升而增加(Wickens,2015;Wickens等,2009)。尽管事件预期价值与重要性也会提升注意概率,但这属于自上而下的认知要素,难以通过注意力引导等外部助推手段直接调控。
多项研究证实,多模态组合能更有效地引导人类注意力至目标区域。例如,Reyes和Alles(2021)发现,在网络物理环境中,视觉与听觉线索的组合显著提升了注意力引导效果。此外,Sheth和Shimojo(2004)及Van der Burg等(2009;2008;2008)的研究表明,多模态刺激能增强视觉搜索任务中视觉目标的显著性。尽管多模态注意力引导已在汽车驾驶(Calvi等,2021)与军事决策场景(Savick等,2008)中得到应用,并显示出提升人类绩效的潜力,但据我们所知,针对军事C5ISR监督控制场景中多模态实时注意力引导的研究仍存在空白。为填补这一空白,本研究在模拟C5ISR环境中开展实验,旨在评估:1)多模态自适应注意力引导决策支持工具是否能进一步提升任务指挥官的整体绩效;2)不同实验条件下视觉注意力动态特征的差异;3)哪些可靠的眼动指标可有效预测任务指挥官的绩效表现。

本定性案例研究旨在探究设计专业初学者与生成式人工智能的交互如何影响其主导共情访谈的准备与实施过程。本研究具有重要价值,其将人机协作(HAIC)(Song等,2024a)框架应用于共情访谈场景,验证了人工智能作为辅助创意激发者而非唯一权威主体的新型协作模型。研究采用归纳式内容分析法(ICA),以学生与生成式人工智能的聊天记录、访谈转录稿、访谈录音及标准化量规评估结果为基础,构建了6个最大变异案例。研究结果表明,问题生成阶段的人机协作深度直接影响共情访谈质量:未经编辑直接被动采纳ChatGPT输出的学生,其访谈呈现僵化、重解决方案的特征,阻碍共情能力培养;反之,若学生对生成式人工智能输出进行高频修改(手动优化ChatGPT生成的问题以消减偏差、强化叙事导向),则可通过积极倾听与跟进追问建立更深层次的共情联结。上述发现提示,若在设计思维中以共情访谈等人本任务为依托使用生成式人工智能,设计教育工作者及相关从业者必须教授提示词工程与输出优化方法。此外,引入评估性量规与结构化生成式人工智能使用规范,可推动学生从被动采纳者向主动协作者转变,仅需小幅调整输出优化行为,即可确保生成式人工智能对人本设计技能形成补充而非替代效应。
引言
2022年末,生成式人工智能(GenAI)——一类可自主生成文本、图像、计算机代码等原创内容的AI工具(Dhar,2024)——的问世引发范式转移,重塑了技术格局。布莱辛格(2023)将这一节点称为“ChatGPT时刻”,彼时ChatGPT是普及度最广、可及性最高的生成式人工智能工具。ChatGPT是大型语言模型(LLM)(Yao等,2024)的典型代表,这类复杂的神经网络经海量数据集训练而成,构成了诸多生成式人工智能工具的基础。基于各类大模型构建的其他生成式人工智能工具还包括谷歌Gemini(文本生成)、DALL-E(图像生成),以及NotebookLM(科研与笔记管理)等专用应用。“ChatGPT时刻”的特征是早期采纳者群体呈指数级扩张,工具展现出媲美人类的内容生成能力,且使用门槛大幅降低(Blechinger,2023)。ChatGPT可完成大量创意与技术类任务,例如撰写文章、生成编程代码以构建初步设计方案。生成式人工智能工具的高可及性推动其用户群体持续扩大,在校学生与行业从业者纷纷将其嵌入日常工作流(如软件开发)与教学场景(如科研、头脑风暴)(Brynjolfsson等,2023)。
生成式人工智能的影响远超个体应用场景,已渗透至知识密集与创意类领域(AlZaabi等,2023)。例如建筑师可基于一组设计约束,借助生成式人工智能快速生成多套建筑平面布局方案;平面设计师可在短时间内产出大量营销视觉素材。在以人为本的用户体验/用户界面(UX/UI)领域,设计师利用生成式人工智能绘制用户流图(可视化用户完成任务的全流程),助力快速原型构建。在上述职业场景中,生成式人工智能已承担多重功能,包括但不限于辅助创意生成、自动化重复性任务、为设计师提供灵感(Zhou和Lee,2024)。然而,这类技术融合也引发了关于人类在创意活动中角色定位的争议(Zhou等,2025)。争议核心在于,生成式人工智能应被视为可被驾驭的高级工具、创意过程中的协作伙伴,还是人类的完全替代者(Furtado等,2024)。当生成式人工智能的能力与人类典型技能(如创造力、情感理解)重叠时,相关争议尤为激烈(Zhou和Lee,2024)。本论文立足这一争议,聚焦生成式人工智能能力与设计流程中“共情”这一人类特质的交叉领域。共情是指与他人思想、情感建立联结的能力(Fernandez和Zahavi,2020),是设计思维流程的基础阶段(Brown,2008)。共情是一个多维构念,包含三个核心维度:认知维度(理解感受)、情感维度(共感感受)与意动维度(基于感受采取行动)(Khan等,2022;Watt,2007)。在设计实践中,共情理解能够帮助设计者突破表层假设,深度把握用户需求,进而开发出创新性强、影响力大的解决方案(Carmel-Gilfilen和Portillo,2016;Devecchi和Guerrini,2017;Gasparini,2015)。
人工智能引发的范式转移也给设计教育带来了教学层面的挑战,其融合并非中性技术迭代,而是承载着意识形态与制度层面的深层意涵。传统设计教育的根基是批判性思维、问题解决、模糊情境应对等人本技能,而生成式人工智能可复刻学生作业、替代人类思考,令传统教育者陷入困境(Li等,2024)。尽管生成式人工智能可提升效率、加速内容生成,但其与设计流程的强过程性、人文性属性存在潜在张力。除学术诚信层面的担忧外,生成式人工智能的融入还带来了认知与社会关系层面的风险,共情访谈场景便是典型代表。随着AI模型复杂推理与综合能力的不断提升,学生正面临并将持续面临将认知任务卸载给AI的诱惑(Hooper,2025;Viola和Chiarella,2026)。在高度依赖模糊情境应对能力的设计教育中,这类认知卸载可能导致任务替代:学生不再主动参与共情访谈问题生成的任务,而是直接交由AI完成。此外,过度依赖AI生成的高度可信、权威性强的输出,还可能侵蚀设计初学者的认知能动性,使其从知识建构的主动角色退化为被动学习者(Varghese,2025;Yang和Ma,2025)。
