
ICML 2026 | VOTP:用视频基础模型与最优传输,让离线偏好强化学习只需少量反馈
偏好强化学习的吸引力在于:人不必手写复杂奖励函数,只要比较两段行为视频,告诉智能体“哪一个更好”。但它的现实瓶颈也很明显:要学到可靠奖励模型,通常需要大量人工偏好标注。对于机器人和连续控制任务,收集成百上千个视频比较既昂贵,也很难长期维护。 ICML 2026 论文《Video-Based Optimal Transport for Feedback-Efficient Offline Preference-Based Reinforcement Learning》围绕这个问题提出 VOTP(Video-based Optimal Transport Preference)。它的核心思路是:既然人的偏好往往来自对行为视频的视觉判断,就不应只把少量标注视频当作孤立样本,而应借助视频基础模型的表征空间,把已标注行为与大量未标注行为对齐,再用最优传输传播偏好信号。 换句话说,VOTP 不是让大模型直接打分,也不是用当前不可靠的奖励模型自我扩增标签,而是在视频基础模型的潜空间里计算“哪些未标注行为片段与哪些已标注偏好片段相似”,再通过最优传输计划为未标注片段对生成伪偏好标签。这样,少量人工反馈可以撬动大量离线数据,进而训练更稳定的奖励函数。

1. 背景:奖励工程为什么仍然难
强化学习依赖奖励函数。只要奖励设计得好,智能体可以在 Atari、棋类、连续控制和机器人任务中取得很强表现。但真实任务的奖励经常很难写。比如让机械臂“把香蕉拿起来”,稀疏成功奖励太难学,密集奖励又要精心设计抓取、高度、接触、姿态等细节;稍有偏差,策略可能学到看似高分但并不符合人类意图的捷径。 偏好强化学习(Preference-based RL, PbRL)试图绕开手写奖励。人类教师只需比较两段轨迹视频,标注哪段更好,模型再根据这些比较学习奖励函数。这个范式更贴近人类反馈,也更适合那些“结果好坏容易判断、奖励细节难以编码”的任务。 但 PbRL 的标注成本很高。有效奖励模型需要覆盖足够多的状态和动作区域,否则很容易只在少量示例附近给出合理分数,一旦策略走到未覆盖区域就出现误判。已有工作常常需要数百到数千次偏好查询。对机器人任务来说,这意味着大量视频片段展示、人工比较、数据管理和重复训练,阻碍了 PbRL 在低反馈预算场景下落地。 VOTP 抓住了一个容易被忽视的事实:偏好标注本身通常是视频驱动的。人在比较轨迹时,看到的是对象位置、动作进展、失败模式和时序动态。既然如此,视频基础模型在大规模视频语料上学到的时空表征,可能提供一种低成本的“行为相似性”度量,用来帮助少量偏好向未标注数据传播。
