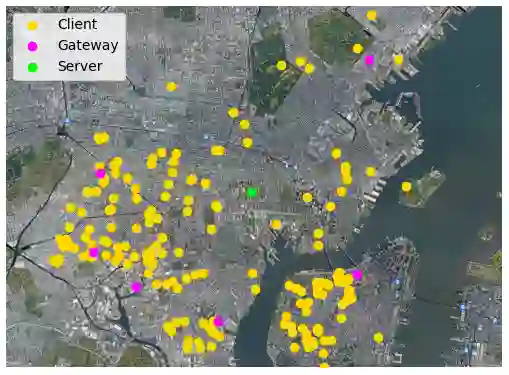
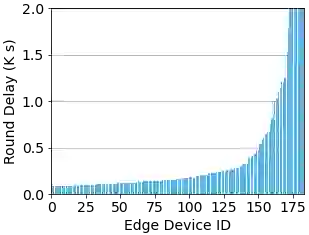
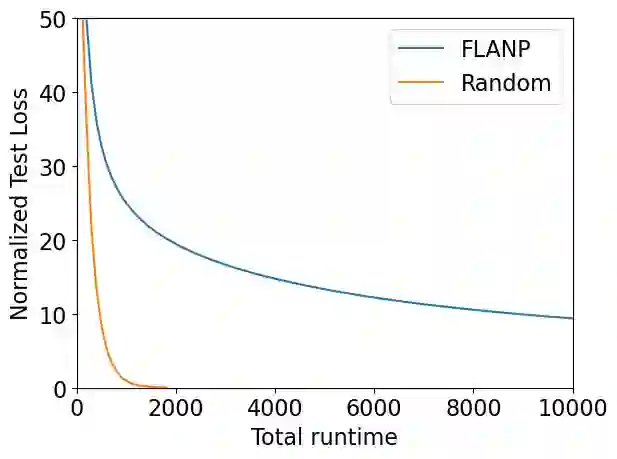
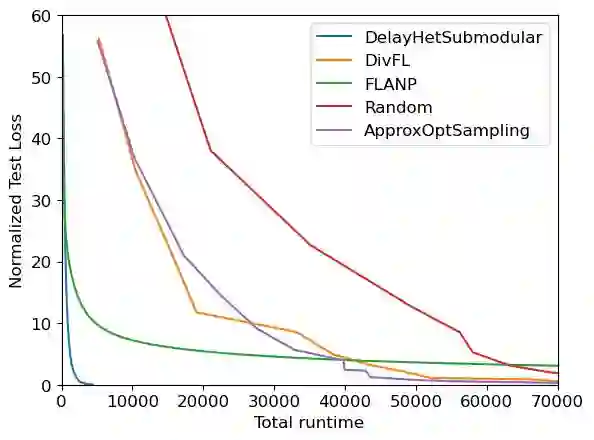
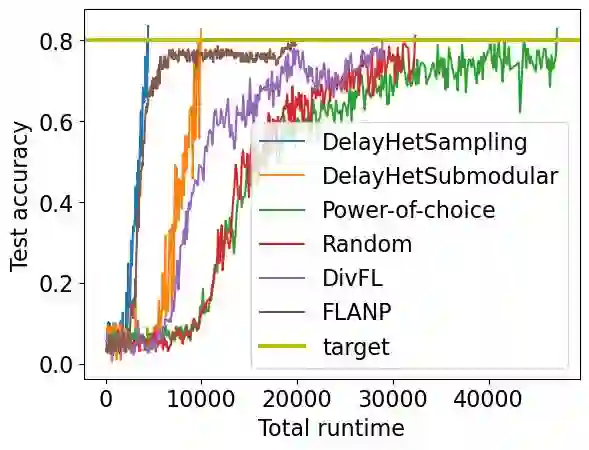
Federated learning (FL) is a distributed machine learning paradigm where multiple clients conduct local training based on their private data, then the updated models are sent to a central server for global aggregation. The practical convergence of FL is challenged by multiple factors, with the primary hurdle being the heterogeneity among clients. This heterogeneity manifests as data heterogeneity concerning local data distribution and latency heterogeneity during model transmission to the server. While prior research has introduced various efficient client selection methods to alleviate the negative impacts of either of these heterogeneities individually, efficient methods to handle real-world settings where both these heterogeneities exist simultaneously do not exist. In this paper, we propose two novel theoretically optimal client selection schemes that can handle both these heterogeneities. Our methods involve solving simple optimization problems every round obtained by minimizing the theoretical runtime to convergence. Empirical evaluations on 9 datasets with non-iid data distributions, 2 practical delay distributions, and non-convex neural network models demonstrate that our algorithms are at least competitive to and at most 20 times better than best existing baselines.
翻译:联邦学习是一种分布式机器学习范式,多个客户端基于其私有数据进行本地训练,然后将更新后的模型发送到中央服务器进行全局聚合。联邦学习的实际收敛受到多种因素的挑战,主要障碍在于客户端之间的异构性。这种异构性表现为本地数据分布方面的数据异构性,以及模型传输到服务器过程中的延迟异构性。尽管先前的研究已引入各种高效的客户端选择方法来单独缓解其中一种异构性的负面影响,但尚不存在能够同时处理这两种异构性共存的实际场景的高效方法。本文提出了两种新颖的理论最优客户端选择方案,能够同时处理这两种异构性。我们的方法通过最小化理论收敛时间来获得每轮需解决的简单优化问题。在9个非独立同分布数据集、2种实际延迟分布以及非凸神经网络模型上的实证评估表明,我们的算法至少与现有最佳基线方法相当,最多可优于现有最佳基线方法20倍。