已有研究者就生成式人工智能在设计领域的应用展开探索,发现当生成式人工智能辅助明确问题定义时,可显著提升创意产出的总量(Kim和Maher,2023)。黄与元(2021)指出,参与者以生成式人工智能替代真实人类用户作为反馈源时,产出的设计方案质量更高,原因在于生成式人工智能的评判倾向远低于人类。在设计师自信心相关研究方面,钟等(2022)发现人机协作关系较为复杂:能力较弱的设计师难以识别生成式人工智能基于用户需求、设计质量相关输入生成的输出中存在的缺陷。多位学者已就生成式人工智能对创意生成的影响(Koh,2024)、设计分析阶段的作用(Spreafico和Sutrisno,2023)、ChatGPT对问题定义与构思阶段的支撑价值(Al-sa'di和Miller,2023)、设计可视化领域的应用(Terenzi等,2024)展开研究。另有学者探索了人机协作在设计全流程的嵌入路径,包括早期构思(Camburn等,2020)、晚期构思(Yuan和Moghaddam,2020)、设计团队管理(Gyory等,2022),以及辅助团队问题解决(Zhang等,2021)与复杂系统设计(Song等,2022)。与上述偏流程化、技术化的应用研究不同,针对设计领域共情等人本特质的相关研究仍处于空白状态。
本论文所回应的研究缺口,并非仅关注生成式人工智能在设计教育中的整体角色,更聚焦其对设计流程中某一特定且对新手极具挑战性的阶段的影响:即针对设计对象建立共情理解的过程(Li和Hotta-Otto,2023;Zhu和Luo,2023)。尽管共情在设计中的重要性不言而喻,设计专业初学者仍面临共情培养的诸多障碍,主要表现为将共情与共感混淆,难以把握共情的抽象属性(Gudur,2023),以及在问题界定、用户情绪解读方面存在困难(Dahiya和Kumar,2019;Kim和Ryu,2014)。专家设计师拥有多年隐性经验积累,而初学者的共情认知尚处于萌芽阶段(Chen等,2022)。初学者往往难以突破表层理解,缺乏基于用户洞察开展跟进追问、或在捕捉到细微情绪线索时调整访谈方向的经验(Cross等,1994)。
这并不意味着设计专业初学者完全不具备共情能力。但当前存在一种“共情悖论”:生成式人工智能可快速生成高质量的共情访谈问题,但尚不清楚该工具的使用会如何影响初学者与真实用户的实际互动。核心张力在于,初学者与AI的交互究竟是停留在被动采纳层面——即直接将AI生成的输出作为最终访谈脚本,还是进阶为迭代优化模式——即设计者始终保有对流程的认知能动性(Varghese,2025;Yang和Ma,2025)。在人机协作(HAIC)框架下,当生成式人工智能处于Role V位置时,它不仅是文本生成器,更是人类创造力的灵感来源(Song等,2024a;Zhou等,2025)。对于共情认知尚处萌芽阶段的设计初学者而言,这类协作可帮助其突破问题界定与用户情绪解读的初始障碍(Chen等,2022;Dahiya和Kumar,2019;Kim和Ryu,2014)。 成功的人机协作不应沦为导致访谈僵化、流于清单式核查的“拐杖”(Weilbacher等,2026),而应发挥共情信任赋能机制的作用(Song等,2024a)。AI作为创意激发者提供结构化起点,可帮助初学者突破表层假设,投身于共情访谈所需的复杂诠释性工作(Carmel-Gilfilen和Portillo,2016;Devecchi和Guerrini,2017)。这种协作可将初学者的角色从AI输出的被动使用者转变为主动引导人本对话的主导者,确保生成式人工智能成为可信赖的协作者,对设计者应对模糊用户需求的能力形成补充而非替代(Gasparini,2015;Song等,2024a;Zhu和Luo,2023)。
目前学界已对心理层面的共情(Chang-Arana等,2022)、设计流程中的共情环节(Devecchi和Guerrini,2027)、初学者共情能力短板(Dahiya和Kumar,2019)形成了充分认知。相关研究也已探讨了生成式人工智能的创意生成能力(Camburn等,2020)与人机交互机制(Song等,2024a),但上述主题的融合研究仍处于空白。鉴于上述多维度研究缺口,探究三者间的交互作用可为设计教育提供有益的教学启示,帮助初学者更深入地理解复杂问题背后客户面临的真实困境。要厘清上述机制,必须观察设计专业初学者如何在计算能力与人类情商之间寻求平衡。本研究依托宋等(2024a)提出的人机协作(HAIC)框架,探究不同的用户策略如何影响AI在共情访谈这一高度人本任务中作为可信协作者的效能。研究采用与人机协作框架适配的归纳式内容分析法,对数据进行编码以识别独特的协作案例。通过梳理从被动采纳脚本式提问到主动迭代优化的行为谱系,本研究揭示了初始AI提示策略如何直接决定共情访谈的整体走向。
本论文共分为五章。本章为引言,第二章为文献综述,系统梳理设计思维、共情的多维属性,以及人机协作框架的理论意涵。第三章阐述定性案例研究的方法论,介绍研究依托的入门设计课程背景、目的抽样策略,以及用于评估学生交互行为的归纳式内容分析法。第四章呈现研究发现,归纳为数据中观察到的六类典型行为案例。第五章讨论研究发现对设计教育的启示,分析不同水平的生成式人工智能融入对初学者共情培养能力的影响,并为未来教学实践与学术研究提供实操建议。
1.1 研究目的
本研究旨在探究设计专业初学者与生成式人工智能的交互模式,以及这类交互如何影响其所在设计思维课程中共情访谈的准备与实施过程。具体而言,本研究考察生成式人工智能作为协作工具对访谈问题生成、学生主导共情访谈实施的影响。研究采用定性案例研究设计回应研究问题,案例构建所用数据包括:1)学生与生成式人工智能的对话记录;2)师生共创的访谈问题集;3)学生主导访谈的录音与转录稿;4)用于评估访谈问题质量的量规评分结果(Nelsestuen和Smith,2020)。
1.2 研究问题
- 设计专业初学者将生成式人工智能作为协作工具使用时,其交互行为如何塑造学生主导共情访谈的准备与实施过程?