2. 核心思想:在视频潜空间里传播偏好
VOTP 的输入包括两个部分。第一部分是少量已标注片段对,例如 10 对视频比较,每一对带有偏好标签。第二部分是离线数据集中大量未标注片段对,它们不需要额外人工标注,只需从已有轨迹中采样并渲染成短视频。 方法包含两个关键组件:
- 用视频基础模型把轨迹片段编码成潜向量。论文采用 S3D 作为主要视频编码器,它在 HowTo100M 等大规模视频数据上预训练,能够捕捉帧内空间结构和跨帧动作动态。
- 用最优传输在已标注片段集合与未标注片段集合之间建立软对齐。每个未标注片段不是硬匹配到一个最近邻,而是通过传输计划与多个已标注片段形成概率对应关系。
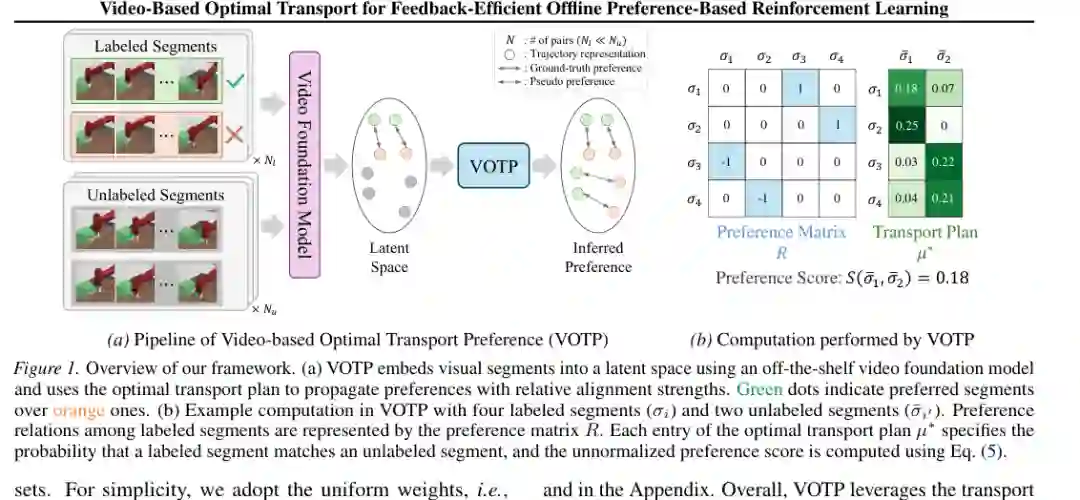
这种设计的关键在于“相对对齐”。假设已标注片段中,A 优于 B。对于一个未标注片段对 X 和 Y,如果最优传输显示 X 更像 A、Y 更像 B,那么 VOTP 就倾向于推断 X 优于 Y;如果对应关系反过来,则偏好也反转。论文把所有已标注偏好关系汇总成一个偏好矩阵,再结合最优传输计划计算未标注片段对的偏好分数。 这比简单最近邻更稳健。最近邻方法只看最像的样本,容易受偶然外观相似影响;均值聚类会丢失细粒度行为差异;相似度加权虽然更平滑,但没有显式利用“偏好对”的相对结构。VOTP 使用最优传输同时考虑多个片段之间的全局匹配关系,相当于在视觉行为空间中做更结构化的偏好传播。
3. 方法流程:从伪标签到奖励学习
在形式上,PbRL 通常先收集片段对及偏好标签,再用 Bradley-Terry 模型训练奖励函数。给定两段轨迹,奖励模型会比较两段轨迹累计奖励的相对大小,并通过交叉熵损失拟合人类偏好。训练好奖励函数后,离线数据中的状态动作对会被重新标注奖励,再交给离线强化学习算法训练策略。 VOTP 保留这一主流程,但把偏好数据集从“少量人工标注”扩展为“少量人工标注 + 大量高置信伪标注”。具体步骤如下: 首先,从离线数据中采样轨迹片段,并将每段轨迹渲染为短视频。每个视频片段经视频基础模型编码为潜向量。