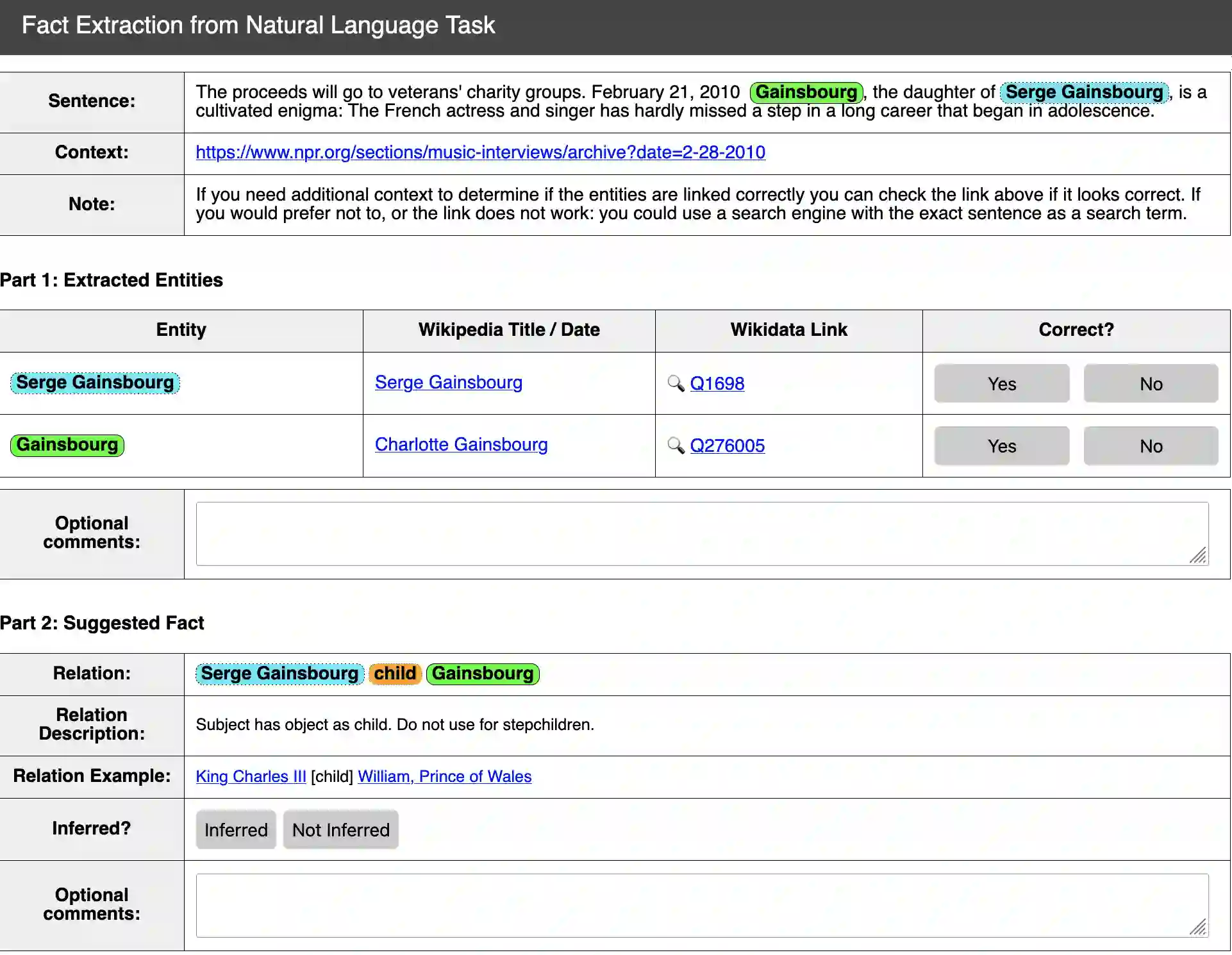
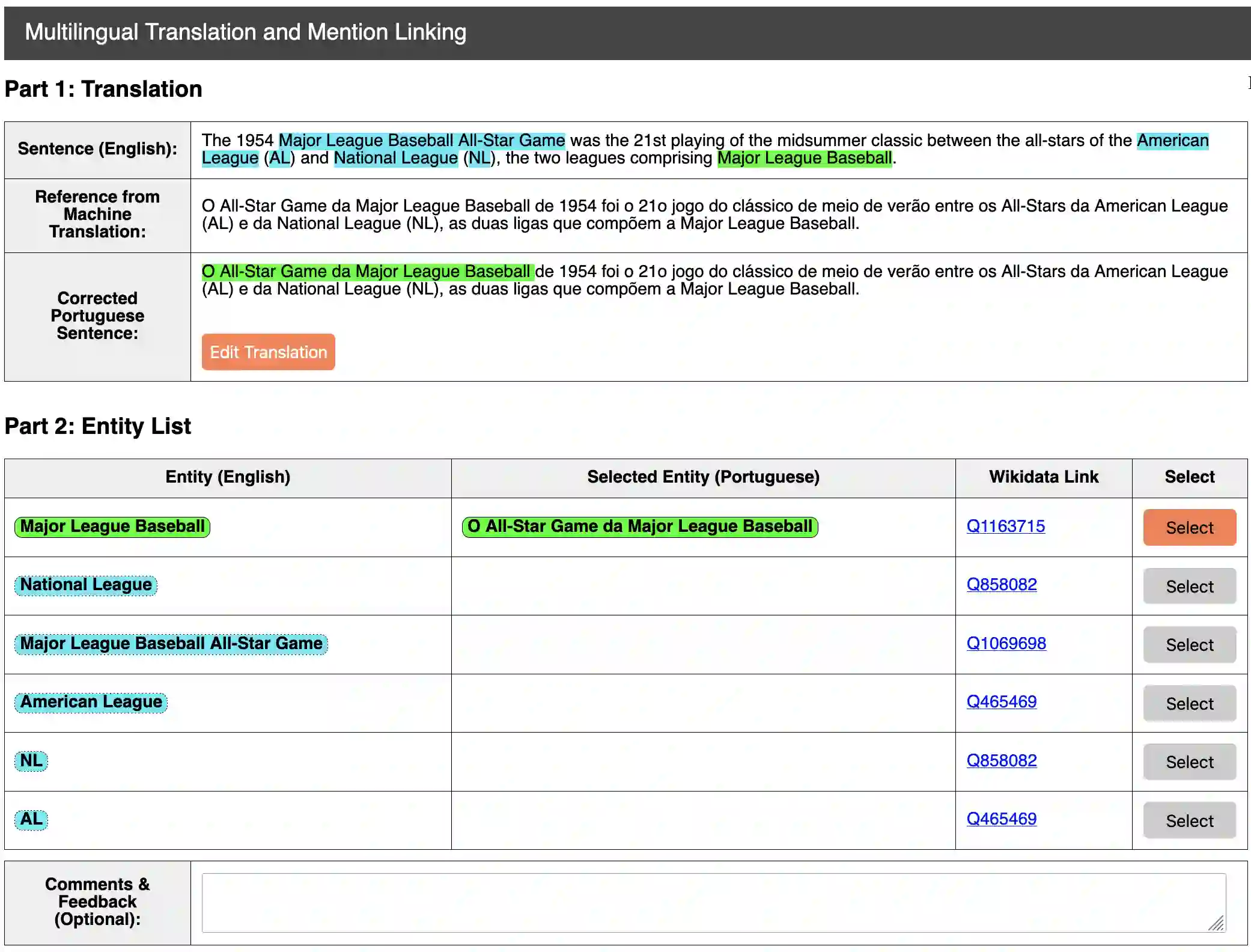
Extracting structured and grounded fact triples from raw text is a fundamental task in Information Extraction (IE). Existing IE datasets are typically collected from Wikipedia articles, using hyperlinks to link entities to the Wikidata knowledge base. However, models trained only on Wikipedia have limitations when applied to web domains, which often contain noisy text or text that does not have any factual information. We present WebIE, the first large-scale, entity-linked closed IE dataset consisting of 1.6M sentences automatically collected from the English Common Crawl corpus. WebIE also includes negative examples, i.e. sentences without fact triples, to better reflect the data on the web. We annotate ~25K triples from WebIE through crowdsourcing and introduce mWebIE, a translation of the