1.3 研究意义
本研究将人机协作框架应用于设计思维中的共情培养场景,丰富了生成式人工智能的相关研究体系。现有研究多聚焦生成式人工智能的效率提升价值,本研究则将其视为协作工具或“共情同伴”,有望重塑设计学习者与设计流程之间的关系(Kim等,2024;Yang和Ma,2025)。通过考察人机协作从被动采纳向迭代优化的转型过程,本研究验证了共创设计的新模型:学生在协作中始终保持主动主体地位,AI仅作为辅助创意激发者发挥作用(Song等,2024a)。对于设计教育工作者而言,本研究回应了斯托克(2026)提出的“共情门槛”问题——即无经验初学者在开展高利害人际访谈时面临的困境。研究表明,生成式人工智能可模拟真实、低风险的共情访谈练习环境,帮助学生在接触真实用户前提升判断能力(Marikar,2025;Stock,2026)。通过将研究焦点从最终设计产出转向设计流程本身,本研究可为教师提供具备理论支撑的框架,助力其在不损害学生认知能动性的前提下,为复杂关系类任务提供支架支持(Varghese,2025)。 随着生成式人工智能通过流程自动化、辅助人类决策持续重塑专业设计实践,新型“元技能”的重要性日益凸显(Marikar,2025)。本研究的另一重要价值在于明确了若干关键的人本技能(如提示词工程、判断力、创意生成、人机对话能力),这些技能将成为下一代设计师的核心素养。研究同时凸显了AI素养的必要性:AI素养并非单纯的技术技能,而是将其作为协作伙伴,保留人类在审美与文化判断中的“人在回路”要求(Song等,2024a;Yang和Ma,2025)。
博士论文 | 面向大模型推理的内存高效算法

导读
大模型推理的核心矛盾,正在从“算不动”转向“搬不动”。训练阶段常被视为算力竞赛,但在真实服务中,模型要以自回归方式逐 token 生成,每一步都需要读取模型权重、访问历史 KV cache,并在显存、片上缓存和互联之间不断搬运数据。当上下文窗口、批量请求、多轮代理任务和长链推理同时增长时,推理系统的瓶颈会越来越明显地落在内存容量与内存带宽上。 Coleman Hooper 的 Berkeley EECS 2026 博士论文《Memory-Efficient LLM Inference Algorithms》围绕这一问题展开系统研究。论文不是只提出一个孤立压缩技巧,而是先从硬件趋势、应用趋势和性能建模解释为什么 LLM 推理会撞上“内存墙”,再分别从模型权重、KV cache、共享上下文注意力和推理时注意力近似四个方向提出算法与系统方案。 这篇论文的价值在于把“内存效率”拆成了多个层次:权重能否更低比特存储?长上下文的 KV cache 能否量化?固定上下文场景是否需要每次都读取全部 token?复杂推理中,是否可以只对最重要的键做精确注意力、对更远的信息做聚类近似?这些问题正对应今天 LLM 服务系统的真实痛点。
论文信息
论文题目:Memory-Efficient LLM Inference Algorithms 作者:Coleman Hooper 机构:University of California, Berkeley,Electrical Engineering and Computer Sciences 技术报告:UCB/EECS-2026-175 时间:2026 年 5 月 15 日 论文链接:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2026/EECS-2026-175.pdf 学位信息:该文为 UC Berkeley 电气工程与计算机科学博士论文,委员会成员包括 Kurt Keutzer、Yakun Sophia Shao 与 Joseph Gonzalez。
一、LLM 推理为何撞上内存墙
论文开篇提出一个直接判断:大语言模型推理正在变成内存系统问题。模型规模持续扩大,服务端 GPU 的峰值 FLOPS 增长很快,但显存带宽、互联带宽和容量增长慢得多。于是,硬件“会算”不等于系统“能快”:当每个 token 的计算强度不足以填满计算单元时,GPU 大量时间会花在等待数据从内存中读出。
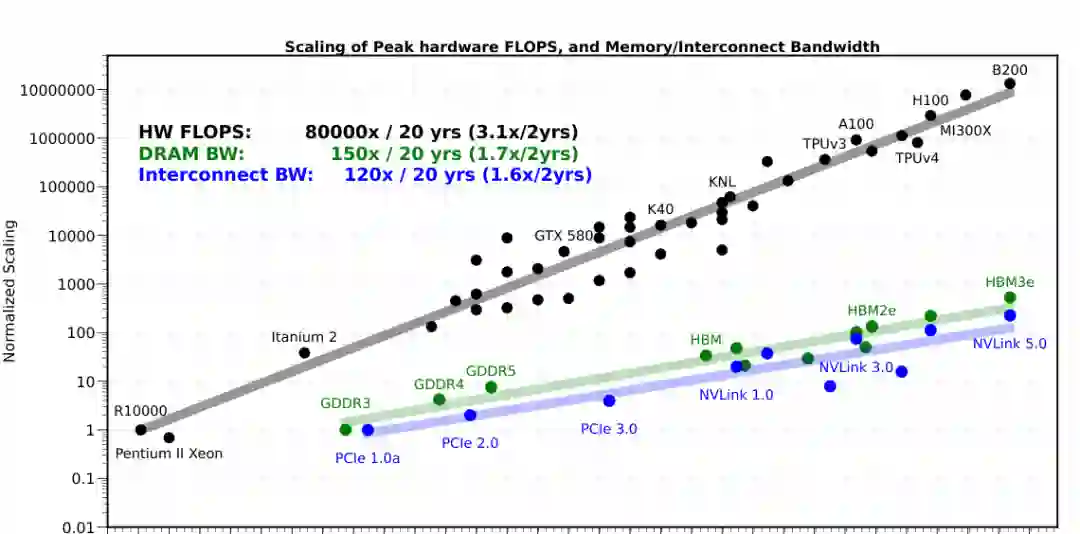
这种矛盾在 LLM 推理中尤其突出。自回归解码阶段每生成一个 token,都需要重新执行一次模型前向传播。即使 batch 较小、每步计算量有限,系统仍然必须加载大量权重和历史 KV cache。对在线服务而言,这意味着延迟不只取决于矩阵乘法速度,也取决于每一步从显存搬运多少字节。 应用趋势进一步放大了问题。长上下文模型、检索增强生成、多轮对话、代码代理、工具调用和复杂推理都要求模型保留越来越多历史 token。短上下文时,模型权重通常是主要内存占用;上下文拉长后,KV cache 很快成为主导项。论文用 LLaMA-7B 的示例展示,当序列长度从 512 扩展到 128K 时,内存压力会从“权重为主”转变为“KV cache 为主”。 这就形成了论文的总体路线:如果瓶颈来自内存,那么算法设计应围绕“少存、少读、读更重要的数据”展开。