然后,VOTP 将已标注片段和待推断的未标注片段看作两个经验分布,用距离函数构造传输代价,并通过 Sinkhorn 算法求解熵正则化最优传输。论文使用 POT 工具箱实现这一计算,以兼顾效率和数值稳定性。 接着,方法根据传输计划和已标注偏好矩阵,为未标注片段对计算归一化偏好分数。若分数绝对值高于阈值,就生成明确偏好标签;若分数接近零,则可视为二者难以区分或同等偏好。这一阈值承担了质量控制作用:阈值越高,保留下来的伪标签越可信,但数量越少;阈值过低,则伪标签覆盖更广但噪声更大。 最后,人工标签和伪标签一起训练奖励模型。奖励模型再为离线 RL 数据重打奖励,论文采用 IQL 作为策略优化算法。值得注意的是,VOTP 并不绑定某个特定离线 RL 算法,它的贡献集中在奖励学习阶段。
4. 实验设置:低反馈预算下检验奖励学习
论文主要回答五个问题:VOTP 是否能在低标注场景提升反馈效率;每个组件是否必要;关键超参数如何影响性能;视频扰动下是否鲁棒;真实机器人任务上是否仍然有效。 实验覆盖两个模拟基准和真实机器人任务。模拟部分包括 D4RL locomotion 和 MetaWorld manipulation。D4RL 使用 Hopper、Walker2d 等连续控制任务,指标是归一化分数;MetaWorld 使用 Door Open、Drawer Open、Plate Slide、Sweep Into 等机械臂操作任务,指标是成功率。 标注预算非常低:主实验用 10 对已标注偏好作为初始监督。对于伪标注,D4RL 采样 1 万个未标注查询,MetaWorld 采样 5 万个未标注查询。为了公平比较,策略和奖励模型训练设置与 PbRL 基线保持一致,差异主要来自奖励学习方式。 基线包括两类。一类不显式学习奖励,如 IPL、CPL、DPPO;另一类显式学习奖励,如 P-IQL、SURF、LiRE、APPO、FTB。论文还加入 Oracle 作为上界式参考,即使用合成偏好标注未标注数据。
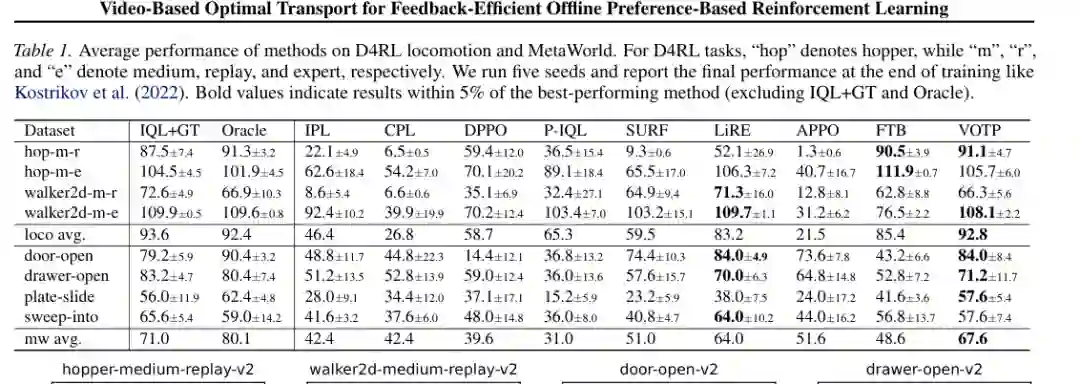
5. 主要结果:少量反馈也能学到有效奖励
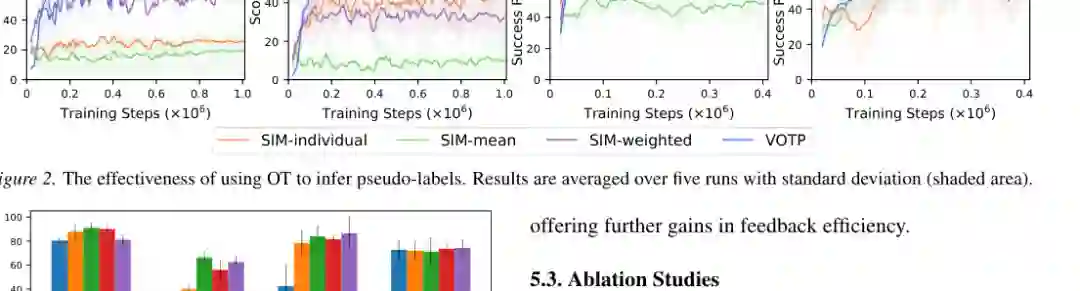
