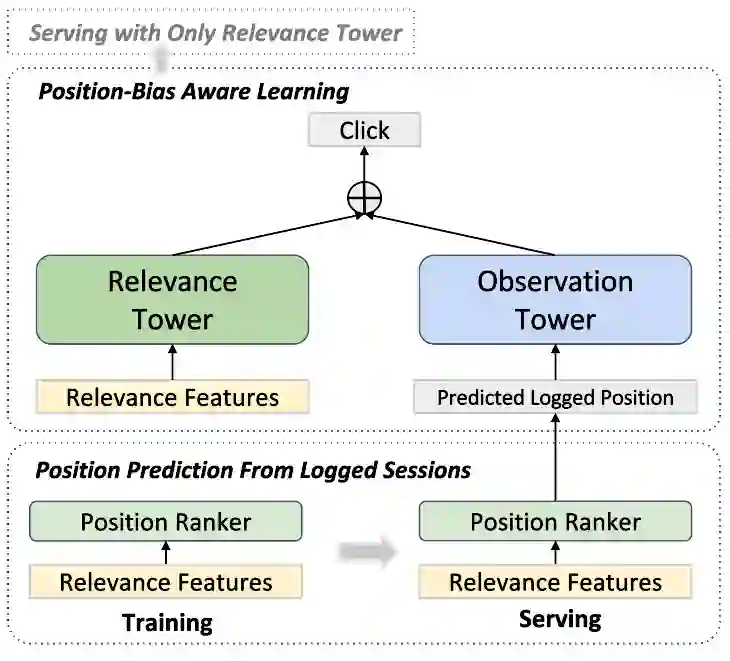
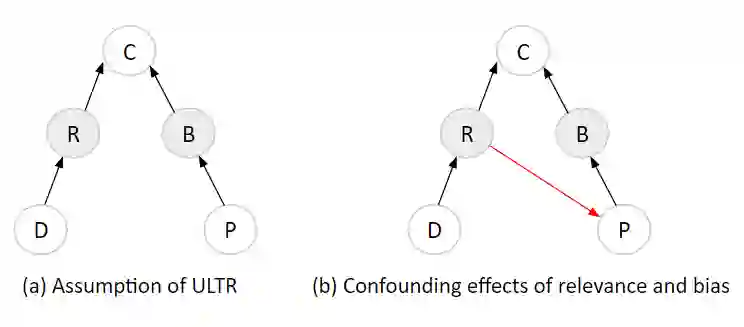
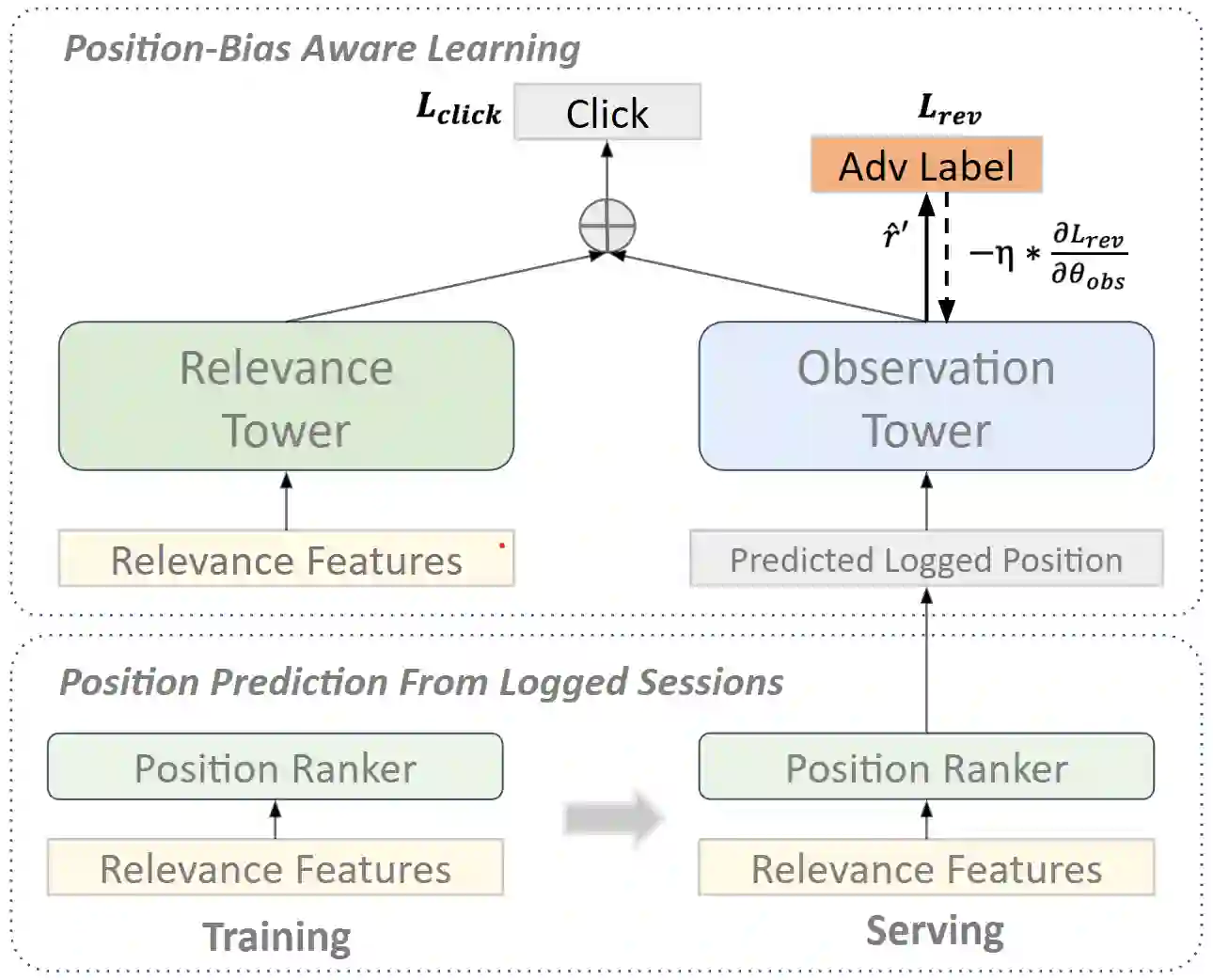
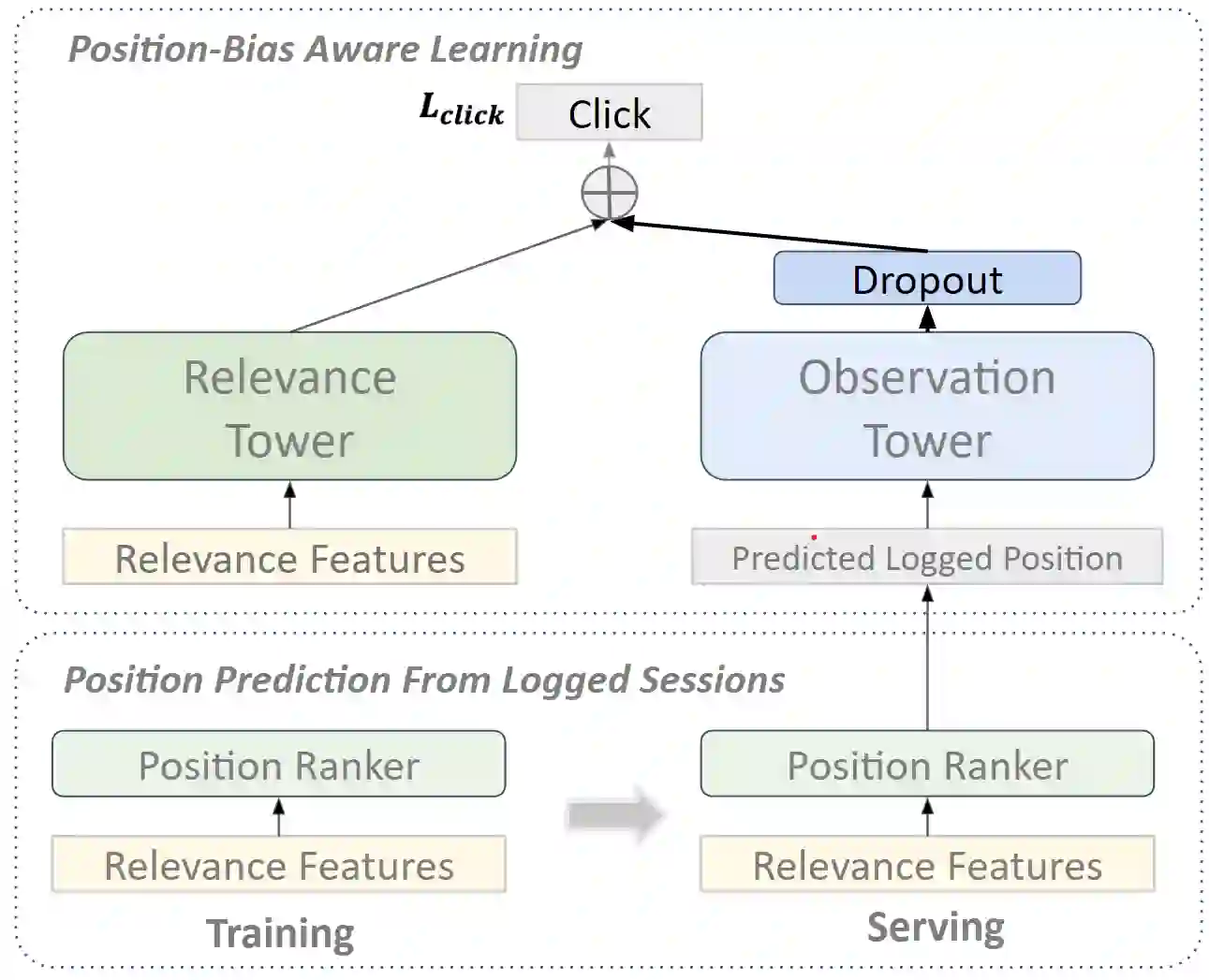
Unbiased learning to rank (ULTR) studies the problem of mitigating various biases from implicit user feedback data such as clicks, and has been receiving considerable attention recently. A popular ULTR approach for real-world applications uses a two-tower architecture, where click modeling is factorized into a relevance tower with regular input features, and a bias tower with bias-relevant inputs such as the