二、找到推理瓶颈
第二章从 Transformer 解码结构和 Roofline 模型出发,分析 LLM 推理中计算量、内存访问量和算术强度之间的关系。论文区分了预填充和解码两个阶段:预填充可以并行处理输入序列,通常更接近大矩阵乘法;解码则逐 token 串行进行,容易退化为大量矩阵-向量运算,因此更容易受内存带宽限制。
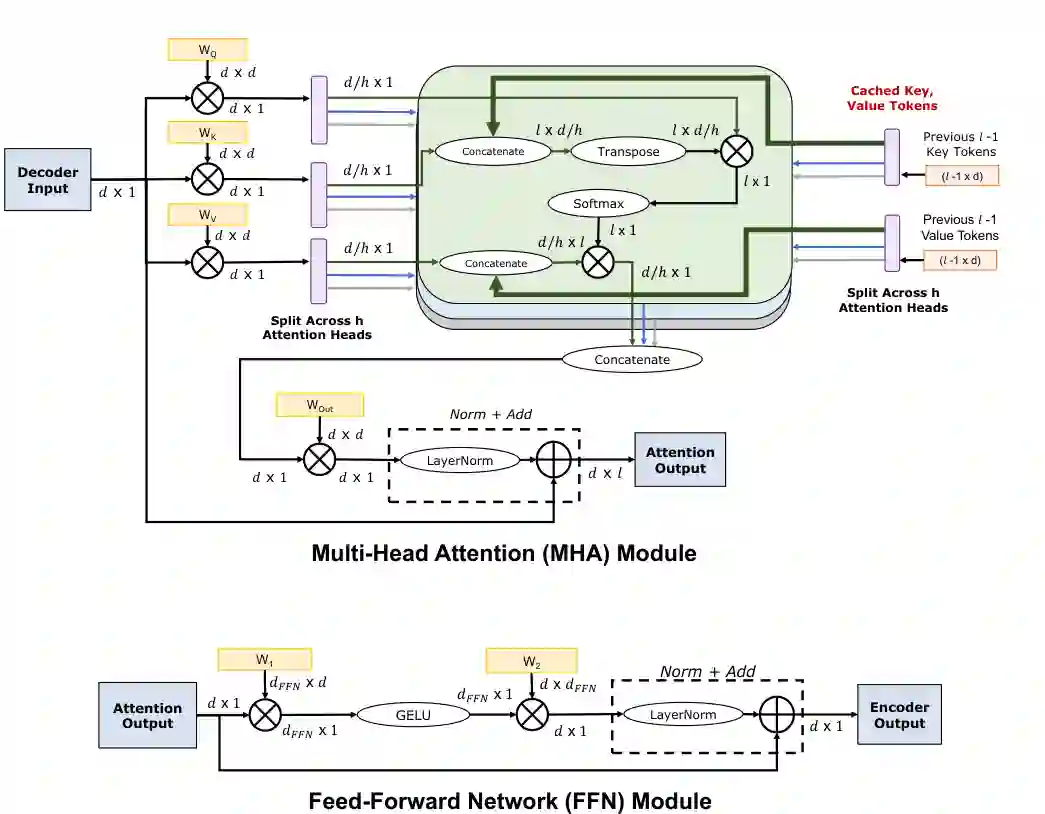
论文用 Transformer decoder 的计算图说明,每一层都包含 Query、Key、Value 投影、多头注意力、输出投影和前馈网络。对单步解码而言,输入 token 数很少,但需要访问完整权重和历史 KV cache;这使得很多操作无法充分利用 GPU 的峰值计算能力。
作者进一步提出多 regime 分析:当上下文较短时,权重读取是主导;当上下文增长时,KV cache 读取变得越来越重要;当 batch、模型大小和上下文长度共同变化时,系统会在不同瓶颈之间切换。这个分析为后续章节奠定了结构:第三章压缩权重,第四章压缩 KV cache,第五和第六章减少注意力阶段需要加载的 token。
三、压缩模型权重
第三章提出 SqueezeLLM,用 Dense-and-Sparse Quantization 压缩模型权重。权重量化的目标很直接:降低模型参数占用,减少推理时从显存读取的字节数,从而在容量受限或带宽受限场景中提升可部署性和吞吐。
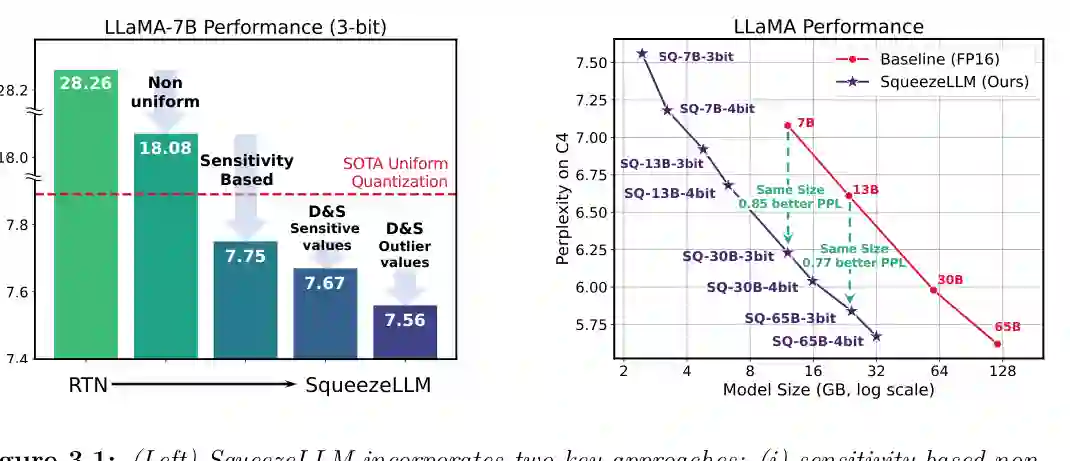
普通均匀量化的问题在于,它默认所有权重值都同等重要。但 LLM 权重分布中往往存在更敏感的值和离群值,直接低比特压缩会显著损害模型输出。SqueezeLLM 的两个关键设计是:一是基于敏感度的非均匀量化,把量化桶更密集地分配给重要取值;二是 Dense-and-Sparse 分解,把大部分权重用低比特密集格式表示,同时保留少量敏感值或离群值为稀疏高精度项。 这种设计的含义是,系统不再把所有参数“一刀切”压缩,而是把有限的精度预算分给最影响输出质量的部分。对推理系统而言,这不仅降低显存占用,也减少每次解码需要加载的权重字节数;对模型质量而言,它避免了低比特量化常见的困惑度急剧上升。 这一章的启发是:权重量化不是单纯的数值格式替换,而是需要结合模型敏感性、离群值结构和底层 kernel 实现共同设计。只有当压缩格式能被硬件高效读取和计算时,量化才会真正转化为推理收益。
四、量化长上下文 KV Cache
当上下文长度不断增长时,权重不再是唯一大头。每一层注意力都需要缓存历史 token 的 Key 和 Value,用于后续 token 的生成。序列越长、batch 越大、层数和 head 数越多,KV cache 的内存占用就越高。第四章提出 KVQuant,研究如何量化 KV cache activation,从而支持更长上下文的推理。
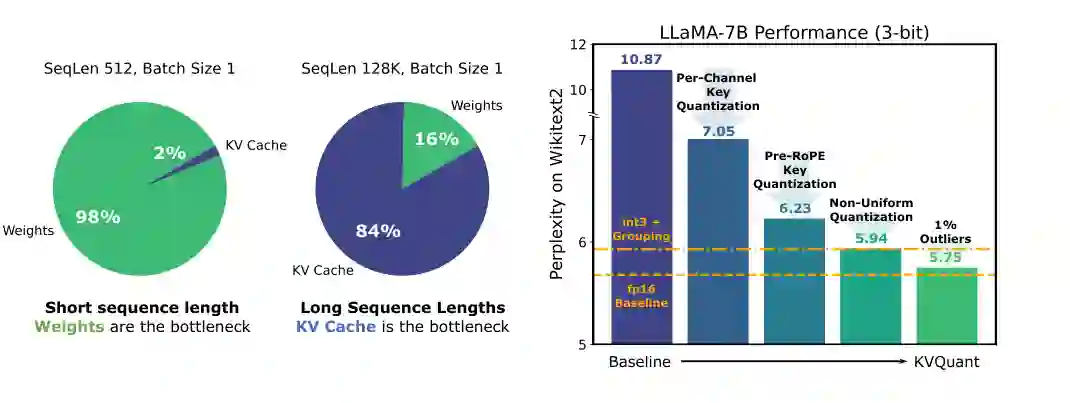
KV cache 量化与权重量化并不完全相同。权重是静态的,可以离线分析和压缩;KV cache 是推理过程中动态产生的 activation,分布会随层、head、token 位置和 RoPE 等机制变化。论文因此重点分析 Key/Value activation 的分布特征,并讨论在量化前后如何处理离群值、通道差异和位置编码影响。 KVQuant 的核心目标是让长上下文推理不被 KV cache 容量直接卡死。论文图示中,LLaMA-7B 在 128K 序列长度下,KV cache 可占到主要内存;通过 3-bit 量化,缓存 activation 的内存足迹可大幅降低,同时控制困惑度退化。对服务系统而言,这类方法可以把“可容纳上下文长度”和“并发请求数”同时向上推。 这一章也揭示了长上下文系统的关键约束:长上下文不仅贵在预填充计算,更贵在后续每个 token 都要反复访问庞大的历史缓存。如果不压缩或筛选 KV cache,长上下文会持续吞噬显存带宽。
五、只加载重要上下文
