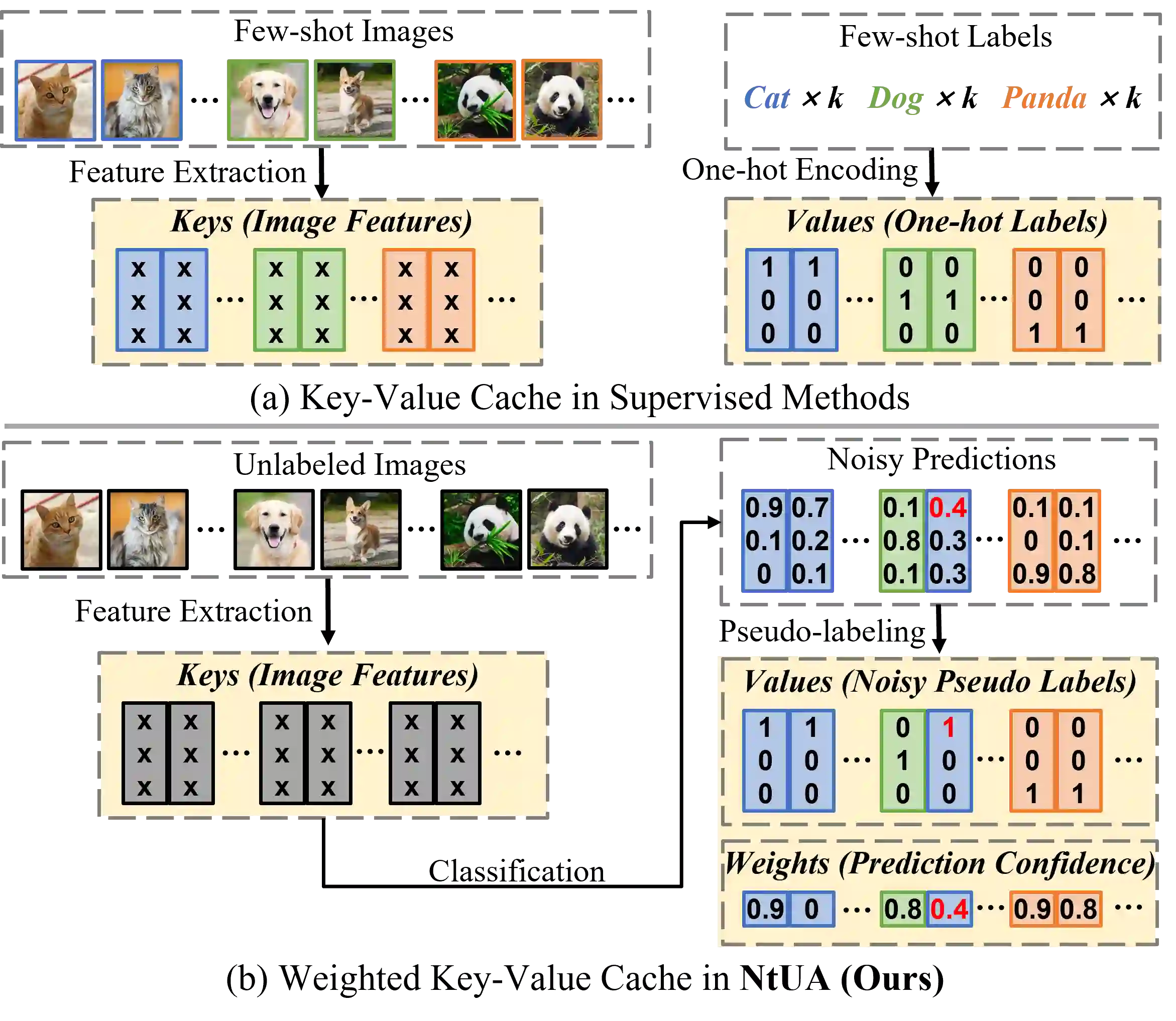
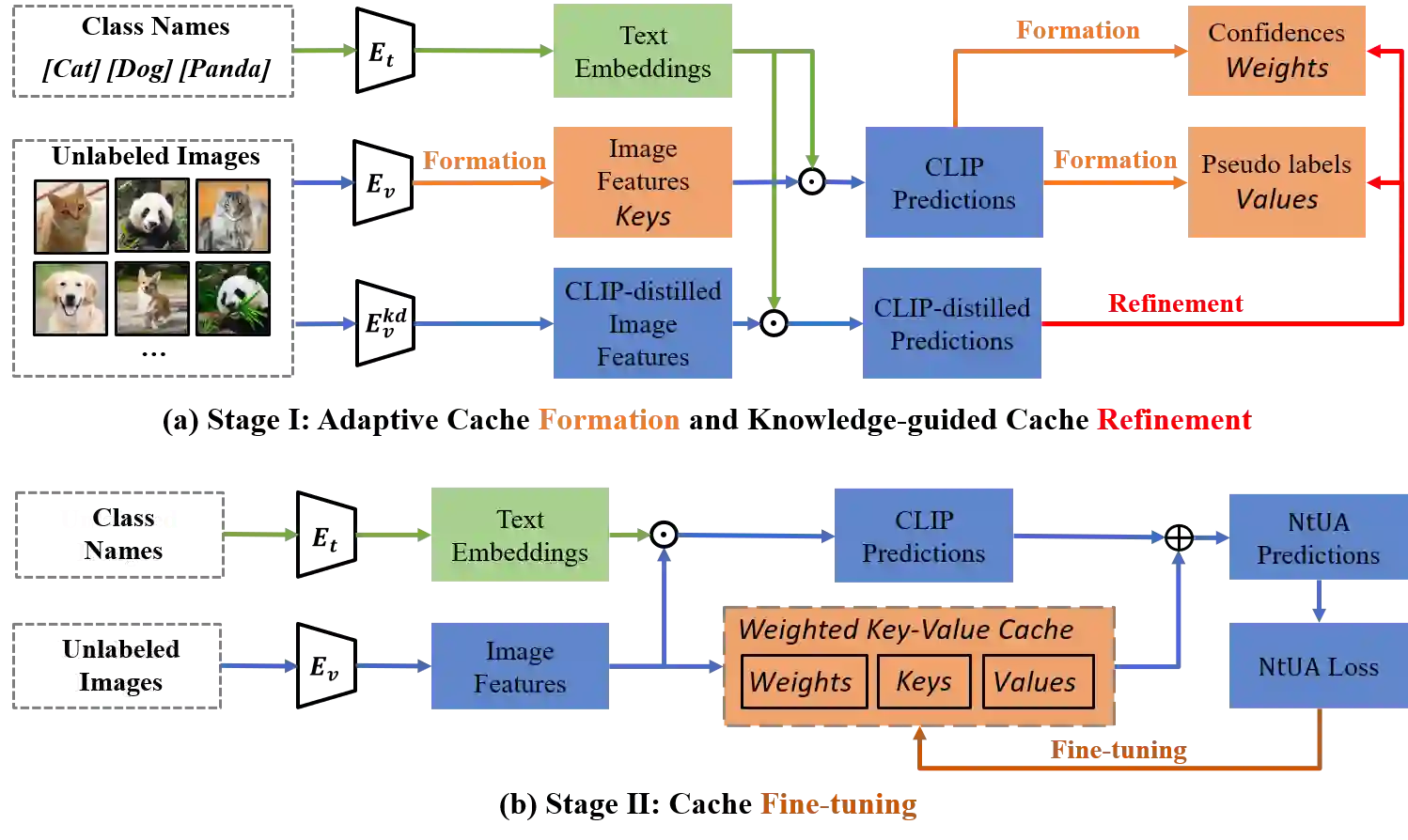
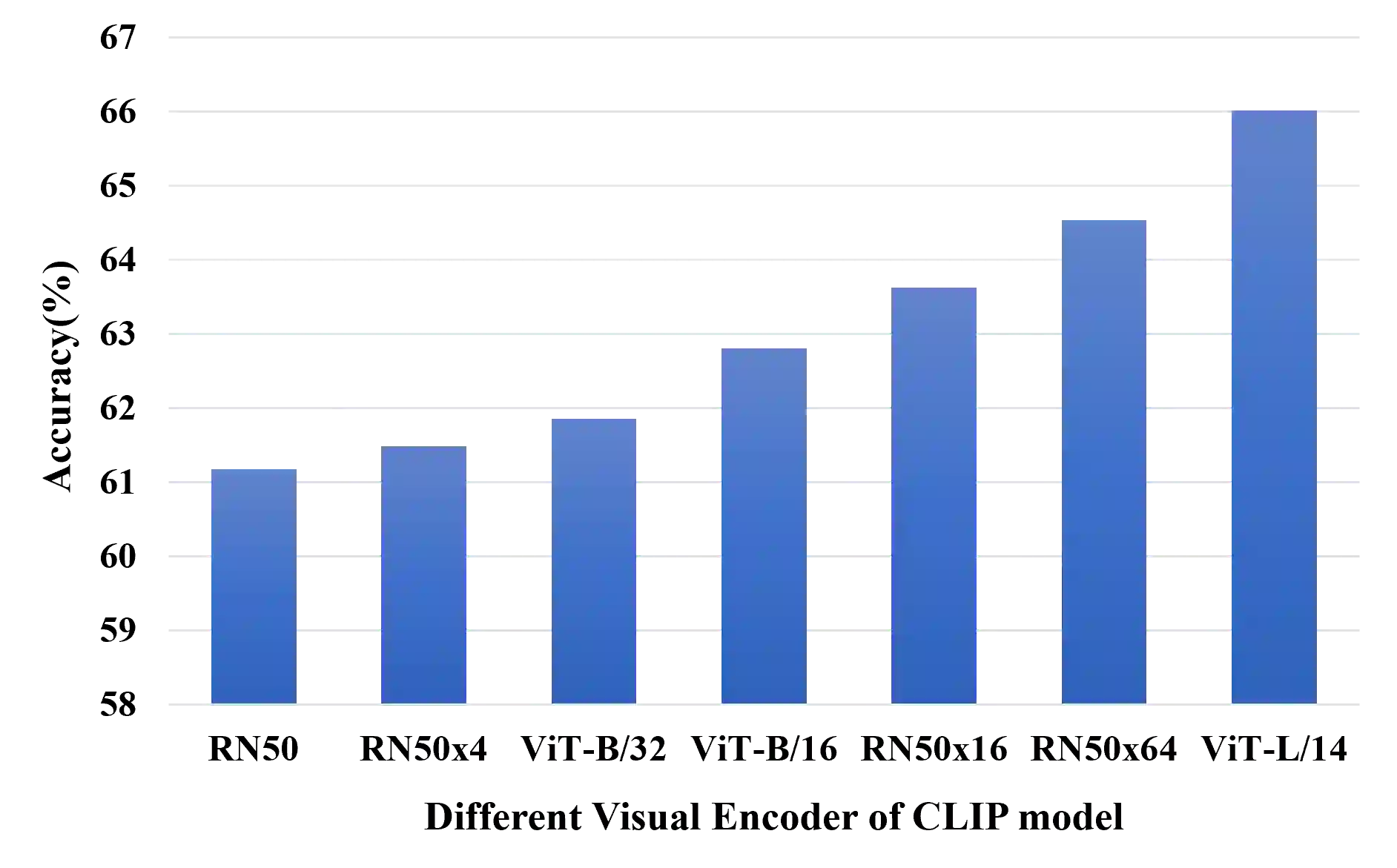
Recent advances in large-scale vision-language models have achieved very impressive performance in various zero-shot image classification tasks. While prior studies have demonstrated significant improvements by introducing few-shot labelled target samples, they still require labelling of target samples, which greatly degrades their scalability while handling various visual recognition tasks. We design NtUA, a Noise-tolerant