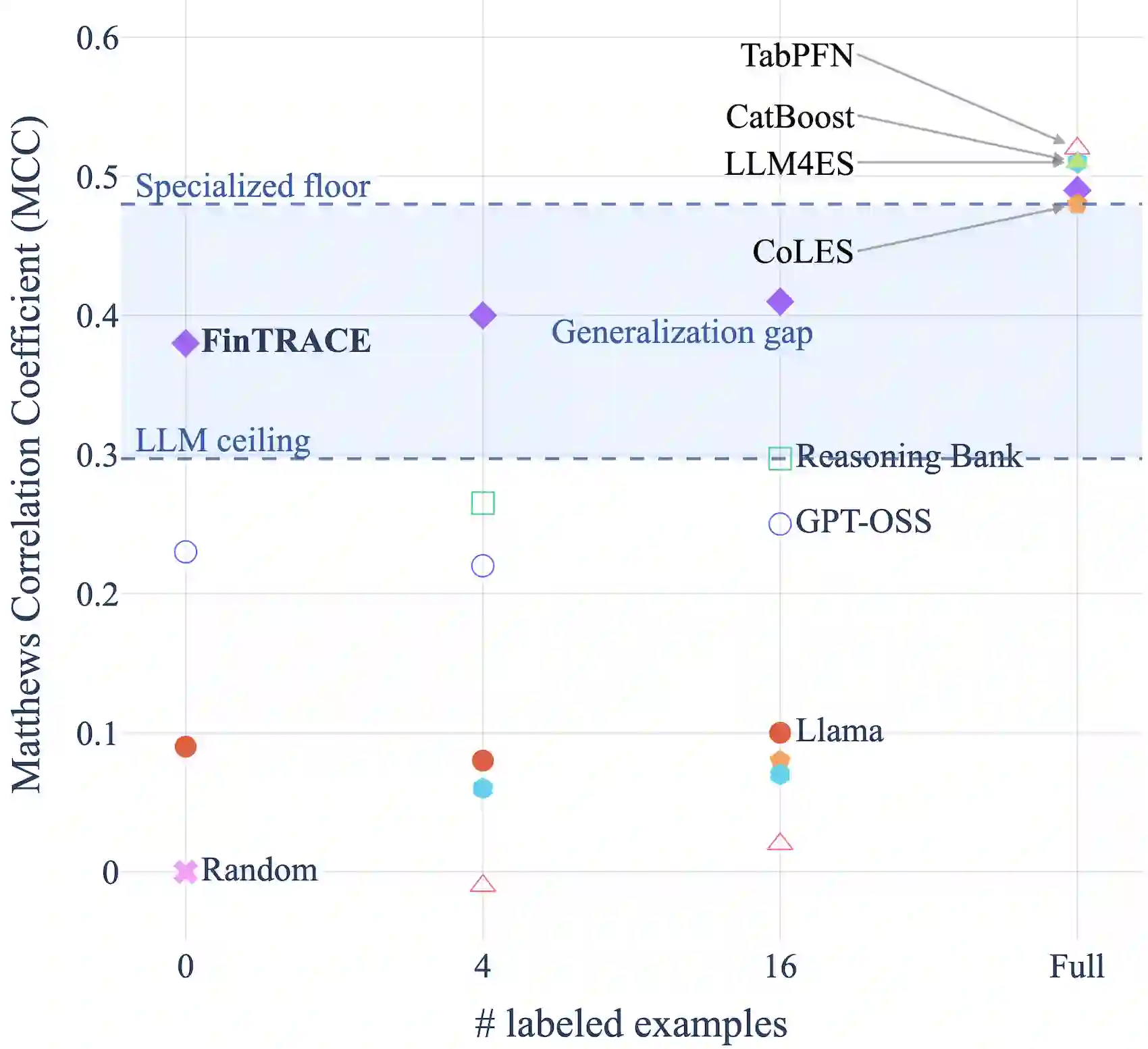
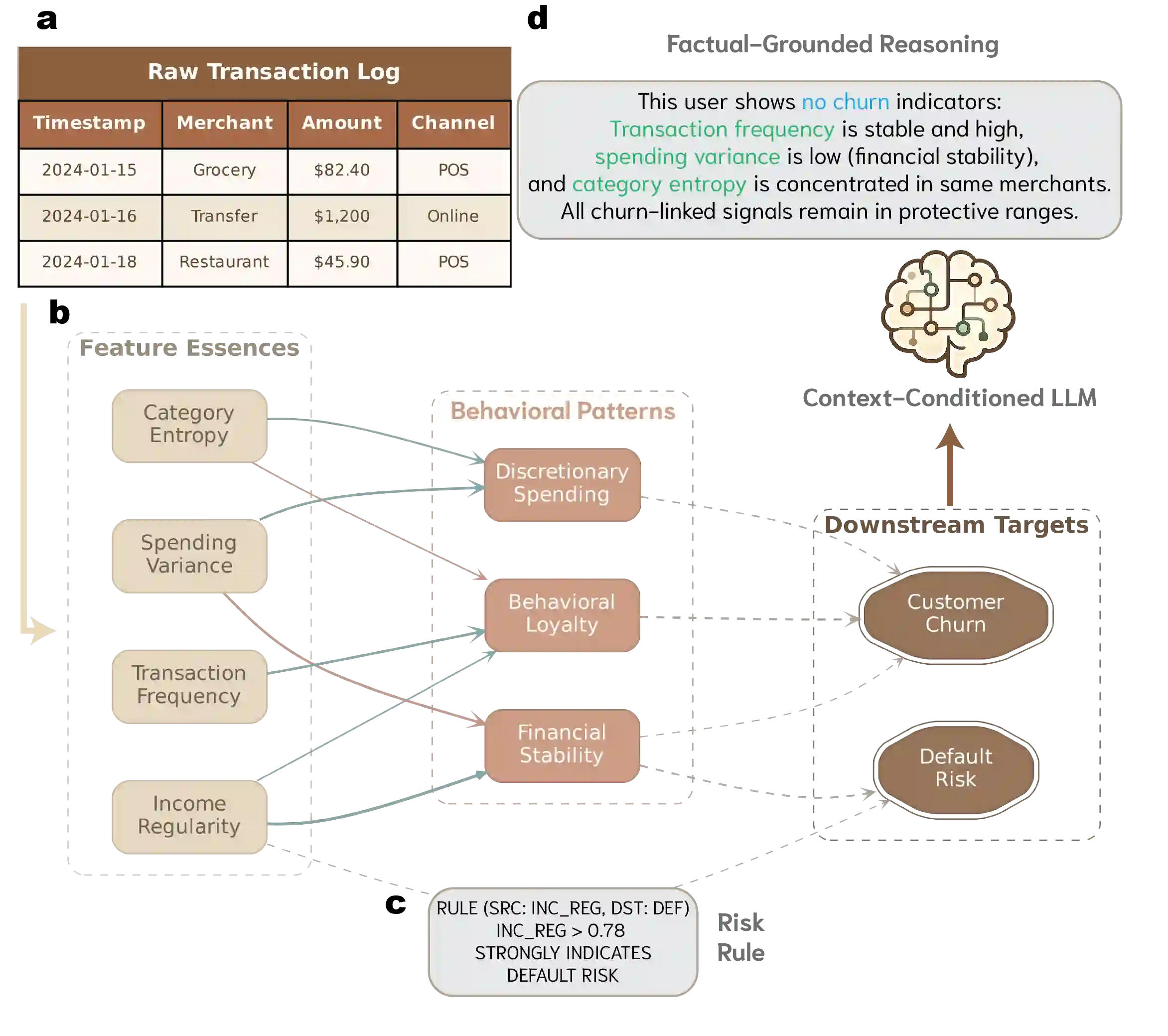
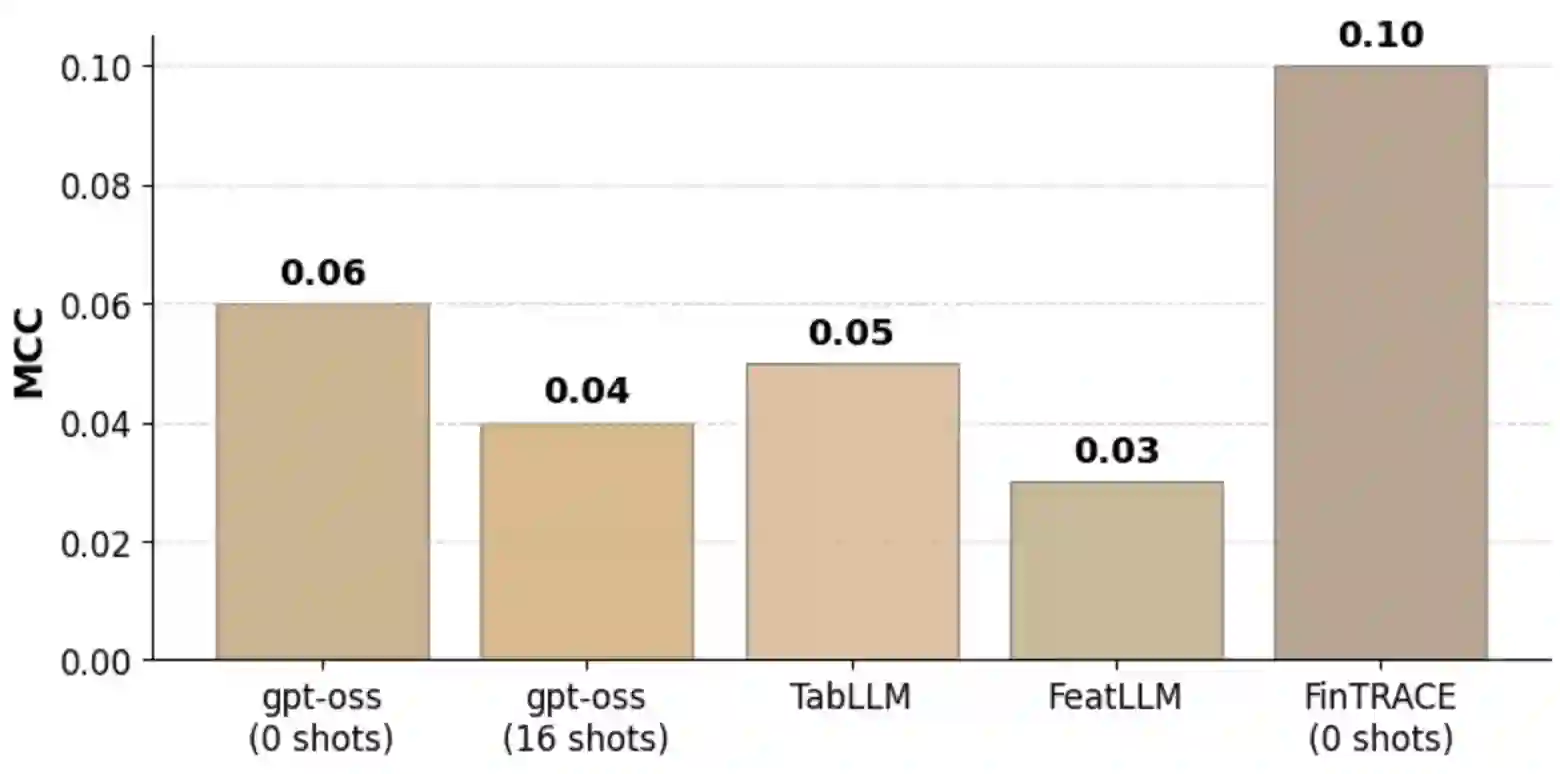
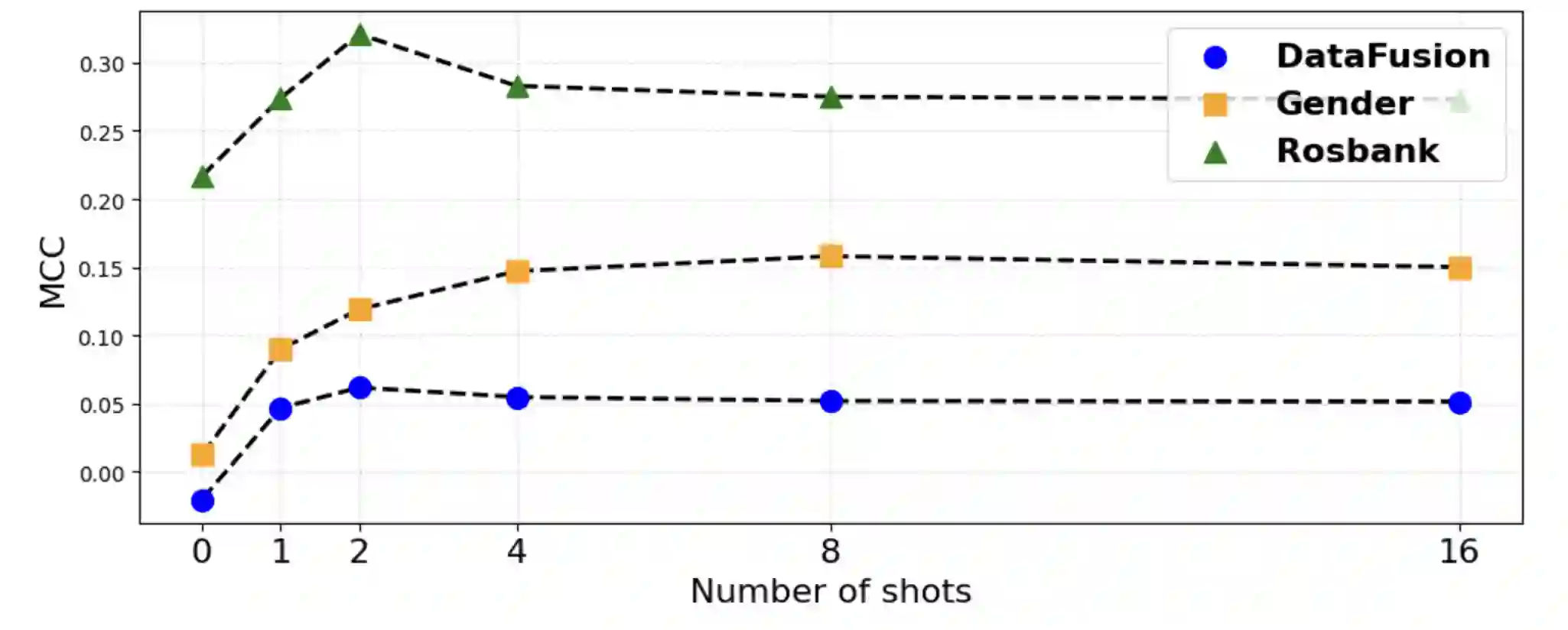
Nowadays, success of financial organizations heavily depends on their ability to process digital traces generated by their clients, e.g., transaction histories, gathered from various sources to improve user modeling pipelines. As general-purpose LLMs