第五章从另一条路出发:既然注意力并非对所有历史 token 都同等依赖,能否只加载当前 query 真正需要的 Key?Squeezed Attention 针对固定上下文处理场景提出这一想法。典型场景包括大量请求共享同一长文档、系统提示、代码库或知识库前缀;这些上下文可以在离线阶段预处理。 论文的做法是先根据语义相似性对固定上下文的 Key 进行聚类,并用 centroid 表示簇。在线推理时,模型先把当前 query 与粗粒度 centroid 比较,定位可能重要的簇,再逐层细化到更小簇,最终只对检索出的重要 Key 计算精确注意力。
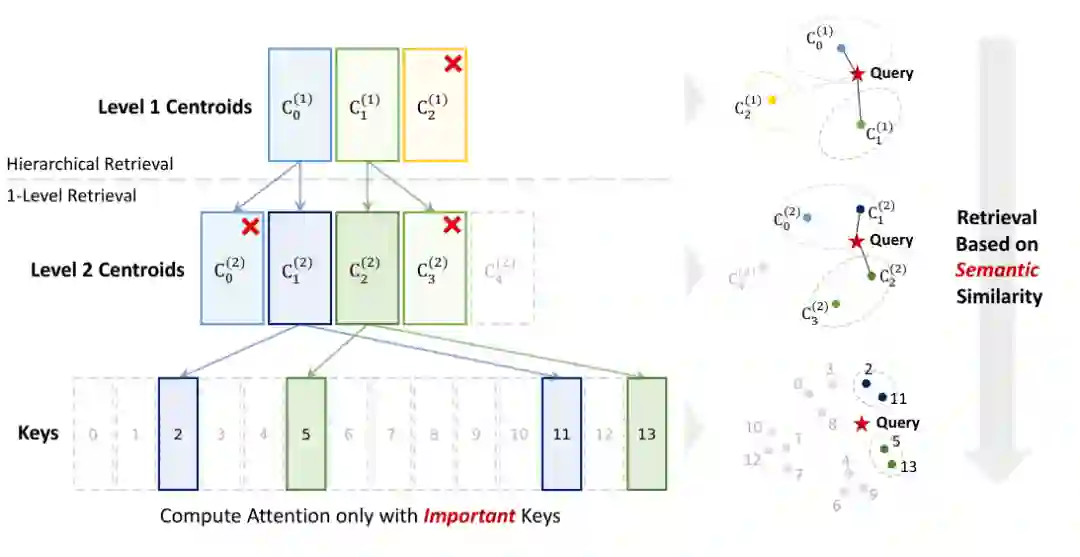
这相当于把“全量扫描历史 token”改造成“层级检索 + 局部精确计算”。它的优势在于没有简单丢弃上下文,而是根据当前 query 动态决定哪些 token 值得加载。与固定稀疏模式相比,Squeezed Attention 更强调语义相关性;与完全注意力相比,它显著减少了 KV cache 读取和注意力计算。 这一章特别贴近现实部署。许多企业和科研助手类应用会让大量用户共享同一文档集合或系统上下文。如果每个请求都重复读取全部上下文,成本会非常高;如果能对共享前缀离线建索引,在线只读取最相关 token,就能把长上下文能力转化为更可承受的服务成本。
六、高效推理中的 Multipole Attention
第六章提出 Multipole Attention,进一步面向长链推理场景优化注意力。与 Squeezed Attention 只对重要 token 做精确注意力不同,Multipole Attention 的思想更像一种分层近似:距离当前 query 更近或更重要的 Key 保持精确计算;更远、贡献较分散的 Key 则用代表性 centroid 近似其注意力贡献。
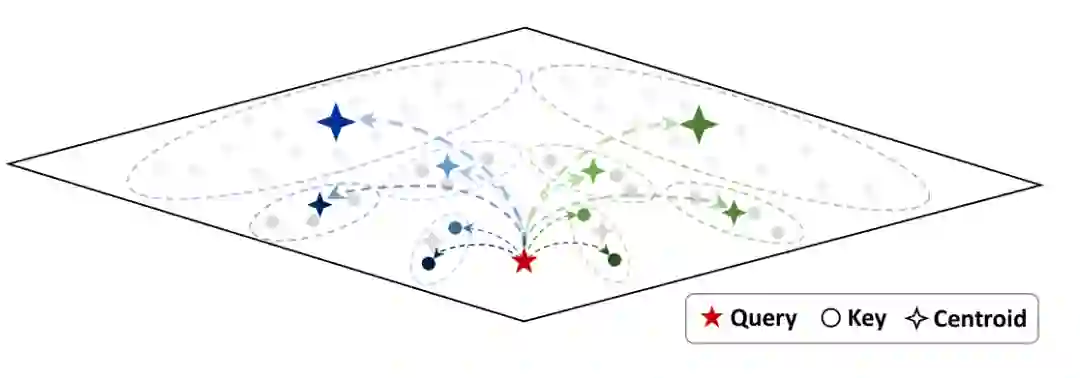
这种设计试图解决一个微妙矛盾:如果只保留少数 token,可能丢失全局上下文;如果保留全部 token,内存带宽和运行时成本又过高。Multipole Attention 的折中是,对局部重要信息精确处理,对远处信息以簇级代表近似处理。这样模型仍能利用全序列中的背景信息,但不必为每个 token 都付出同等精确注意力成本。 论文还讨论了系统实现,包括稀疏 FlashDecoding、centroid 查找、centroid 替换和快速簇更新等模块。在 Qwen3-8B 上的 A6000 GPU 实验中,作者展示了在不同 batch size 下的注意力运行时加速;当稀疏比例提高时,注意力延迟相对 baseline 明显下降。
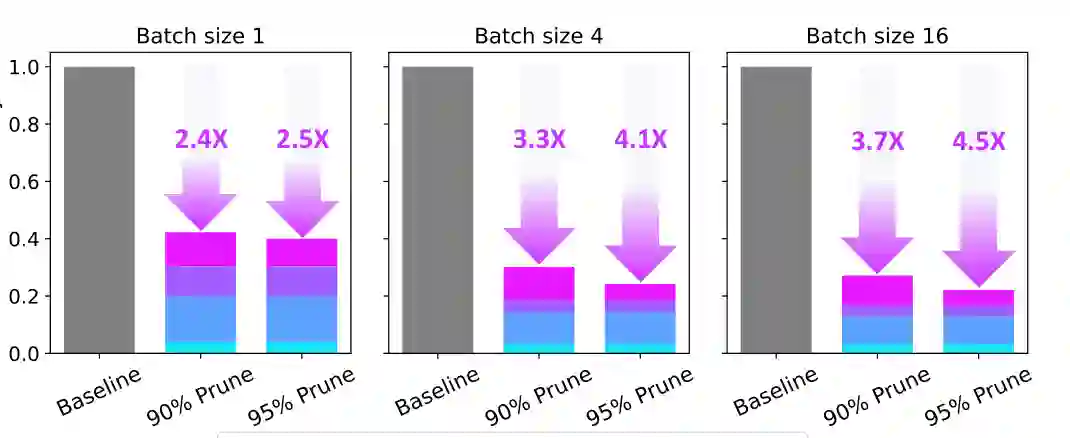
对推理型 LLM 来说,这一点很关键。长链思考会持续生成新 token,历史缓存也会越来越长。如果每一步都对完整历史做标准注意力,成本会随生成过程不断累积。Multipole Attention 把“历史越长越贵”的问题转化为“重要部分精确、其余部分近似”,更适合长输出和推理密集型任务。
七、总结与未来方向
整篇博士论文可以概括为一句话:LLM 推理的内存效率,必须从算法、数值表示和系统实现三个层次共同优化。论文先证明自回归解码的核心瓶颈来自内存带宽与缓存访问,再分别提出四类对应方案。 第一,SqueezeLLM 压缩模型权重,降低短上下文和权重主导场景中的显存与带宽压力。第二,KVQuant 压缩长上下文中的 KV cache activation,使更长上下文和更高并发成为可能。第三,Squeezed Attention 对共享固定上下文建立层级索引,只加载当前 query 需要的 token。第四,Multipole Attention 在复杂推理中用精确注意力和聚类近似结合,减少长生成过程中的注意力运行时。 这套研究路线也提示了未来 LLM 系统的几个方向。首先,内存层次结构会成为模型服务设计的中心问题,显存容量、带宽、片上缓存和多 GPU 互联都需要被算法显式感知。其次,量化不应只追求更低 bit,而要围绕敏感性、离群值、动态 activation 和 kernel 友好格式设计。再次,长上下文不能只靠扩大窗口,还需要检索、聚类、稀疏化和近似注意力共同降低每步访问成本。 更重要的是,推理工作负载正在变化。过去的 benchmark 更多关注短问答和单轮生成;现在的 agent、代码助手、研究助手和长链推理任务,会让模型长时间保持上下文并持续生成。这样的系统中,真正昂贵的不只是“模型有多大”,而是“每生成一个 token 需要搬动多少数据”。这也是这篇博士论文最值得关注的地方:它把大模型推理从单个算法问题,重新放回到内存墙、服务成本和系统可扩展性的框架中理解。
论文解读 | 从预训练到后训练:理解大模型推理能力如何形成
导读
