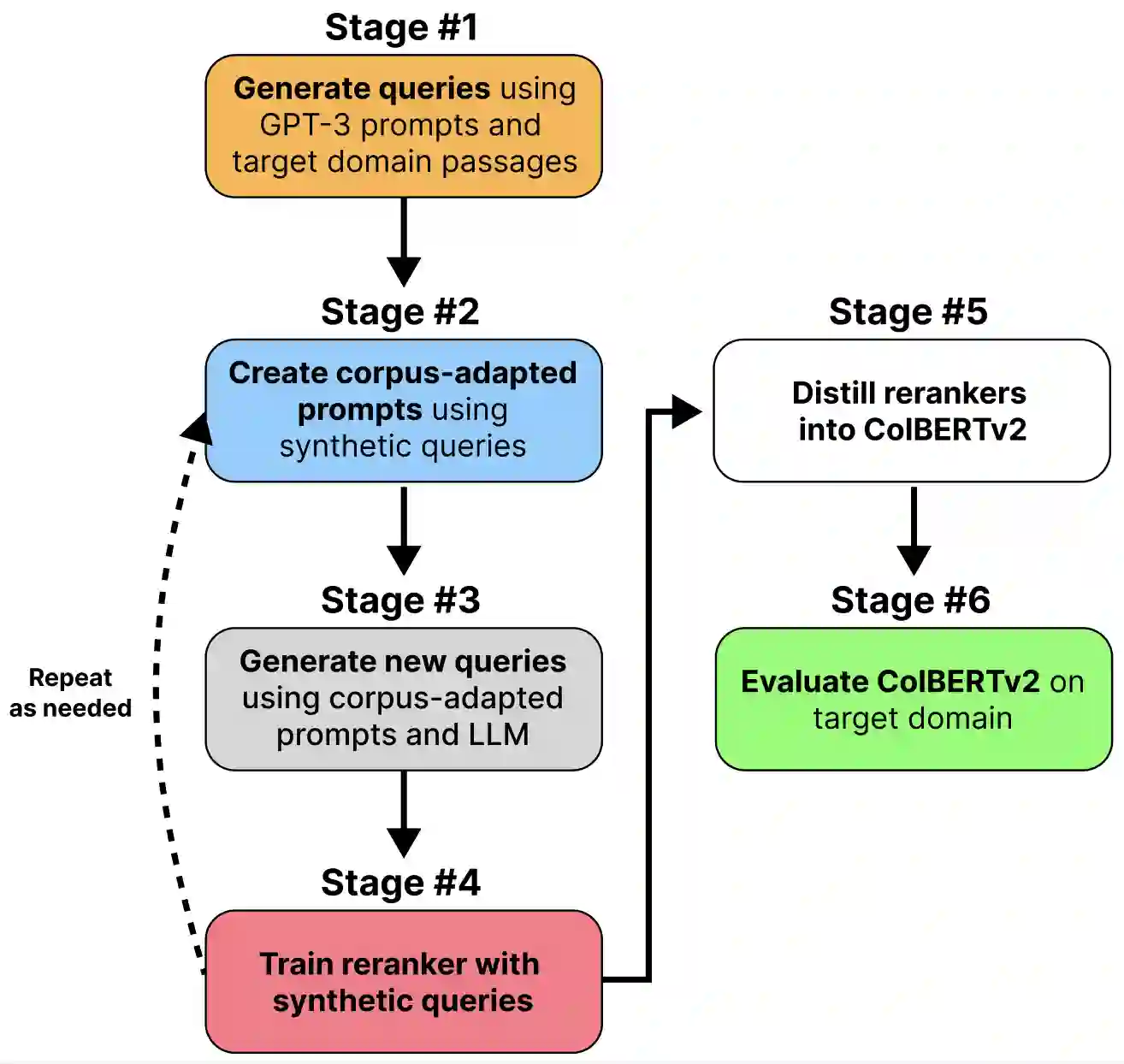
Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github: https://github.com/primeqa/primeqa.
翻译:许多信息检索任务需要大量标注数据集进行微调,然而此类数据集往往难以获取,且由于领域偏移,其在实际应用中的效用会迅速降低。为解决这一挑战,我们开发并论证了一种利用大语言模型(LLM)低成本生成大量合成查询的方法。该方法首先使用昂贵的LLM生成少量合成查询,随后通过成本更低的LLM生成大量合成查询,用于微调一系列重排序器模型。这些重排序器最终被蒸馏为一个适用于目标领域的高效检索器。实验表明,即使在仅用2K合成查询进行微调的情况下,该技术也能提升长尾领域的零样本准确率,且延迟显著低于标准重排序方法。我们已将端到端方案(包括合成数据集与复现代码)开源至GitHub:https://github.com/primeqa/primeqa。