主结果显示,显式奖励建模在低数据场景下通常比直接偏好优化更稳健。没有奖励模型的 IPL、CPL、DPPO 在多个任务上表现不稳定;P-IQL 虽然学习奖励模型,但只有少量人工偏好,覆盖不足,因此在 MetaWorld 上平均成功率较低。 VOTP 的优势在于,它把大量未标注片段转化为可用偏好监督,缓解奖励模型的数据覆盖问题。在 D4RL 上,VOTP 的 locomotion 平均分达到 92.8,接近 IQL 使用真实奖励时的 93.6,也高于 FTB 的 85.4 和 P-IQL 的 65.3。在 MetaWorld 上,VOTP 平均成功率为 67.6,高于 SURF、FTB、P-IQL 等多数基线,仅低于 Oracle 和部分任务上的 LiRE。 从任务细节看,VOTP 在 Hopper medium-replay、Walker2d medium-expert、Door Open、Plate Slide 等任务上表现突出。尤其是 Door Open,VOTP 使用少量人工反馈与伪标签后达到 84.0 的成功率,与 LiRE 持平,并显著高于 P-IQL。 论文对比了几种伪标签生成方式:最近邻式的 SIM-individual、类均值式的 SIM-mean、相似度加权的 SIM-weighted,以及 VOTP。结果表明,简单相似度传播容易丢失偏好对中的细粒度差异,而 VOTP 通过最优传输建模相对对齐,生成的伪标签更可靠,学习曲线也更稳定。
6. 反馈效率:10 个偏好标签能做到什么
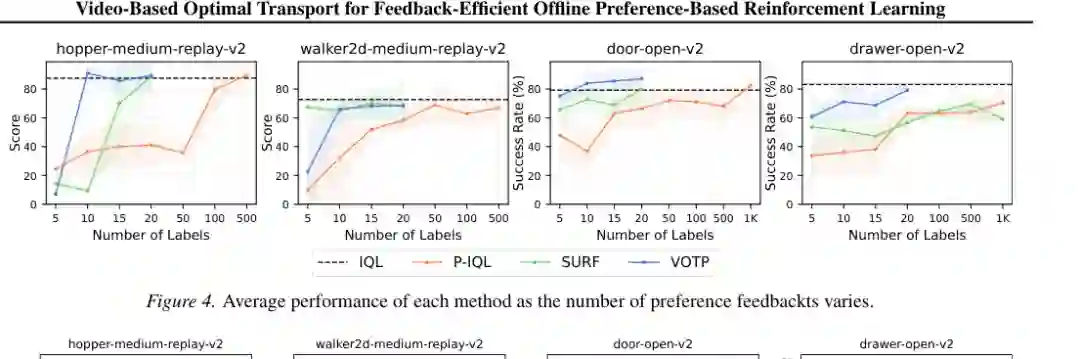
论文进一步改变人工偏好标签数量,观察 P-IQL、SURF 和 VOTP 的性能随标注预算变化。结果非常直观:没有伪标签时,P-IQL 在 D4RL 上通常需要 50 到 100 个偏好标签才能接近任务奖励训练;在 MetaWorld 上,需求可能上升到约 1000 个标签。 VOTP 则显著降低了这一门槛。除 Walker medium-replay 外,它通常用更少标签达到或接近任务奖励训练水平。在 Door Open 中,VOTP 只用 10 个偏好标签就超过了真实奖励训练策略。这并不意味着伪标签永远比真实奖励更好,而是说明在离线数据和视觉表征提供足够结构时,偏好传播可以弥补人工监督稀缺。
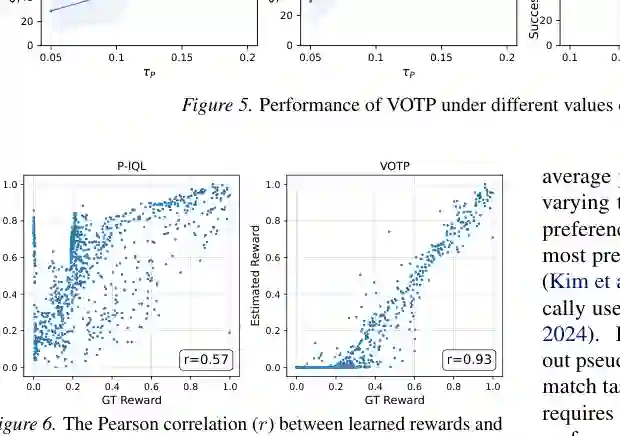