强化学习后训练已经成为提升大语言模型复杂推理能力的关键环节。无论是数学、代码还是多步决策任务,当前主流路线往往是先做大规模预训练,再通过监督微调和带可验证奖励的 RL 进一步激发模型能力。但一个基础问题仍然没有被充分回答:预训练和 RL 到底如何相互作用? 这篇论文《Understanding Reasoning from Pretraining to Post-Training》正是围绕这一问题展开。作者不直接在自然语言大模型上做昂贵且难以控制的全流程实验,而是选择国际象棋作为可控推理试验场:预训练阶段让模型学习人类棋局轨迹,SFT 阶段使用合成推理轨迹,RL 阶段在有明确标准答案的棋题环境中用可验证奖励训练。通过这种方式,论文系统扫描模型规模、预训练 token 数和 RL 计算量,建立了一个连接预训练与 RL 后训练的 scaling law。 论文的核心结论可以概括为三点。第一,预训练损失能够预测给定 RL 计算量下的最终性能,预训练越充分,RL 后训练的起点和收益通常越好。第二,RL 的学习斜率与预训练 token 数近似线性相关,也就是说更长预训练不仅提高初始能力,还能让 RL 学得更快。第三,RL 并不只是简单“锐化”SFT 已经偏好的答案:在简单棋题上,它主要放大已有正确动作;在困难棋题上,它可以从尾部概率中挖出原本几乎缺席的正确动作,但也可能同时强化错误模式。
论文信息
论文标题:Understanding Reasoning from Pretraining to Post-Training 作者:Jingyan Shen、Ang Li、Salman Rahman、Yifan Sun、Micah Goldblum、Matus Telgarsky、Pavel Izmailov 机构:New York University、Modal Labs、University of California, Los Angeles、University of Illinois Urbana-Champaign、Columbia University 论文链接:https://arxiv.org/pdf/2607.16097 代码与模型:https://github.com/pavelslab-nyu/pre2post-chess ,https://huggingface.co/pavelslab-nyu/pre2post-chess
一、为什么要用国际象棋研究推理后训练
直接研究自然语言 LLM 的预训练到 RL 后训练过程非常困难。原因有三点。 第一,预训练语料巨大且不可控。一个语言模型在什么数据上学到了什么能力,往往很难分清。第二,系统扫描预训练计算量、模型规模和 RL 计算量的成本极高。第三,自然语言推理通常只有最终答案是否正确,缺少每一步策略动作的细粒度可验证信号。 国际象棋提供了一个折中方案。它有明确规则、紧凑动作空间、丰富人类棋局数据,也有可验证的战术题环境。更重要的是,每一步棋都可以作为一个“推理动作”被检查,模型的策略分布、候选搜索树和错误模式都能被精确分析。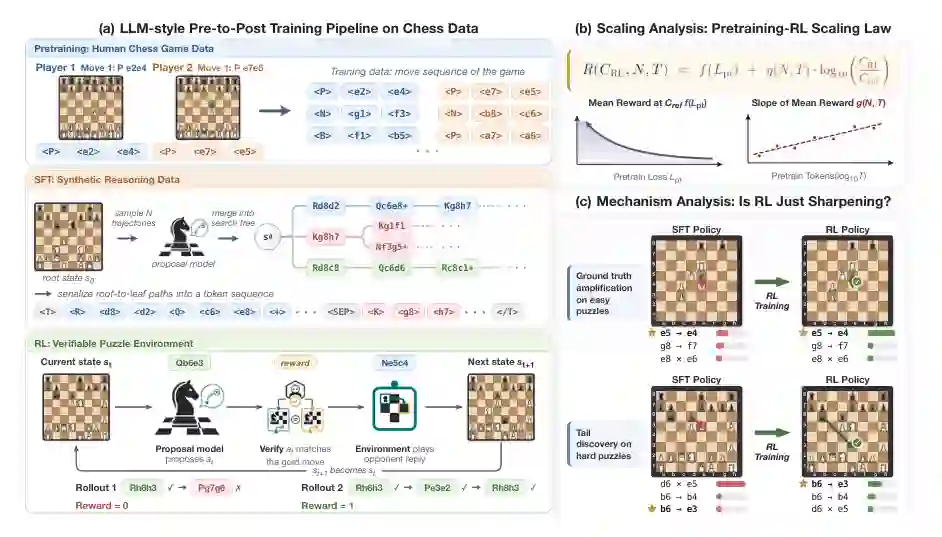
二、联合预训练-RL scaling law:预算该怎么分
论文首先研究固定总计算量下,预训练和 RL 后训练之间的预算分配问题。直觉上,预训练越多,模型初始策略越好,但留给 RL 的计算量越少;预训练越少,RL 计算量更多,但初始策略可能太弱。怎样分配才最优? 作者训练了从 5M 到 1B 参数的一组模型,并系统扫描 36 组 pretraining-RL 配置。评估指标包括 pass@1 和 pass@k,横轴则考虑总计算量、预训练计算量和 RL 计算量。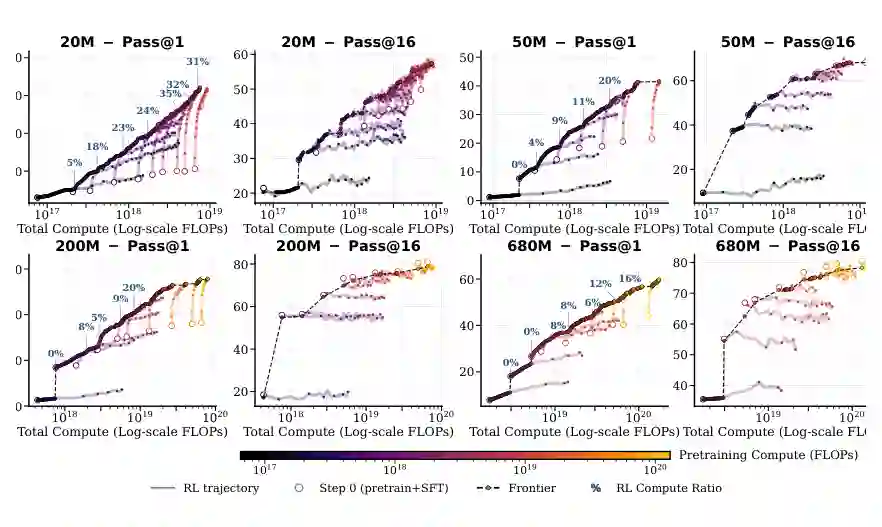
三、预训练性质可以预测 RL 的学习行为
论文最重要的发现之一是,预训练质量不仅影响 RL 的起点,也影响 RL 的斜率。 具体来说,在固定参考 RL 计算量下,预训练验证损失越低,post-RL reward 越高;并且随着参考 RL 计算量变大,这种关系更稳定。与此同时,RL reward curve 的局部斜率与预训练 token 数呈明显正相关。换句话说,训练得更久的 pretrained prior,不只是初始更强,还更容易被 RL 继续提升。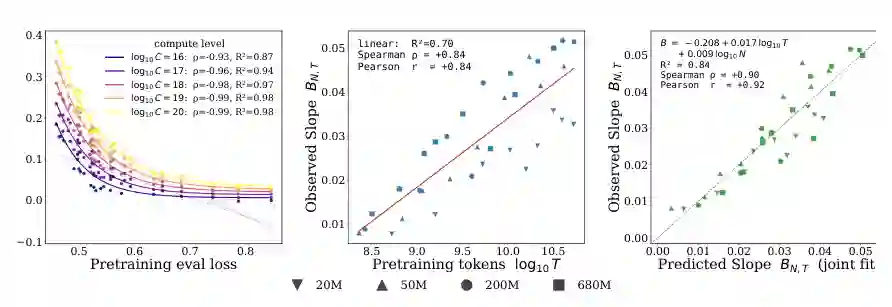
四、计算最优前沿:RL 比例会随预算增大而增加
将联合 scaling law 与 Chinchilla 风格的预训练损失预测结合后,作者可以模拟不同模型规模、不同预训练 token 数、不同 RL 计算量下的训练 recipe,而不必实际训练所有配置。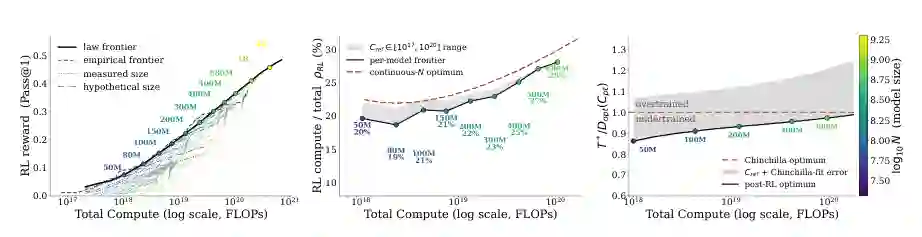
