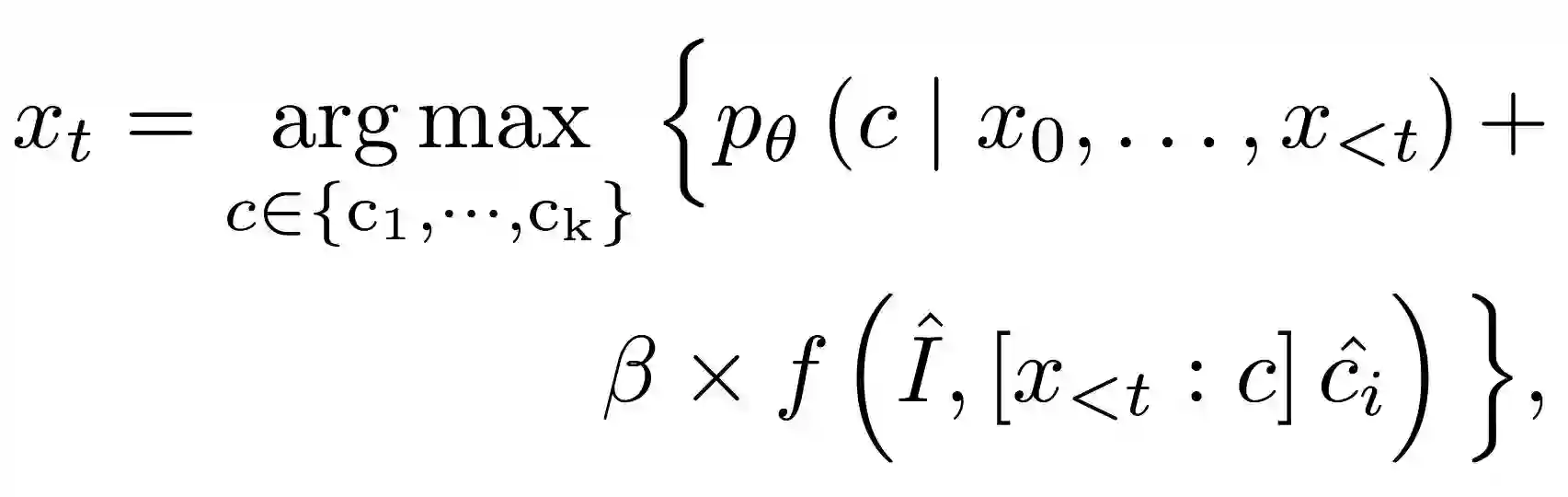Zero-shot audio captioning aims at automatically generating descriptive textual captions for audio content without prior training for this task. Different from speech recognition which translates audio content that contains spoken language into text, audio captioning is commonly concerned with ambient sounds, or sounds produced by a human performing an action. Inspired by zero-shot image captioning methods, we propose ZerAuCap, a novel framework for summarising such general audio signals in a text caption without requiring task-specific training. In particular, our framework exploits a pre-trained large language model (LLM) for generating the text which is guided by a pre-trained audio-language model to produce captions that describe the audio content. Additionally, we use audio context keywords that prompt the language model to generate text that is broadly relevant to sounds. Our proposed framework achieves state-of-the-art results in zero-shot audio captioning on the AudioCaps and Clotho datasets. Our code is available at https://github.com/ExplainableML/ZerAuCap.
翻译:零样本音频描述生成旨在自动为音频内容生成描述性文本,而无需针对该任务进行预先训练。与将包含语音内容的音频转化为文本的语音识别不同,音频描述生成通常关注环境声音或人类执行动作时产生的声音。受零样本图像描述生成方法的启发,我们提出了ZerAuCap——一种新颖的框架,用于将此类通用音频信号总结为文本描述,且无需任务特异性训练。具体而言,该框架利用预训练大型语言模型(LLM),通过预训练音频-语言模型引导其生成描述音频内容的文本。此外,我们采用音频上下文关键词触发语言模型生成与声音广泛相关的文本。所提框架在AudioCaps和Clotho数据集上的零样本音频描述生成任务中达到了最先进水平。代码已开源至https://github.com/ExplainableML/ZerAuCap。