Unsupervised Adapter that allows learning superior target models with few-shot unlabelled target samples. NtUA works as a key-value cache that formulates visual features and predicted pseudo-labels of the few-shot unlabelled target samples as key-value pairs. It consists of two complementary designs. The first is adaptive cache formation that combats pseudo-label noises by weighting the key-value pairs according to their prediction confidence. The second is pseudo-label rectification, which corrects both pair values (i.e., pseudo-labels) and cache weights by leveraging knowledge distillation from large-scale vision language models. Extensive experiments show that NtUA achieves superior performance consistently across multiple widely adopted benchmarks.
翻译:近期大规模视觉语言模型在各种零样本图像分类任务中取得了非常令人瞩目的性能。尽管先前研究通过引入少量带标注的目标样本实现了显著改进,但这种方法仍需为目标样本进行标注,在处理各种视觉识别任务时严重限制了其可扩展性。我们设计了NtUA——一种抗噪无监督适配器,能够利用少量无标注目标样本学习优质的目标模型。NtUA作为一种键值缓存机制运行,将少量无标注目标样本的视觉特征和预测伪标签构建为键值对。它包含两种互补设计:一是自适应缓存构建,通过根据预测置信度对键值对进行加权来抑制伪标签噪声;二是伪标签修正,借助大规模视觉语言模型的知识蒸馏,同时修正键值对中的值(即伪标签)和缓存权重。大量实验表明,NtUA在多个广泛采用的基准测试中持续展现出优越性能。