struggle with time-distributed tabular data, production stacks still depend on specialized tabular and sequence models with limited transferability and need for labeled data. To address this, we introduce FinTRACE, a retrieval-first architecture that converts raw transactions into reusable feature representations, applies rule-based detectors, and stores the resulting signals in a behavioral knowledge base with graded associations to the objectives of downstream tasks. Across public and industrial benchmarks, FinTRACE substantially improves low-supervision transaction analytics, doubling zero-shot MCC on churn prediction performance from 0.19 to 0.38 and improving 16-shot MCC from 0.25 to 0.40. We further use FinTRACE to ground LLMs via instruction tuning on retrieved behavioral patterns, achieving state-of-the-art LLM results on transaction analytics problems.
翻译:如今,金融机构的成功在很大程度上取决于其处理客户数字痕迹的能力,例如从不同来源收集的交易历史,以优化用户建模流程。由于通用大语言模型难以处理时间分布的表格数据,生产系统仍依赖于可迁移性有限且需要标注数据的专用表格与序列模型。为解决这一问题,我们提出了FinTRACE——一种检索优先的架构,该架构将原始交易转化为可复用的特征表示,应用基于规则的检测器,并将生成的信号存储于行为知识库中,同时建立与下游任务目标的分级关联。在公开及工业基准测试中,FinTRACE显著提升了低监督条件下的交易分析性能:在流失预测任务中,零样本马修斯相关系数从0.19提升至0.38(实现翻倍),16样本马修斯相关系数从0.25提升至0.40。我们进一步利用FinTRACE,通过对检索到的行为模式进行指令微调来增强大语言模型的推理基础,从而在交易分析问题上实现了当前最优的大语言模型性能。