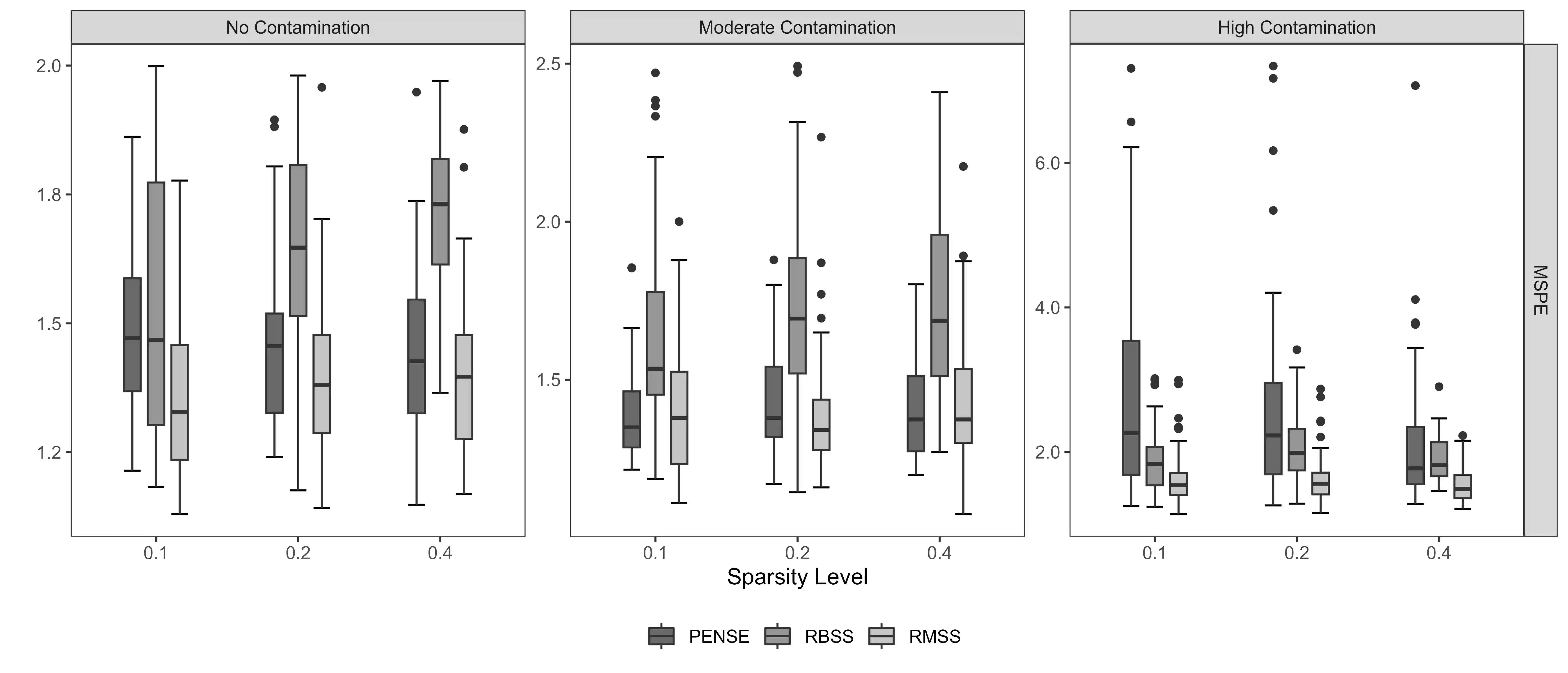
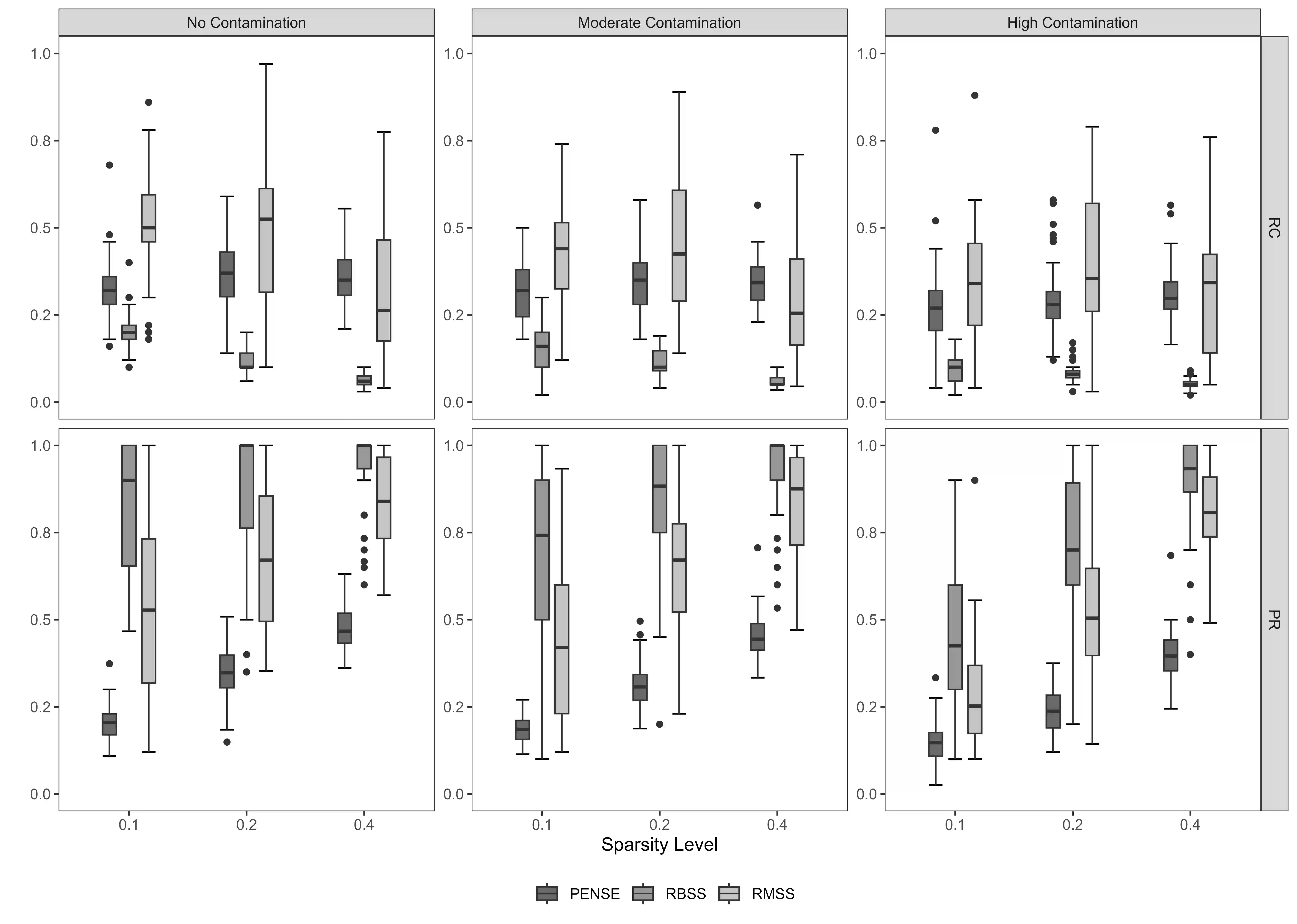
Outlying observations can be challenging to handle and adversely affect subsequent analyses, particularly, in complex high-dimensional datasets. Although outliers are not always undesired anomalies in the data and may possess valuable insights, only methods that are robust to outliers are able to accurately identify them and resist their influence. In this paper, we propose a method that generates an ensemble of sparse and diverse predictive models that are resistant to outliers. We show that the ensembles generally outperform single-model sparse and robust methods in high-dimensional prediction tasks. Cross-validation is used to tune model parameters to control levels of sparsity, diversity and resistance to outliers. We