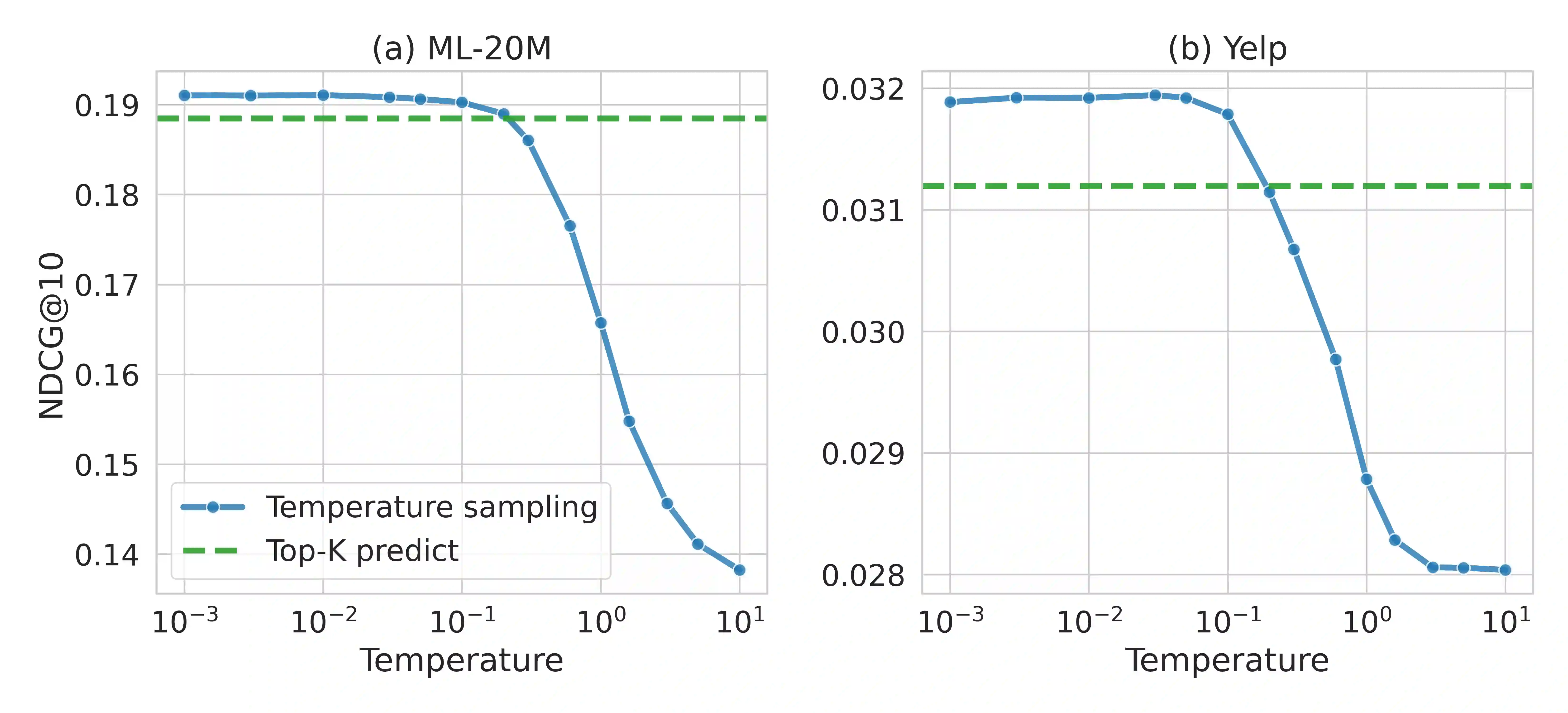
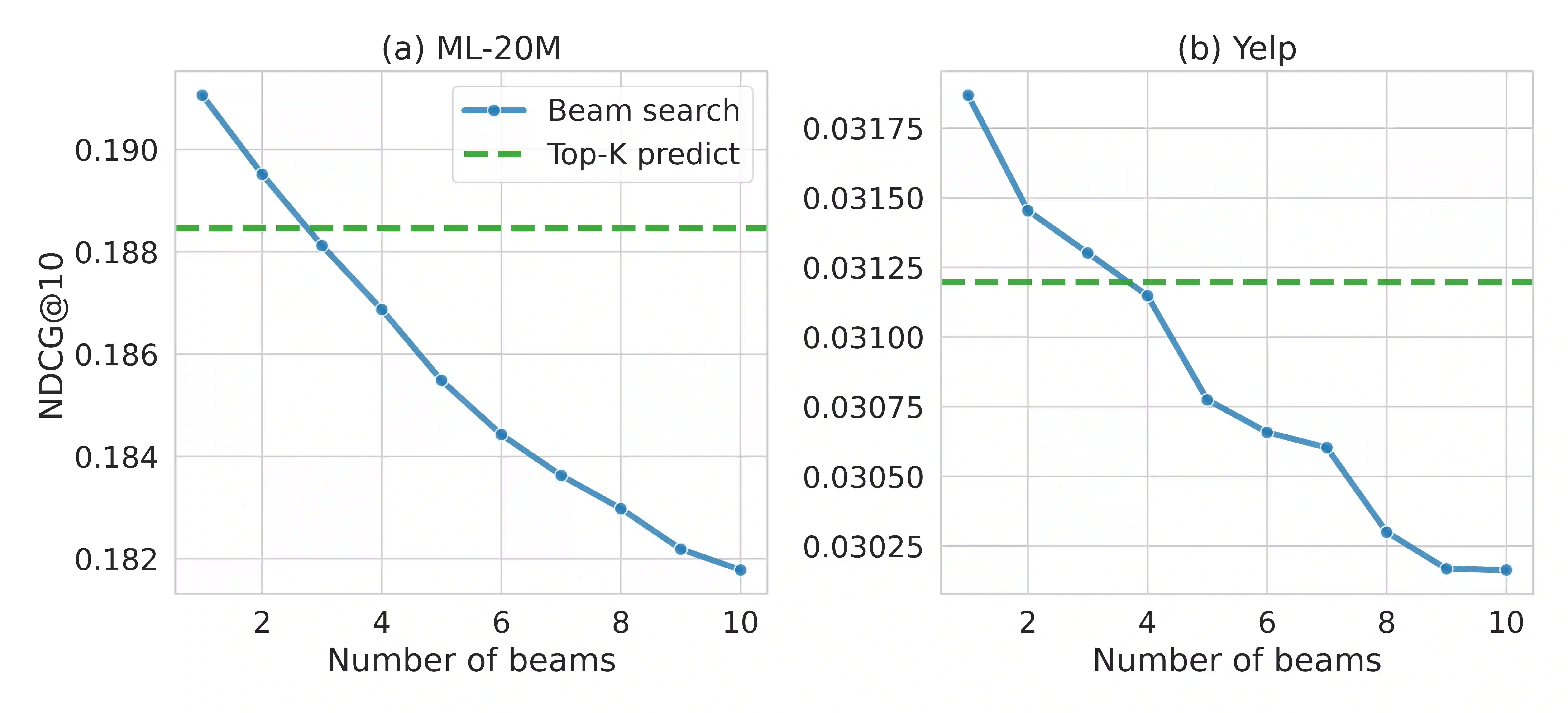
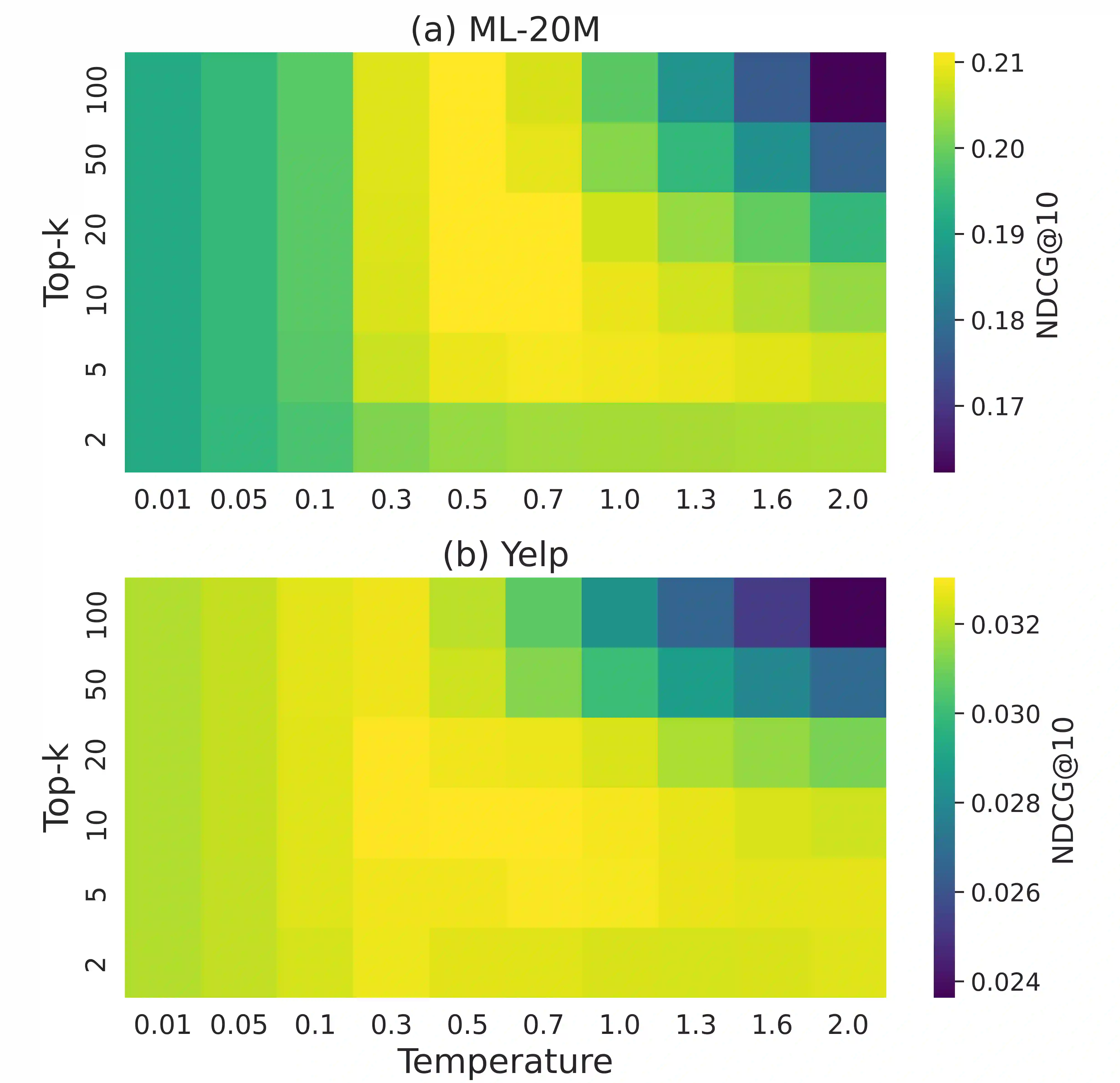
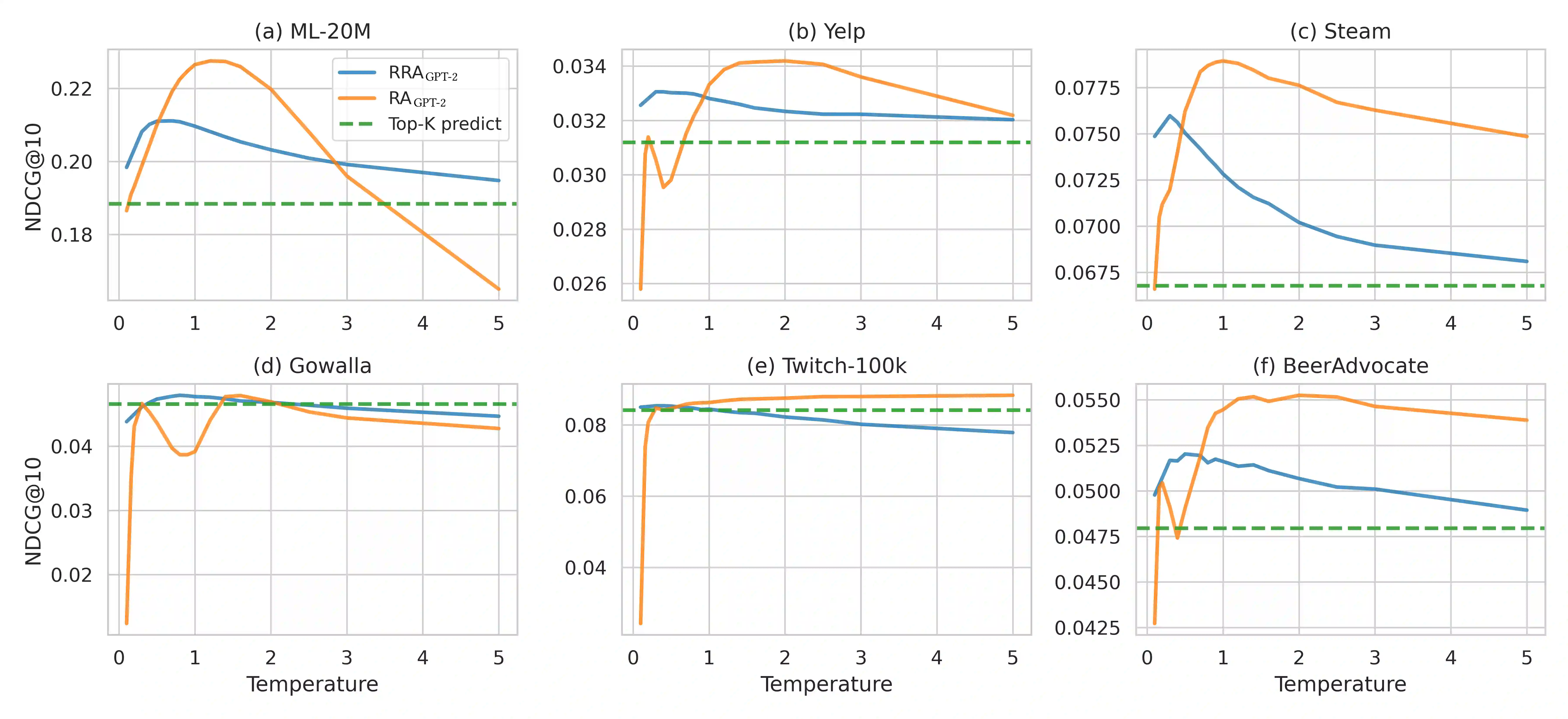
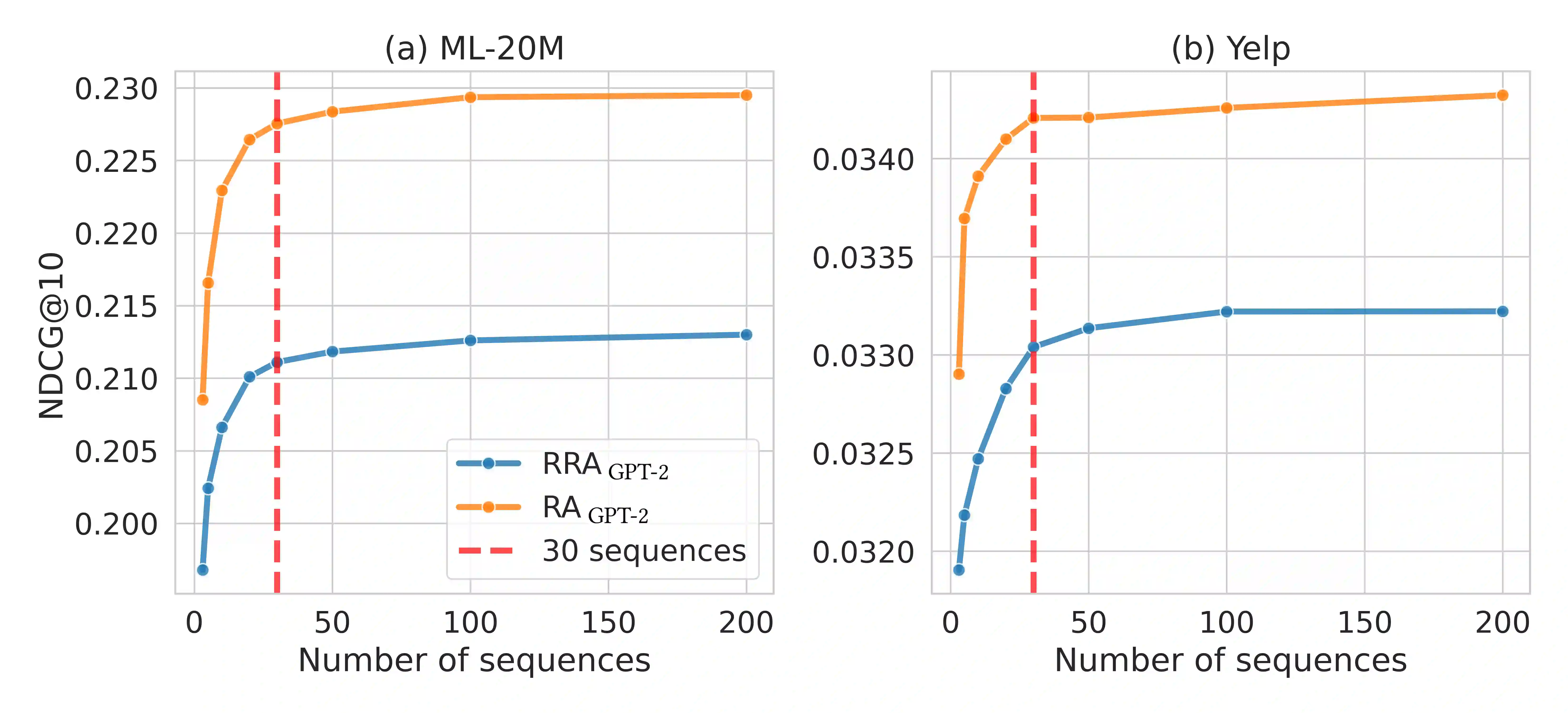
The goal of modern sequential recommender systems is often formulated in terms of next-item