annotated set in four other languages: French, Spanish, Portuguese, and Hindi. We evaluate the in-domain, out-of-domain, and zero-shot cross-lingual performance of generative IE models and find models trained on WebIE show better generalisability. We also propose three training strategies that use entity linking as an auxiliary task. Our experiments show that adding Entity-Linking objectives improves the faithfulness of our generative IE models.
翻译:从原始文本中提取结构化且基于事实的三元组是信息抽取(Information Extraction, IE)中的一项基本任务。现有IE数据集通常从维基百科文章中收集,利用超链接将实体链接到维基数据知识库。然而,仅基于维基百科训练的模型在应用于网络领域时存在局限性,因为网络文本常包含噪声或缺乏事实信息。我们提出了WebIE,这是首个大规模、实体链接的封闭式IE数据集,包含从英文Common Crawl语料库中自动收集的160万条句子。WebIE还包含负例(即不含事实三元组的句子),以更好地反映网络数据的特点。我们通过众包从WebIE中标注了约2.5万个三元组,并引入了mWebIE,即该标注集在其他四种语言(法语、西班牙语、葡萄牙语和印地语)中的翻译版本。我们评估了生成式IE模型在域内、域外和零样本跨语言场景下的表现,发现基于WebIE训练的模型展现出更强的泛化能力。我们还提出了三种将实体链接作为辅助任务的训练策略。实验表明,增加实体链接目标能提升生成式IE模型的忠实度。