阈值实验也揭示了伪标签质量和数量之间的平衡。偏好阈值升高时,模型只保留更确定的伪标签,性能通常先提升;但阈值过高会丢掉太多伪标签,导致训练信号不足。实际使用中,阈值需要结合偏好分数分布和未标注数据规模调节。 奖励相关性分析进一步解释了性能来源。在 Door Open 中,VOTP 学到的奖励与真实奖励的 Pearson 相关性达到 0.93,而 P-IQL 只有 0.57。这说明伪标签扩展了奖励学习对状态动作空间的覆盖,使奖励模型不再只在极少量标注片段附近可靠。
7. 鲁棒性与真实机器人验证
由于 VOTP 依赖视频基础模型表征,一个自然问题是:如果视觉环境变化,伪标签是否会失效?论文在 MetaWorld 中加入光照位置与方向变化、环境光变化、纹理变化,以及动态视频背景扰动。结果显示,VOTP 在这些视觉干扰下仍保持较强表现,Door Open 和 Drawer Open 的平均性能没有灾难性下降,部分光照变化下甚至略有提升。 这与方法假设相符:大规模视频预训练使 ViFM 表征对视角、光照、背景等非任务因素具备一定不变性。对机器人来说,这一点很重要,因为真实环境中外观变化无法完全控制。 真实机器人实验使用 7 自由度 Rethink Sawyer 机械臂,任务包括 Lift Banana 和 Drawer Open。每个任务通过键盘遥操作收集演示,并让人类教师比较视频片段。标注预算仍然很低:Lift Banana 使用 5 个偏好标签,Drawer Open 使用 10 个偏好标签;同时分别使用 2000 和 3000 个未标注片段对进行伪标注。
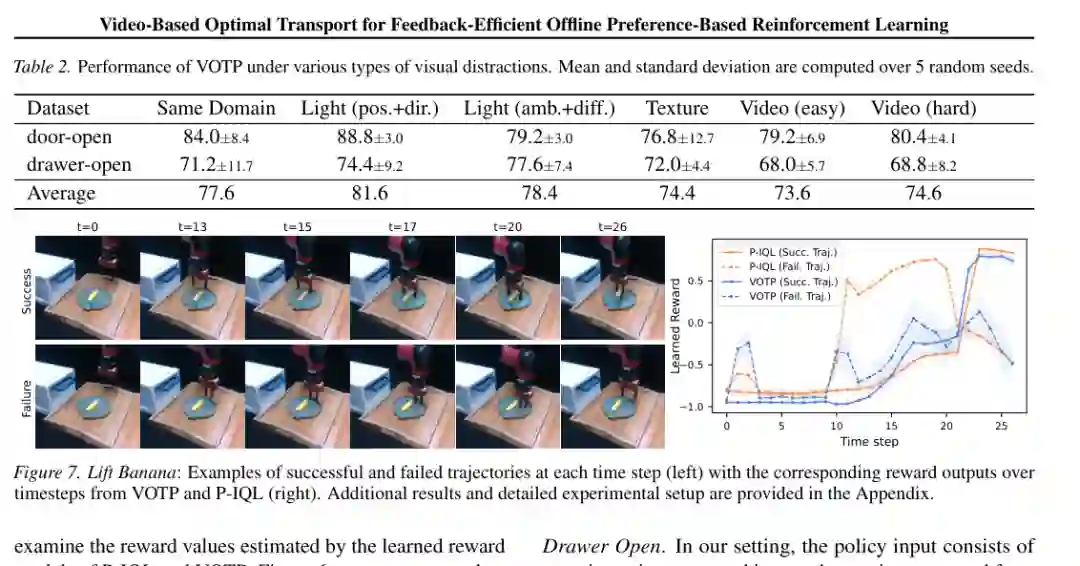
真实机器人结果显示,VOTP 在 Lift Banana 上成功率达到 80%,高于 BC 的 20% 和 P-IQL 的 50%;在 Drawer Open 上达到 70%,高于 BC 的 40% 和 P-IQL 的 50%。更重要的是奖励曲线:P-IQL 会在失败轨迹的某些时间段给出偏高奖励,而 VOTP 对成功与失败轨迹的奖励分离更清晰。这说明未标注数据不仅提升最终策略,也让奖励模型更少误判失败行为。
8. 为什么这篇论文值得关注
