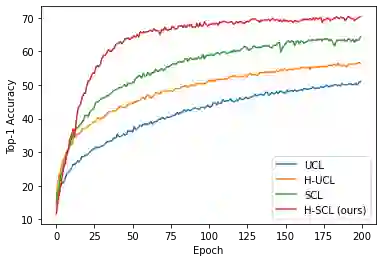
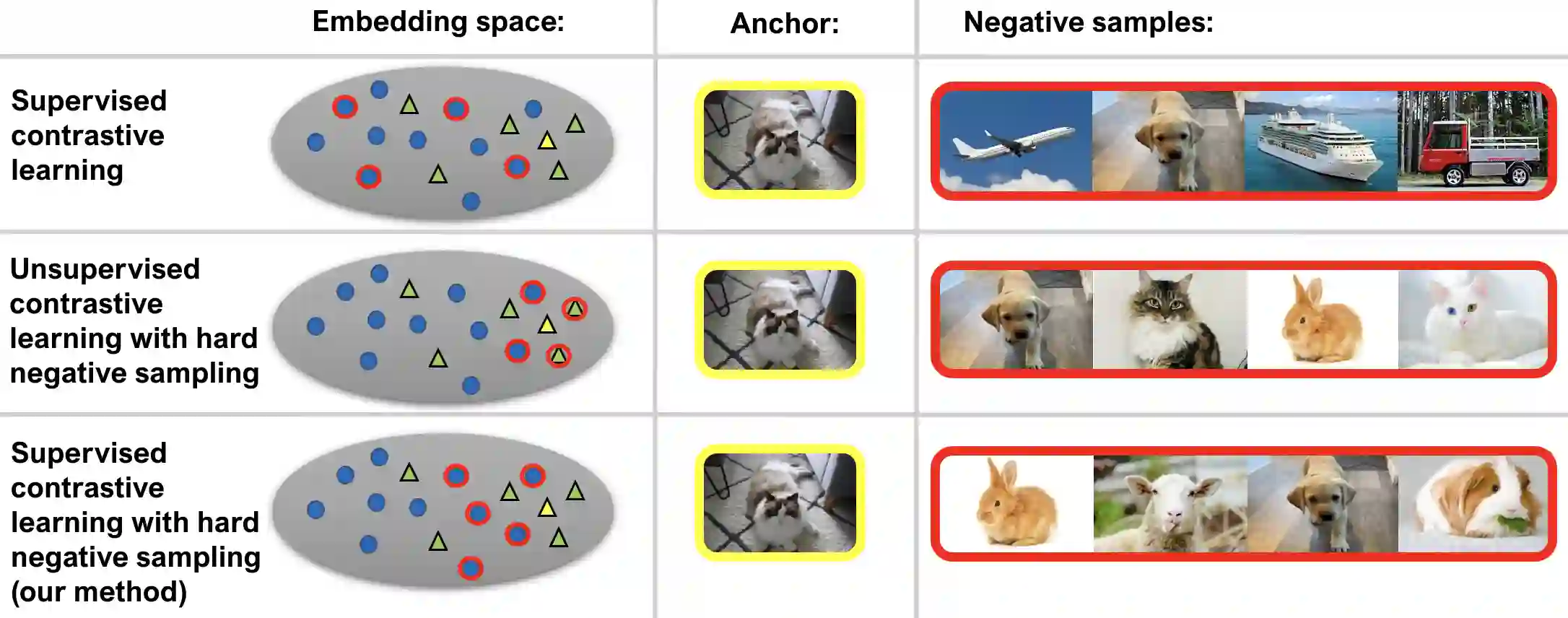
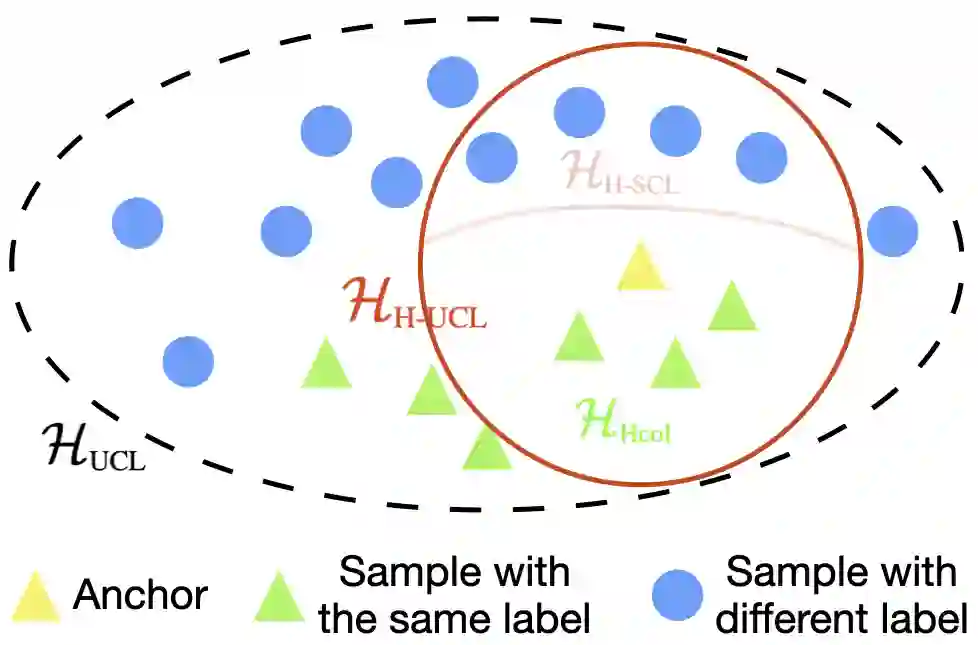
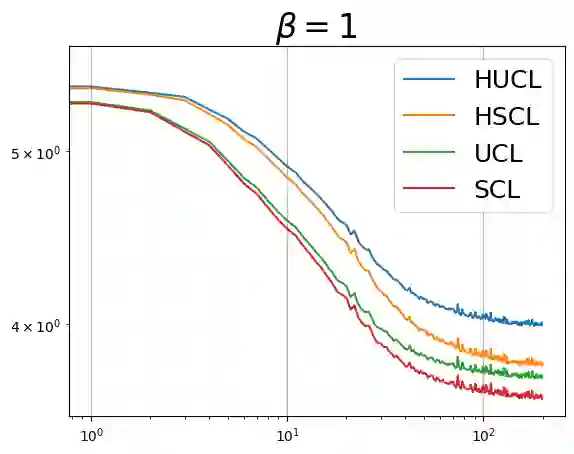
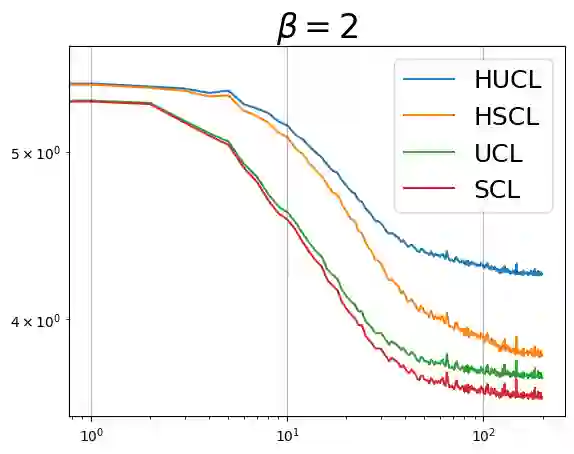
Through minimization of an appropriate loss function such as the InfoNCE loss, contrastive learning (CL) learns a useful representation function by pulling positive samples close to each other while pushing negative samples far apart in the embedding space. The positive samples are typically created using "label-preserving" augmentations, i.e., domain-specific transformations of a given datum or anchor. In absence of class information, in unsupervised CL (UCL), the negative samples are typically chosen randomly and independently of the anchor from a preset negative sampling distribution over the entire dataset. This leads to class-collisions in UCL. Supervised CL (SCL), avoids this class collision by conditioning the negative sampling distribution to samples having labels different from that of the anchor. In hard-UCL (H-UCL), which has been shown to be an effective method to further enhance UCL, the negative sampling distribution is conditionally tilted, by means of a hardening function, towards samples that are closer to the anchor. Motivated by this, in this paper we propose hard-SCL (H-SCL) {wherein} the class