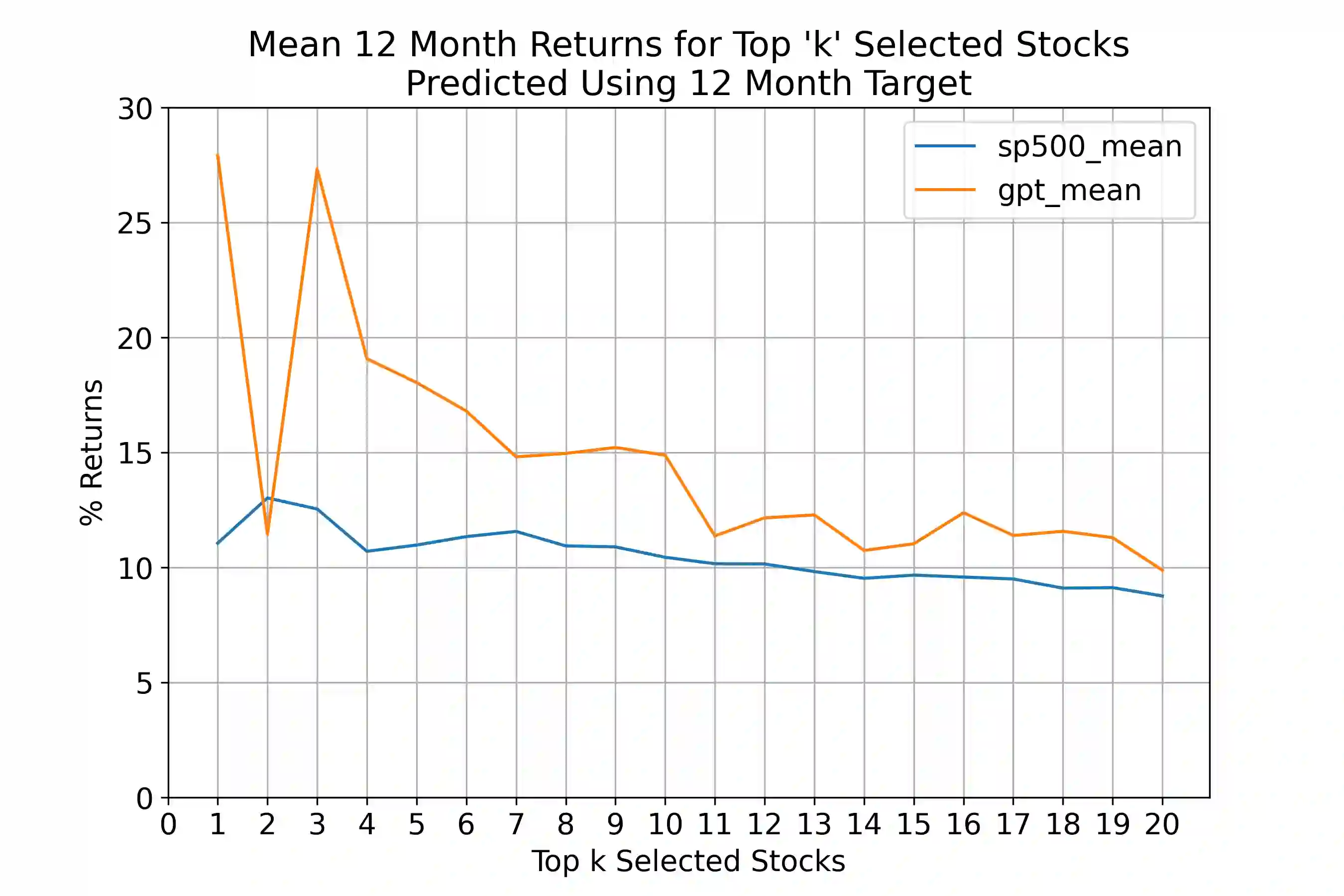
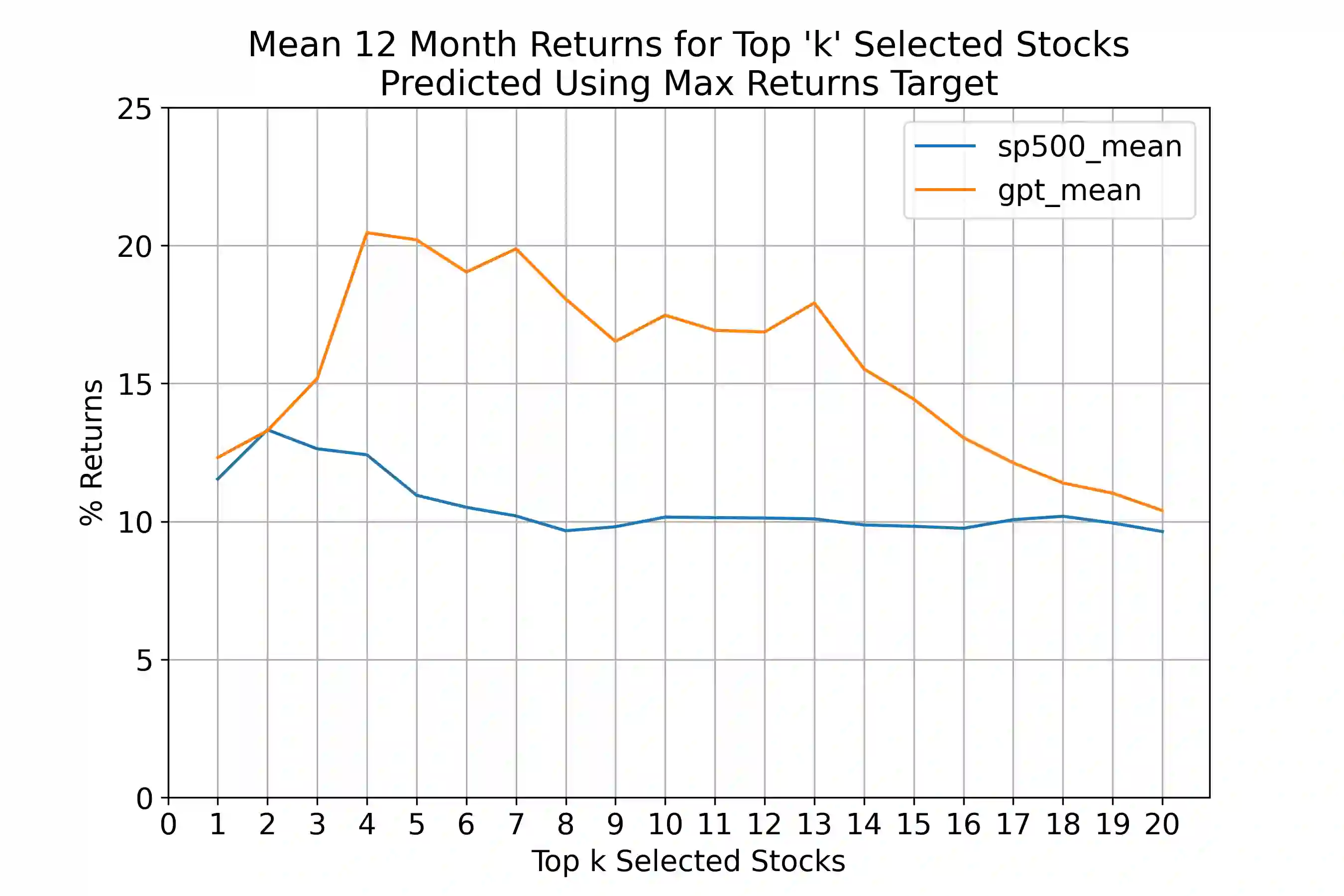
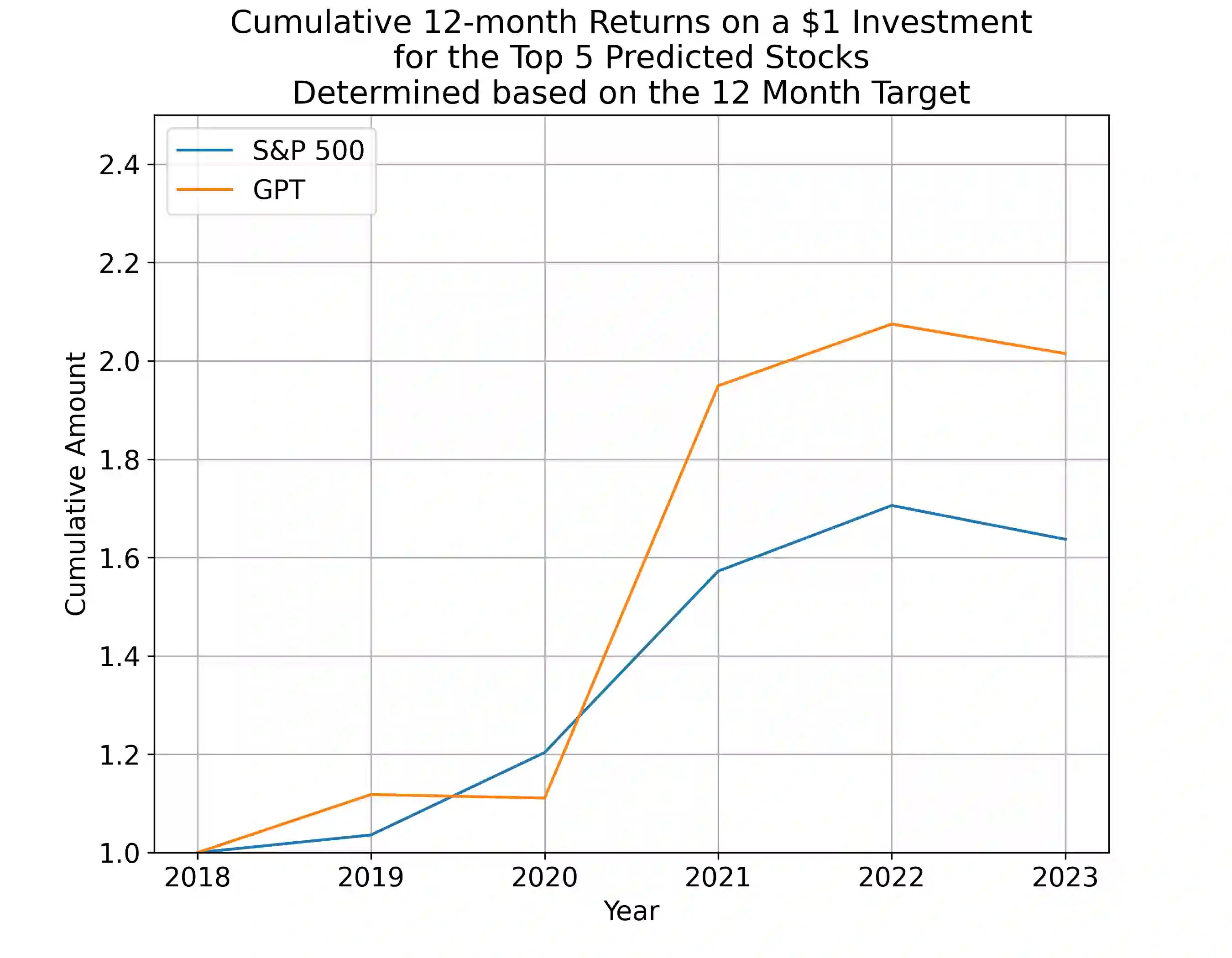
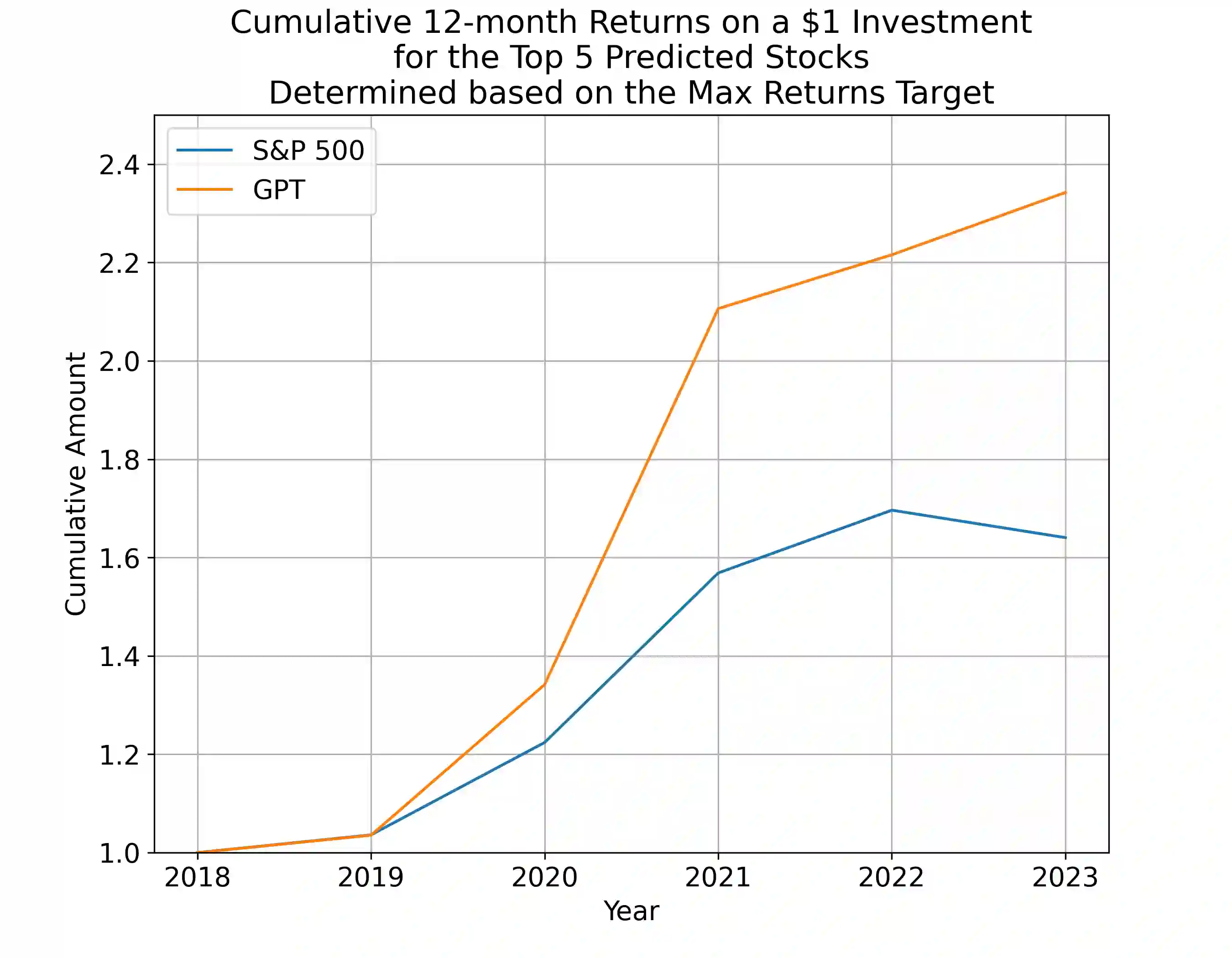
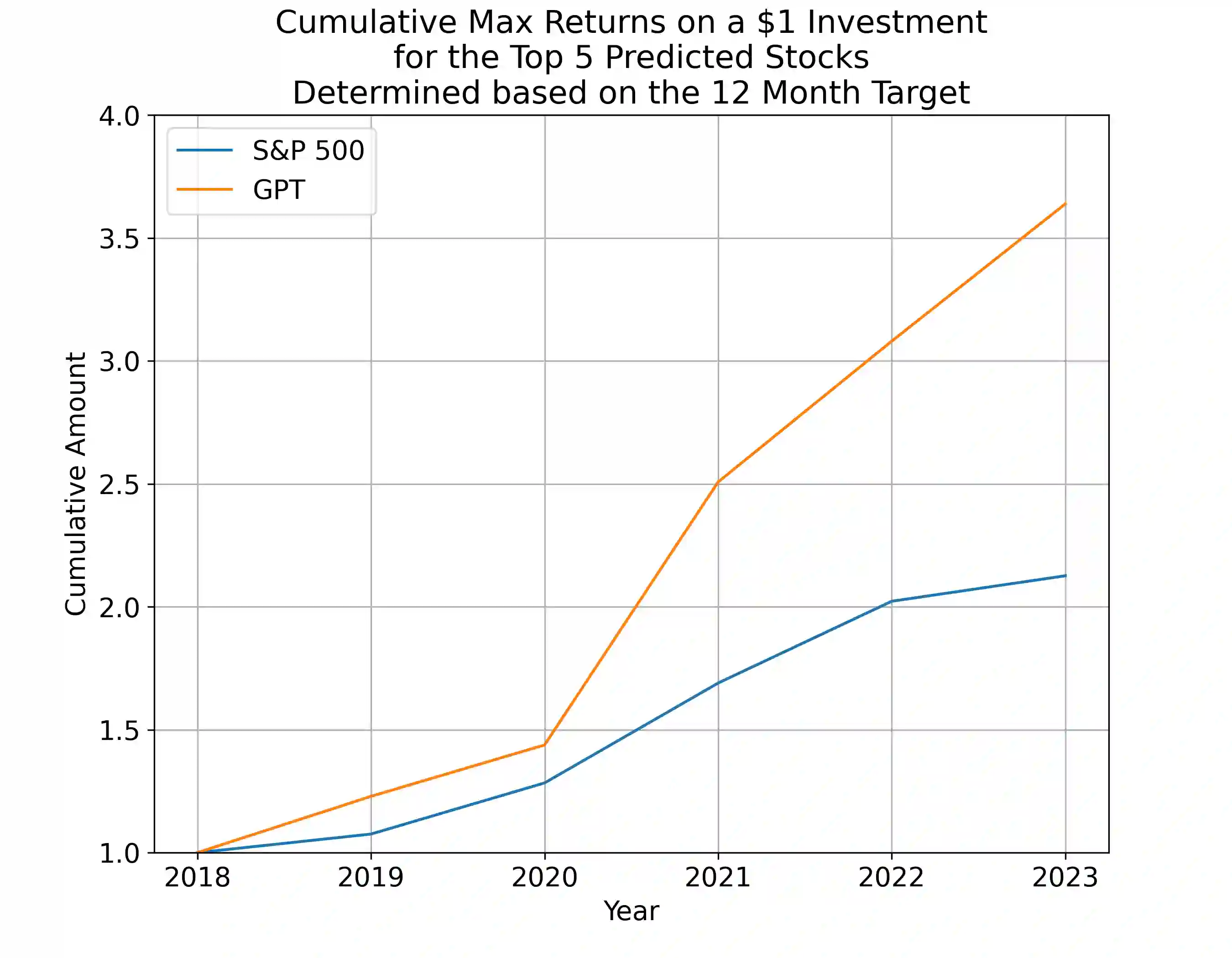
Annual Reports of publicly listed companies contain vital information about their financial health which can help assess