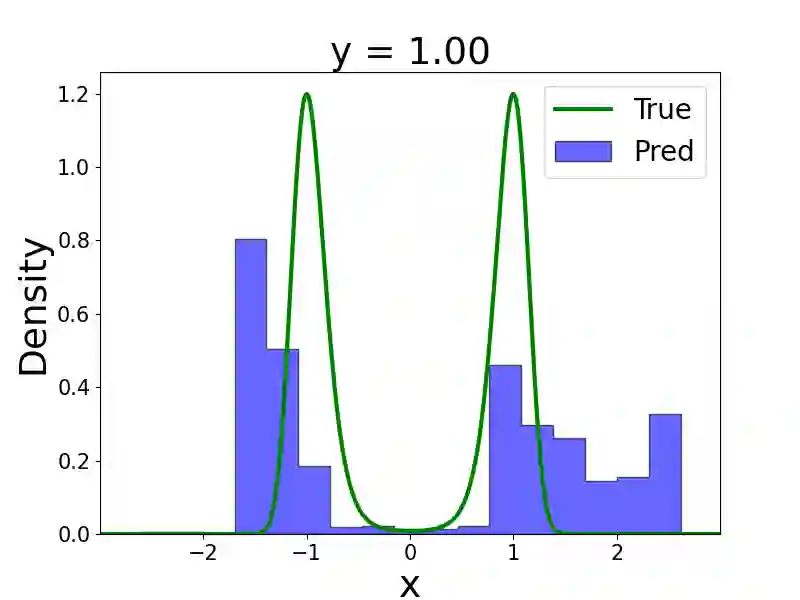
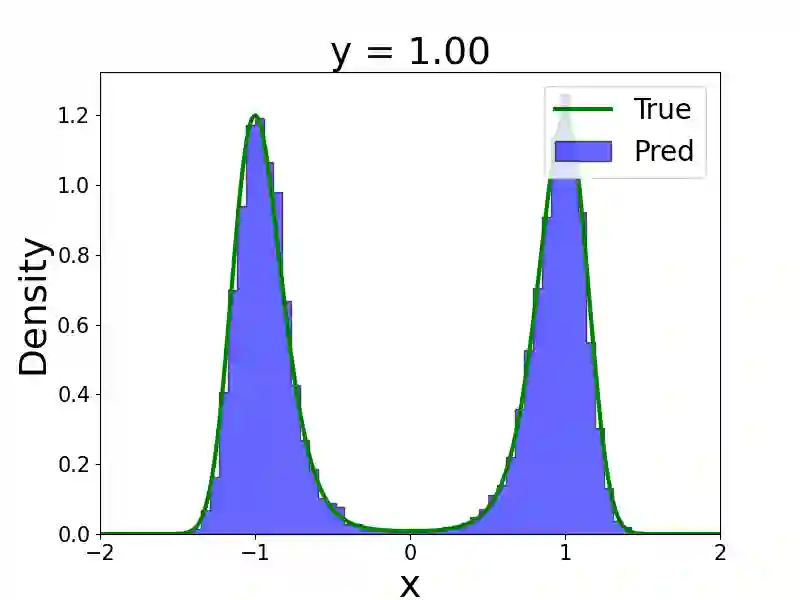
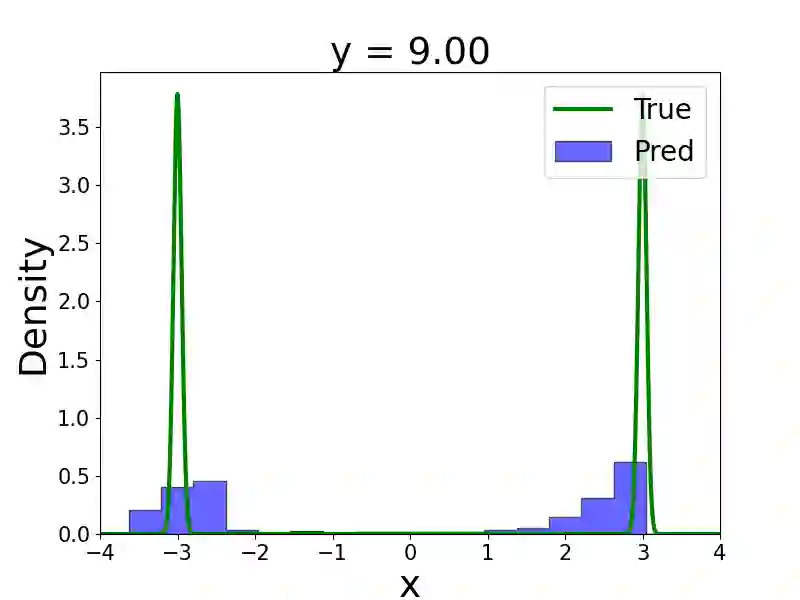
We present a multi-fidelity method for uncertainty quantification of parameter estimates in complex systems, leveraging generative models trained to sample the target conditional distribution. In the Bayesian inference setting, traditional parameter estimation methods rely on repeated simulations of potentially expensive forward models to determine the posterior distribution of the parameter values, which may result in computationally intractable workflows. Furthermore, methods such as Markov Chain Monte Carlo (MCMC) necessitate rerunning the entire algorithm for each new data observation, further increasing the computational burden. Hence, we propose a novel method for efficiently obtaining posterior distributions of parameter estimates for high-fidelity models given data observations of interest. The method first constructs a low-fidelity, conditional generative model capable of amortized Bayesian inference and hence rapid posterior density approximation over a wide-range of data observations. When higher accuracy is needed for a specific data observation, the method employs adaptive refinement of the density approximation. It uses outputs from the low-fidelity generative model to refine the parameter sampling space, ensuring efficient use of the computationally expensive high-fidelity solver. Subsequently, a high-fidelity, unconditional generative model is trained to achieve greater accuracy in the target posterior distribution. Both low- and high- fidelity generative models enable efficient sampling from the target posterior and do not require repeated simulation of the high-fidelity forward model. We demonstrate the effectiveness of the proposed method on several numerical examples, including cases with multi-modal densities, as well as an application in plasma physics for a runaway electron simulation model.
翻译:我们提出了一种多保真度方法,用于量化复杂系统中参数估计的不确定性,该方法利用经过训练以采样目标条件分布的生成模型。在贝叶斯推断框架下,传统的参数估计方法依赖于对可能计算成本高昂的正向模型进行重复模拟,以确定参数值的后验分布,这可能导致计算上不可行的工作流程。此外,诸如马尔可夫链蒙特卡洛(MCMC)等方法需要对每个新的数据观测重新运行整个算法,进一步增加了计算负担。因此,我们提出了一种新颖的方法,用于在给定感兴趣的数据观测下,高效地获取高保真度模型的参数估计后验分布。该方法首先构建一个低保真度的条件生成模型,该模型能够进行摊销贝叶斯推断,从而在广泛的数据观测范围内快速近似后验密度。当针对特定数据观测需要更高精度时,该方法采用密度近似的自适应细化。它利用低保真度生成模型的输出来细化参数采样空间,确保高效利用计算成本高昂的高保真度求解器。随后,训练一个高保真度的无条件生成模型,以在目标后验分布中实现更高的精度。低保真度和高保真度生成模型都能够从目标后验中高效采样,且无需重复模拟高保真度正向模型。我们在多个数值示例上证明了所提方法的有效性,包括具有多模态密度的情况,以及在等离子体物理中逃逸电子模拟模型的应用。