五、RL 到底改变了什么:锐化、发现与错误放大
关于 RL 后训练,已有研究存在不同观点。一种观点认为 RL 主要是 sharpening:把模型本来就会的推理模式变得更偏好、更稳定。另一种观点认为 RL 能组合或发现新能力,产生超出 base model 偏好的行为。 这篇论文利用棋题环境给出更细粒度的答案:两者都可能发生,而且取决于问题难度。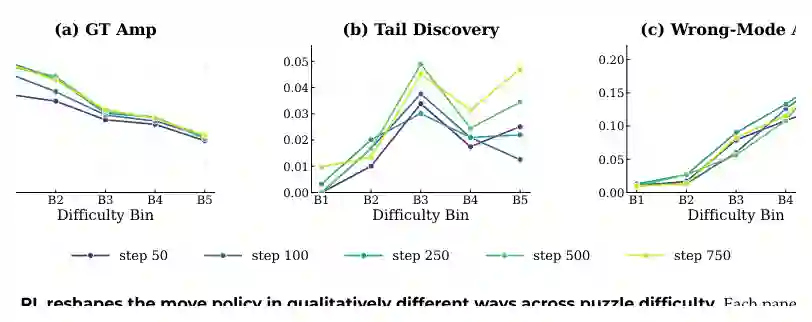
六、推理轨迹如何演化:搜索更宽,但更深仍困难
论文还分析了结构化 reasoning trace 在 RL 训练中的变化。作者将模型生成的 CoT 式棋步轨迹解析成搜索树,从三个角度衡量:搜索形状、走法质量和搜索行为。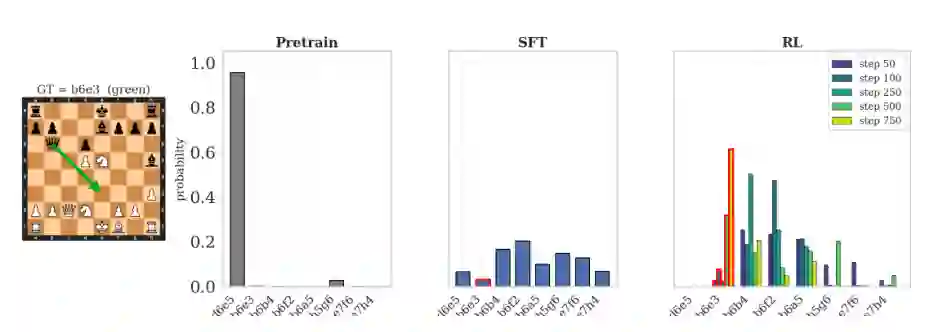
七、从棋类迁移到数学:模式是否仍存在
为了检验棋类结果是否只是领域特例,论文还做了一个数学领域的定性迁移实验。作者使用 1B 参数 OLMo-2 模型,在数学领域文本上训练不同预训练 token 数的 checkpoint,从 10B 到 200B tokens;随后进行数学 CoT SFT 和 RL,并在 GSM8K、MATH500 等任务上评估。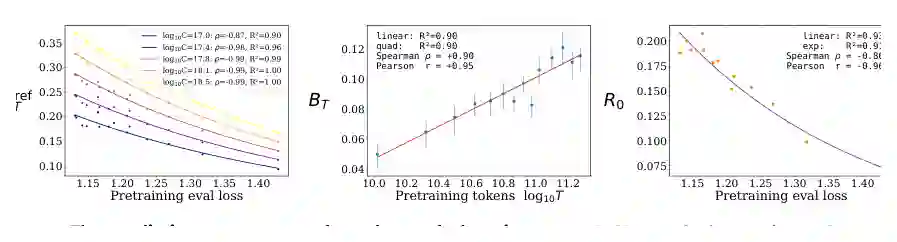
八、这篇论文的意义与局限
这篇论文的贡献在于,把“预训练与 RL 的接口”从经验问题推进到可量化问题。以往我们经常分别研究 pretraining scaling law 和 RL scaling recipe,但实际训练中二者是连续管线。一个模型在 RL 阶段能学到什么,深受预训练 prior 的影响。 论文提供了三个层面的价值。 第一,方法层面,它提出了一个可控 chess testbed,让研究者能低成本扫描预训练、SFT、RL 三阶段,并观察策略分布和推理轨迹的细粒度变化。 第二,规律层面,它建立了联合 pretraining-RL scaling law,说明预训练损失和预训练 token 数可以预测 post-RL 性能和 RL 学习斜率。 第三,机制层面,它区分了 RL 的不同作用:在简单问题上放大已有正确偏好,在困难问题上发现尾部正确动作,同时也可能强化错误模式。 当然,论文也有明显局限。国际象棋虽然是很好的可控环境,但与自然语言推理仍有差异:动作空间更小,奖励更明确,状态转移更规则。数学迁移实验规模也相对有限,更像是定性验证而不是最终结论。此外,论文的 scaling law 是局部拟合,适用于所研究的模型规模和计算范围,不应直接当作通用训练配方。 尽管如此,它提出的问题非常重要:未来做 RL 后训练,不能只优化 RL 算法本身,还要问预训练阶段为 RL 留下了怎样的候选空间、表示结构和可探索能力。真正的推理能力,可能正是在预训练 prior 与后训练经验之间共同形成的。
参考资料
Jingyan Shen, Ang Li, Salman Rahman, Yifan Sun, Micah Goldblum, Matus Telgarsky, Pavel Izmailov. Understanding Reasoning from Pretraining to Post-Training. arXiv:2607.16097, 2026. 论文 PDF:https://arxiv.org/pdf/2607.16097
本文聚焦无人系统联合架构(JAUS)。JAUS是国际自动机工程师学会(SAE)AS-4无人系统指导委员会制定的国际标准。本文将阐述该标准的基本概念及其在实现异构无人系统互操作性方面的适用性,同时介绍相关标准文档与JAUS服务集,最后剖析JAUS标准的优势与局限。
无人系统联合架构(JAUS)是一项国际标准,旨在确立一套通用的消息格式与通信协议,以支持无人飞行器与地面控制站内部及相互间的互操作。该架构最初由美国国防部(DoD)授权制定,旨在为无人地面机器人领域提供开放式架构。此后,JAUS逐步转化为国际行业标准——现归属拥有机器人技术积淀的标准制定机构国际自动机工程师学会(SAE),该学会于2004年8月成立航空航天标准无人系统指导委员会(AS-4)。界定JAUS的全部标准文档均可直接从SAE官网购买。其初衷在于定义开放式通信标准,以支持军用机器人系统的互操作。众多项目与厂商已参与JAUS实践,并成功验证了其在无人系统中的适用性,典型案例包括2004年、2005年DARPA大挑战赛及2007年DARPA城市挑战赛中的多款机器人平台。
JAUS概览