establish the finitesample breakdown point of the ensembles and the models that comprise them, and we develop a tailored computing algorithm to learn the ensembles by leveraging recent developments in L0 optimization. Our extensive numerical experiments on synthetic and artificially contaminated real datasets from bioinformatics and cheminformatics demonstrate the competitive advantage of our method over state-of-the-art single-model methods.
翻译:异常观测值处理起来可能具有挑战性,并且会对后续分析产生不利影响,尤其是在复杂的高维数据集中。尽管异常值并非总是数据中不受欢迎的异常现象,并且可能蕴含宝贵的洞见,但只有对异常值具有鲁棒性的方法才能准确识别它们并抵抗其影响。本文提出一种方法,能够生成一组稀疏且多样化的预测模型,这些模型对异常值具有抵抗力。我们证明,在高维预测任务中,集成方法通常优于单模型的稀疏鲁棒方法。我们使用交叉验证来调整模型参数,以控制稀疏度、多样性及对异常值的抵抗水平。我们建立了集成模型及其组成模型的有限样本崩溃点,并开发了一种定制的计算算法,通过利用L0优化领域的最新进展来学习这些集成模型。我们在合成数据以及来自生物信息学和化学信息学的人工污染真实数据集上进行的广泛数值实验表明,我们的方法相较于最先进的单模型方法具有竞争优势。