position of a document. A successful factorization will allow the relevance tower to be exempt from biases. In this work, we identify a critical issue that existing ULTR methods ignored - the bias tower can be confounded with the relevance tower via the underlying true relevance. In particular, the positions were determined by the logging policy, i.e., the previous production model, which would possess relevance information. We give both theoretical analysis and empirical results to show the negative effects on relevance tower due to such a correlation. We then propose three methods to mitigate the negative confounding effects by better disentangling relevance and bias. Empirical results on both controlled public datasets and a large-scale industry dataset show the effectiveness of the proposed approaches.
翻译:无偏学习排序(ULTR)研究从隐式用户反馈数据(如点击)中减轻各种偏差的问题,近年来受到广泛关注。在实际应用中,一种流行的ULTR方法采用双塔架构,其中点击建模被分解为具有常规输入特征的相关性塔和具有偏差相关输入(如文档位置)的偏差塔。成功的分解将使相关性塔免受偏差影响。本文发现现有ULTR方法忽略的一个关键问题——偏差塔可能通过潜在的真实相关性与相关性塔产生混杂。具体而言,位置由日志策略(即先前生产模型)决定,该策略本身包含相关性信息。我们通过理论分析和实证结果展示了这种相关性对相关性塔产生的负面影响。随后,我们提出三种方法,通过更好地解耦相关性与偏差来减轻这种负面混杂效应。在受控公开数据集和大规模工业数据集上的实证结果证明了所提方法的有效性。