prediction. In this paper, we explore the applicability of generative transformer-based models for the Top-K sequential recommendation task, where the goal is to predict items a user is likely to interact with in the "near future". We explore commonly used autoregressive generation strategies, including greedy decoding, beam search, and temperature sampling, to evaluate their performance for the Top-K sequential recommendation task. In addition, we propose novel Reciprocal Rank Aggregation (RRA) and Relevance Aggregation (RA) generation strategies based on multi-sequence generation with temperature sampling and subsequent aggregation. Experiments on diverse datasets give valuable insights regarding commonly used strategies' applicability and show that suggested approaches improve performance on longer time horizons compared to widely-used Top-K prediction approach and single-sequence autoregressive generation strategies.
翻译:现代序列推荐系统的目标通常被表述为下一项预测。本文探讨了基于生成式Transformer模型在Top-K序列推荐任务中的适用性,该任务的目标是预测用户在"近期"可能交互的项目。我们研究了常用的自回归生成策略,包括贪心解码、束搜索和温度采样,以评估它们在Top-K序列推荐任务中的性能。此外,我们提出了基于多序列生成与温度采样及后续聚合的新型倒数秩聚合(RRA)和相关性聚合(RA)生成策略。在不同数据集上的实验为常用策略的适用性提供了有价值的见解,并表明与广泛使用的Top-K预测方法和单序列自回归生成策略相比,所提出的方法在更长的时间跨度上提升了性能。