VOTP 的价值不在于提出一个更复杂的奖励网络,而在于把三类工具接到了一起:偏好强化学习、视频基础模型和最优传输。它把“少量人类偏好”转化为一种可传播的结构信号,让离线数据中的未标注视频片段也参与奖励学习。 这对机器人学习尤其有意义。机器人任务中,人工偏好比手写奖励更自然,但偏好标注仍然昂贵;离线数据却往往可以通过演示、历史轨迹或模拟环境大量获得。VOTP 提供了一条路线:用视频表征识别行为相似性,用最优传输避免粗糙最近邻匹配,再用高置信伪标签扩展奖励学习覆盖面。 同时,这篇论文也提醒我们,视觉基础模型在 RL 中不一定要直接输出奖励。直接让 VLM/ViFM 判断任务完成度可能受提示词、语义偏差和场景分布影响,而 VOTP 更像是把基础模型用作表征度量,再由少量人类偏好决定任务方向。这种“基础模型提供结构,人类反馈提供价值排序”的组合,比纯自动打分更可控。
9. 局限与未来方向
论文也指出了两个主要局限。 首先,VOTP 依赖预训练视频基础模型。如果 ViFM 的表征本身带有偏差,或者不能捕捉某类任务的关键差异,伪标签质量就会下降。比如精细接触力、透明物体、非视觉状态或需要长期因果判断的任务,可能不是普通视频表征擅长的区域。因此,部署到安全关键机器人前仍需要严格验证策略行为,而不能只相信伪标签扩增。 其次,最优传输计算会随标注片段和未标注片段规模增长而变重。论文实验中成本可控,但更大规模数据、更长视频片段或在线迭代场景可能需要近似传输、分层传输或更高效的检索预筛选。 未来可以沿三条方向扩展。第一,使用更强视频模型或机器人视频预训练模型,提升对操作细节的敏感性。第二,把 VOTP 与主动学习结合,让系统优先请求那些最能改善传输结构的人类偏好。第三,把伪标签置信度、奖励不确定性和策略安全约束联合起来,避免错误偏好在训练中被放大。
10. 小结
VOTP 面向一个非常实际的问题:如何在只有极少人工偏好的情况下,让离线偏好强化学习仍能学到有用奖励。它利用视频基础模型把行为片段嵌入语义丰富的时空表征空间,再用最优传输把已标注偏好传播到大量未标注片段对,从而生成高置信伪偏好标签。 实验表明,在 D4RL、MetaWorld 和真实 Sawyer 机器人任务上,VOTP 在低反馈预算下显著优于多种离线 PbRL 基线,并能在视觉扰动下保持鲁棒。更重要的是,它给出了一个清晰启示:在人类偏好昂贵、离线数据充足、行为又天然以视频呈现的场景中,视频表征与结构化偏好传播可能是提高反馈效率的一条有效路径。 论文地址:https://arxiv.org/abs/2606.16856