conditional negative sampling distribution {is tilted} via a hardening function. Our simulation results confirm the utility of H-SCL over SCL with significant performance gains {in downstream classification tasks.} Analytically, we show that {in the} limit of infinite negative samples per anchor and a suitable assumption, the {H-SCL loss} is upper bounded by the {H-UCL loss}, thereby justifying the utility of H-UCL {for controlling} the H-SCL loss in the absence of label information. Through experiments on several datasets, we verify the assumption as well as the claimed inequality between H-UCL and H-SCL losses. We also provide a plausible scenario where H-SCL loss is lower bounded by UCL loss, indicating the limited utility of UCL in controlling the H-SCL loss.
翻译:通过最小化适当的损失函数(如InfoNCE损失),对比学习通过学习一种有用的表示函数,使正样本在嵌入空间中相互靠近,同时使负样本相互远离。正样本通常通过"标签保持"增强(即对给定数据点或锚点的领域特定变换)来创建。在缺乏类别信息的无监督对比学习(UCL)中,负样本通常从整个数据集的预设负采样分布中随机选择,且独立于锚点。这导致UCL中出现类别碰撞问题。监督对比学习(SCL)通过将负采样分布限制在锚点标签不同的样本上,避免了类别碰撞。硬负样本无监督对比学习(H-UCL)已被证明是进一步增强UCL的有效方法,其负采样分布通过硬化函数条件倾斜,使得更接近锚点的样本被采样概率更高。受此启发,本文提出硬负样本监督对比学习(H-SCL),其中基于类别的负采样分布通过硬化函数进行倾斜。仿真结果证实,H-SCL相比SCL在下游分类任务中具有显著性能提升。从理论上,我们证明在每锚点无限负样本的极限条件下,并在适当假设下,H-SCL损失以H-UCL损失为上界,从而论证了在缺乏标签信息时利用H-UCL控制H-SCL损失的有效性。通过在多个数据集上的实验,我们验证了该假设以及H-UCL与H-SCL损失之间的不等式关系。同时,我们提出一种合理场景,其中H-SCL损失以UCL损失为下界,表明UCL在控制H-SCL损失方面的局限性。