the potential impact on Stock price of the firm. These reports are comprehensive in nature, going up to, and sometimes exceeding, 100 pages. Analysing these reports is cumbersome even for a single firm, let alone the whole universe of firms that exist. Over the years, financial experts have become proficient in extracting valuable information from these documents relatively quickly. However, this requires years of practice and experience. This paper aims to simplify the process of assessing Annual Reports of all the firms by leveraging the capabilities of Large Language Models (LLMs). The insights generated by the LLM are compiled in a Quant styled dataset and augmented by historical stock price data. A Machine Learning model is then trained with LLM outputs as features. The walkforward test results show promising outperformance wrt S&P500 returns. This paper intends to provide a framework for future work in this direction. To facilitate this, the code has been released as open source.
翻译:上市公司年报包含有关其财务状况的重要信息,有助于评估这些信息对公司股价的潜在影响。这些报告内容全面,篇幅常达甚至超过100页。即便分析单个公司的年报已颇为繁琐,更遑论对所有上市公司进行全局分析。多年来,金融专家逐渐掌握了从这些文件中相对快速提取有价值信息的能力,但这需要多年的实践与经验积累。本文旨在利用大语言模型(LLMs)的能力,简化对所有上市公司年报的评估流程。LLM生成的见解被整理为量化风格的数据集,并通过历史股价数据进行增强。随后,以LLM输出作为特征训练机器学习模型。滚动测试结果表明,该模型在标普500指数收益上展现出显著的超额表现。本文旨在为未来相关研究提供框架,并已开源代码以促进该方向的发展。