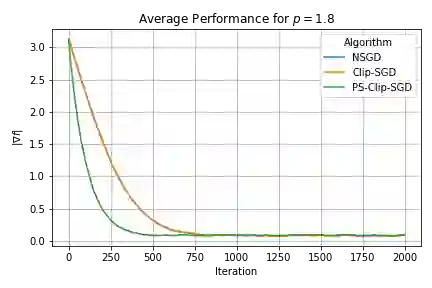
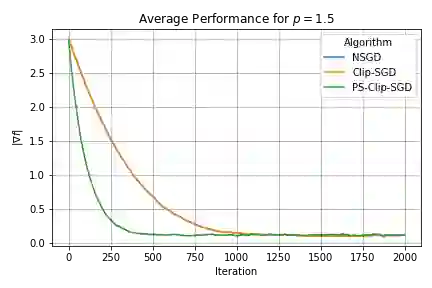
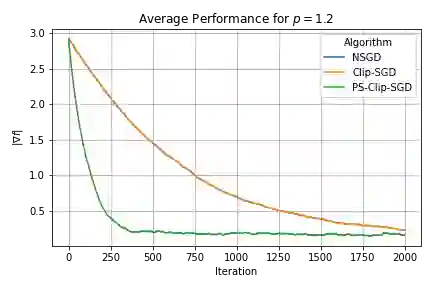
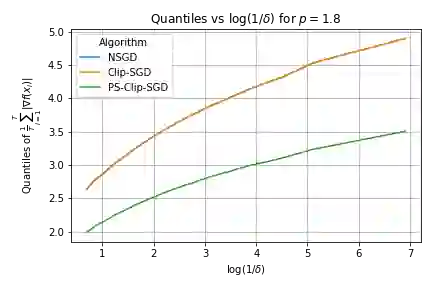
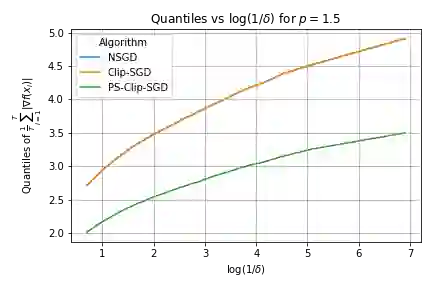
We propose a robust gradient estimator based on per-sample gradient clipping and analyze its properties both theoretically and empirically. We show that the resulting method, per-sample clipped SGD (PS-Clip-SGD), achieves optimal in-expectation convergence rates for non-convex optimization problems under heavy-tailed gradient noise. Moreover, we establish high-probability convergence guarantees that match the in-expectation rates up to polylogarithmic factors in the failure probability. We complement our theoretical results with multiple numerical experiments. In particular, we demonstrate that PS-Clip-SGD outperforms both vanilla SGD with momentum and standard gradient clipping when training AlexNet on the CIFAR-100 dataset, even after accounting for the additional computational time caused by per-sample clipping. We also empirically show that, in the presence of gradient accumulation, applying clipping at the mini-batch level can improve training performance while incurring virtually no additional computational cost. This finding is particularly interesting, as it contradicts the common practice of applying clipping only after all accumulation steps have been completed.
翻译:本文提出了一种基于逐样本梯度裁剪的鲁棒梯度估计器,并从理论和实验两方面分析了其性质。我们表明,由此产生的方法——逐样本裁剪SGD(PS-Clip-SGD)在非凸优化问题中,当存在重尾梯度噪声时,能够实现最优的期望收敛速率。此外,我们建立了失败概率对数因子以内的、与期望速率相匹配的高概率收敛保证。我们通过多项数值实验补充了理论结果。特别地,我们证明,在CIFAR-100数据集上训练AlexNet时,即使考虑逐样本裁剪带来的额外计算时间,PS-Clip-SGD在性能上仍优于带动量的普通SGD和标准梯度裁剪。我们还通过实验表明,在存在梯度累积的情况下,在小批量层面应用裁剪可以在几乎没有额外计算成本的情况下提升训练性能。这一发现尤其引人关注,因为它与仅在完成所有累积步骤后才进行裁剪的常见做法相悖。