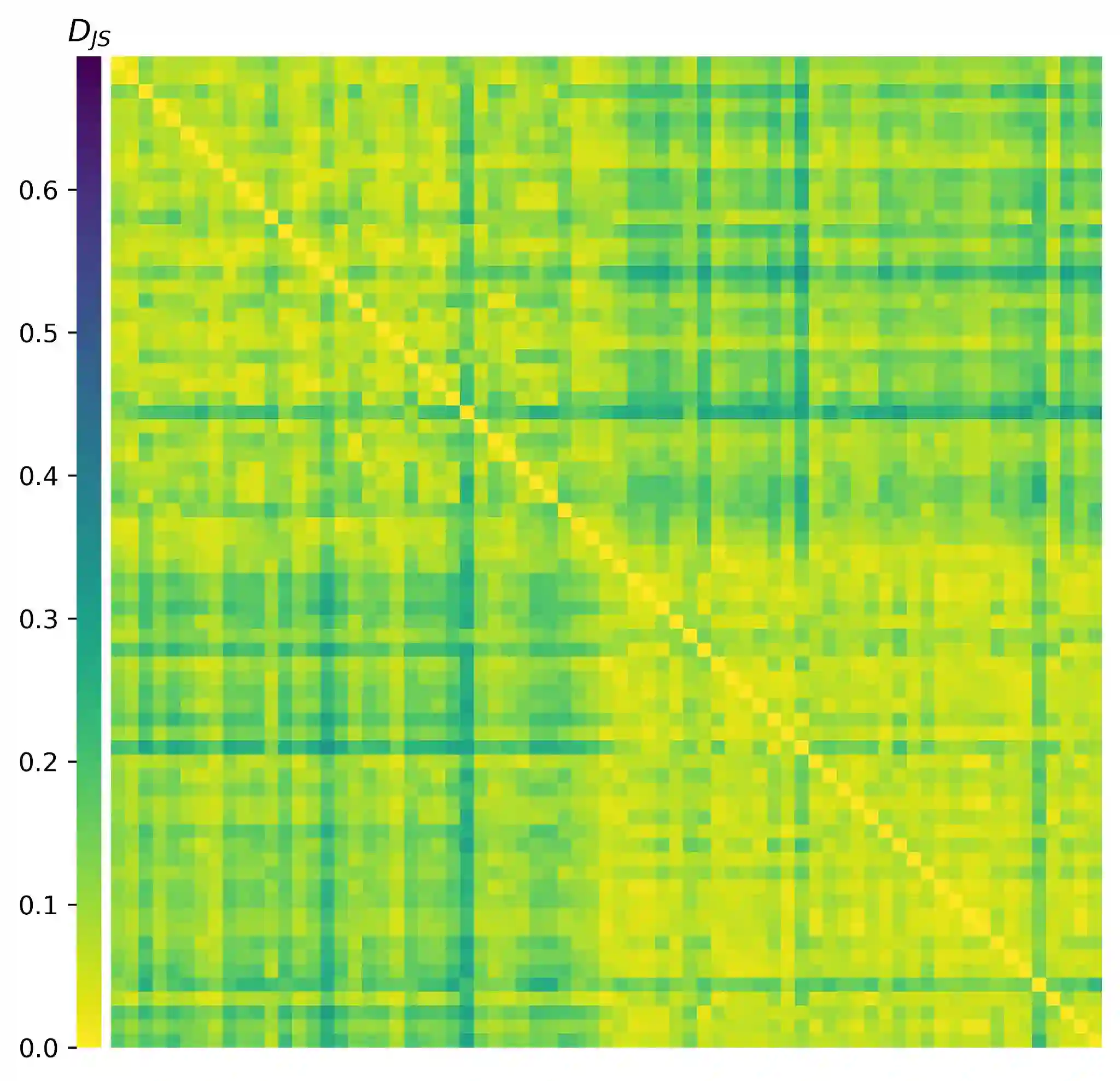
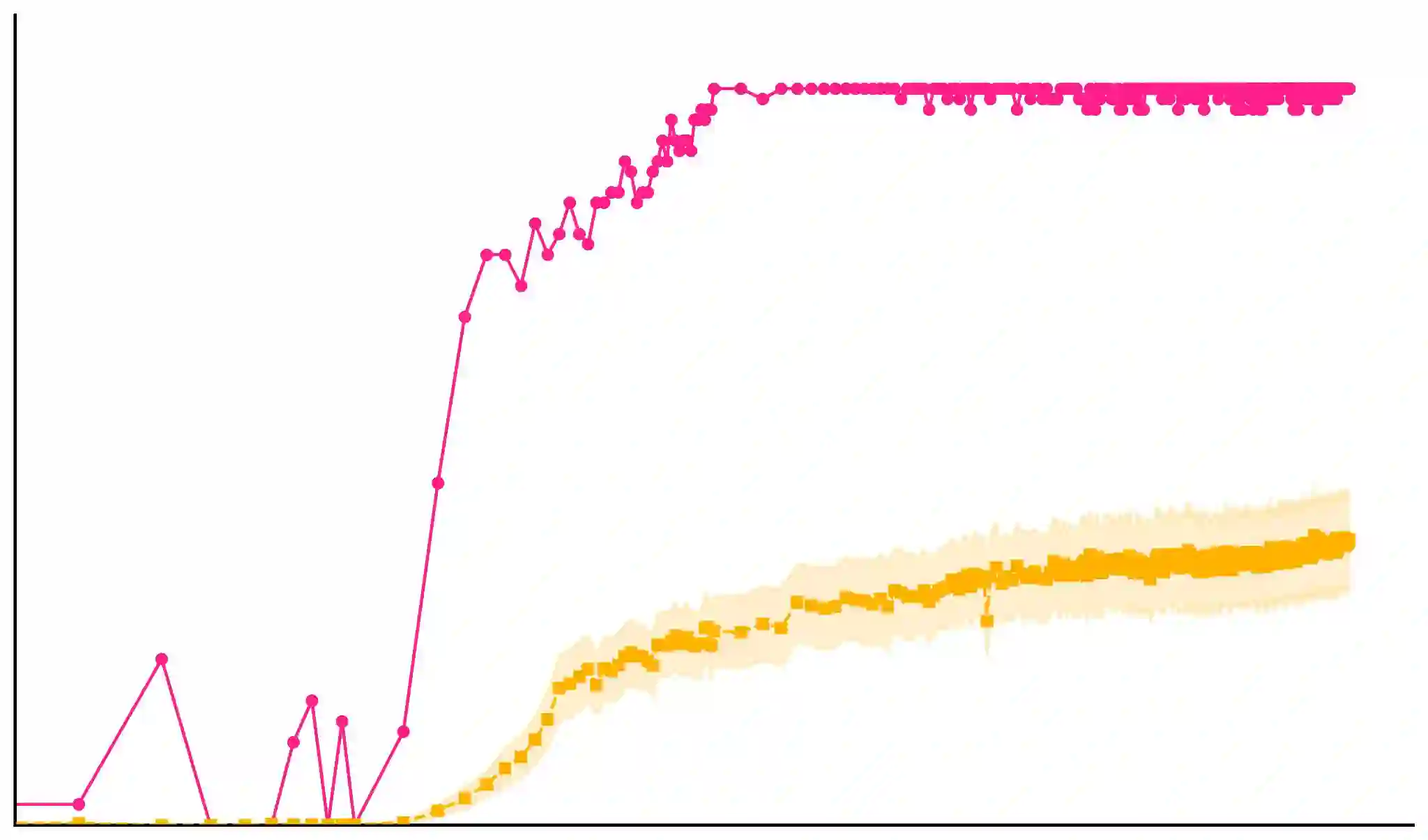
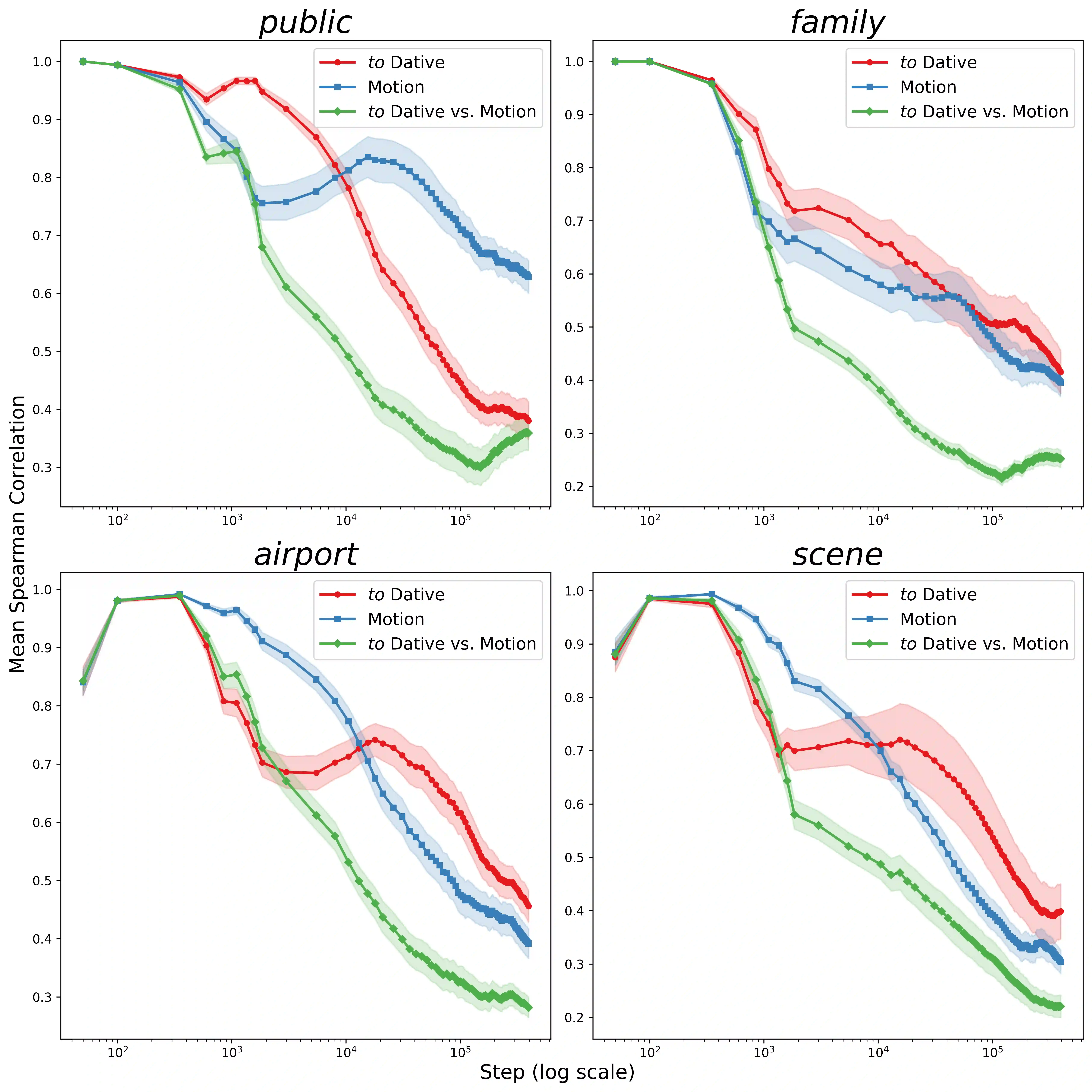
Categorization is a core component of human linguistic competence. We investigate how a transformer-based language model (LM) learns linguistic categories by comparing its behaviour over the course of training to behaviours which characterize abstract feature-based and concrete exemplar-based accounts of human language acquisition. We investigate how lexical semantic and syntactic categories emerge using novel divergence-based metrics that track learning trajectories using next-token distributions. In experiments with GPT-2 small, we find that (i) when a construction is learned, abstract class-level behaviour is evident at earlier steps than lexical item-specific behaviour, and (ii) that different linguistic behaviours emerge abruptly in sequence at different points in training, revealing that abstraction plays a key role in how LMs learn. This result informs the models of human language acquisition that LMs may serve as an existence proof for.
翻译:分类是人类语言能力的核心组成部分。本研究通过比较基于Transformer的语言模型在训练过程中的行为与人类语言习得中基于抽象特征和基于具体样例的两种理论所描述的行为特征,探究了此类模型如何习得语言范畴。我们采用基于分布差异的新型度量方法,通过追踪下一词元分布的学习轨迹,考察词汇语义和句法范畴的涌现过程。在GPT-2 small模型的实验中,我们发现:(i)当某个语言结构被习得时,抽象的类别层面行为比具体的词汇项目层面行为更早显现;(ii)不同的语言行为在训练过程中以突发序列形式在不同阶段涌现,表明抽象化在语言模型的学习过程中起着关键作用。这一结果为语言模型可能作为存在性证明的人类语言习得模型提供了新的启示。