JAUS的核心目标在于规范网络环境下无人系统的通信与协同运作机制。JAUS系统由接入公共数据网络的若干子系统构成。子系统通常对应系统网络中的物理实体,例如无人飞行器或操作员控制单元(见图1)。
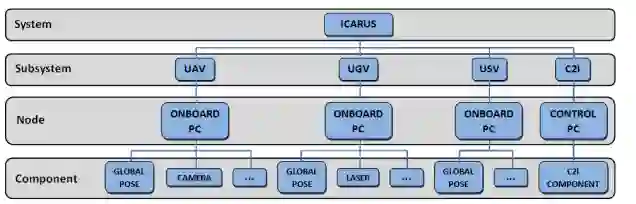
JAUS网络进一步划分为层级化结构。子系统下辖节点,节点代表系统中的物理计算端点,例如子系统内部的计算机或微控制器。节点可承载一个或多个组件,组件通常为运行于节点上的应用程序或线程。组件最终由一项或多项服务构成。因此,系统架构呈现如下层级关系:
服务旨在为系统提供特定实用功能。面向服务架构(SOA)赋能无人系统的分布式指挥与控制。JAUS采用的SOA方法致力于规范化系统组件间的消息格式与协议交互。该方法由JAUS服务接口定义语言(JSIDL)予以标准化;这是一种基于XML的语言,为界定JAUS服务提供基础结构与语法规范。所有经JAUS标准化的服务均须采用合规的JSIDL语法进行描述。

此前,美空军主要依托安全部队人员开展反无人机威胁训练,如今这一模式正随其新型“反无人机行动单元”的组建而发生转变。[美国空军高级飞行员阿曼达·杰特摄]
美空军已组建首批快速部署部队,旨在保护太平洋地区或其他潜在热点区域的空军基地免受空袭。
此类要点防御分队由约20名具备航空与战斗管理背景的士兵组成,既可保卫美国本土常设基地,亦专门针对敏捷作战运用中可能启用的偏远机场实施反无人机防护。
“这是一种远征能力,因此我们必须确保其轻便精简,”美空军负责作战的副参谋长办公室未来行动主任迈克尔·希伊表示。
美空军正处于完善此类反无人机行动单元的初期阶段,最终将由一个月前宣布设立的、专司基地防御的新兵种人员构成,以应对不断演变的无人机威胁。低成本四旋翼无人机及伊朗“沙赫德”等喷气动力无人机的扩散,显著加剧了空军基地及其他军事设施面临的袭击风险。
在与伊朗冲突中阵亡的16名美军人员中,至少9人死于伊朗对中东地区空军基地的无人机与导弹袭击。希伊承认美国中央司令部责任区的伊朗无人机威胁,但同时指出,去年成立的五角大楼第401号联合跨部门特遣队正为该区域部署的美军提供反无人机支援。
希伊表示,目前正着手将新型空军基地防御分队部署至从本土到太平洋的潜在热点地区。此前,核基地与机场等高安保设施内的安全部队人员构成了反无人机训练力量的主体。但希伊强调,空军正着力选拔具备指挥控制经验的官兵编入这些新部队。
“我们重点关注作战一线、具备航空思维的士兵,例如入伍飞行员与入伍空中战斗管理员,”他使用了一个描述空军人员持续认知自身在维系空中作战力量中角色的术语。
官兵需在位于俄克拉荷马州锡尔堡的联合反无人机系统大学接受为期约三周的培训,学习操作美军反无人机技术及防御敌方无人机袭击的战术。
希伊称,当前美空军正与第401号联合跨部门特遣队合作采购商用反无人机系统,但该军种针对此类威胁的正式列装项目仍是“小型无人机防御系统”(SUADS)。他介绍,SUADS本质上是一种能识别并追踪各类尺寸敌无人机的探测系统。
根据空军预算文件,国会在2026财年为SUADS拨付了5180万美元的采购资金。该系统现有两种型号:一种适用于固定空军基地,另一种可装载于飞机托盘实现快速部署。例如,要点防御分队将携带机动型SUADS变体,“作为兵力包的前出部分支援敏捷作战运用行动,”希伊说。
“因此,当各分队执行敏捷作战运用任务时,可配备集传感器、效应器及指挥控制功能于一体的快速部署型SUADS系统,”希伊表示,“我们能让这些官兵携此装备于次日或更短时间内前出部署。”
未来基地防御专业代码
美空军基地防御在技术层面属陆军职能,却长期为空军所关切。近期无人机战争的兴起,促使高层领导认识到亟需组建专业部队并配备专项训练以应对威胁。
空军部长特洛伊·E·梅因克在5月20日的国会证词中强调,空军人员“肩负保卫我空军基地及驻防部队之责,无论其身处何地。”
今年6月,空军领导层在俄亥俄州赖特-帕特森空军基地举行的半年一度“科罗娜”会议上,确立了设立专注于基地防御的专用空军专业代码(AFSC)的必要性。
希伊表示,空军“尚处于探索开发该专业代码的极早期阶段”,故细节仍较匮乏。
“我们将如何征召人员……并开展初始资格培训?此外,他们的职业发展路径如何?我们必须确保为其规划清晰的职业生涯,”希伊补充道,绝不能出现“专业代码仅限晋升至下士(E-4)即触顶”的情况。
当前,空军正与锡尔堡反无人机系统大学合作开发基地防御人员的专业技术培训体系。“针对即将进入该职业领域的官兵,其初始资格培训的课程标准正在制定中,”希伊说。
参考来源:空天部队杂志,https://www.airandspaceforces.com/early-look-air-force-new-counter-drone-units/









