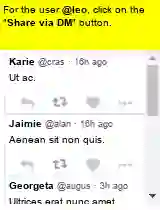
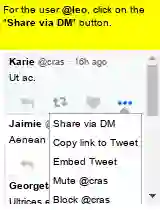
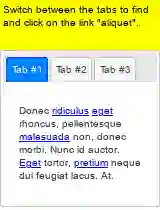
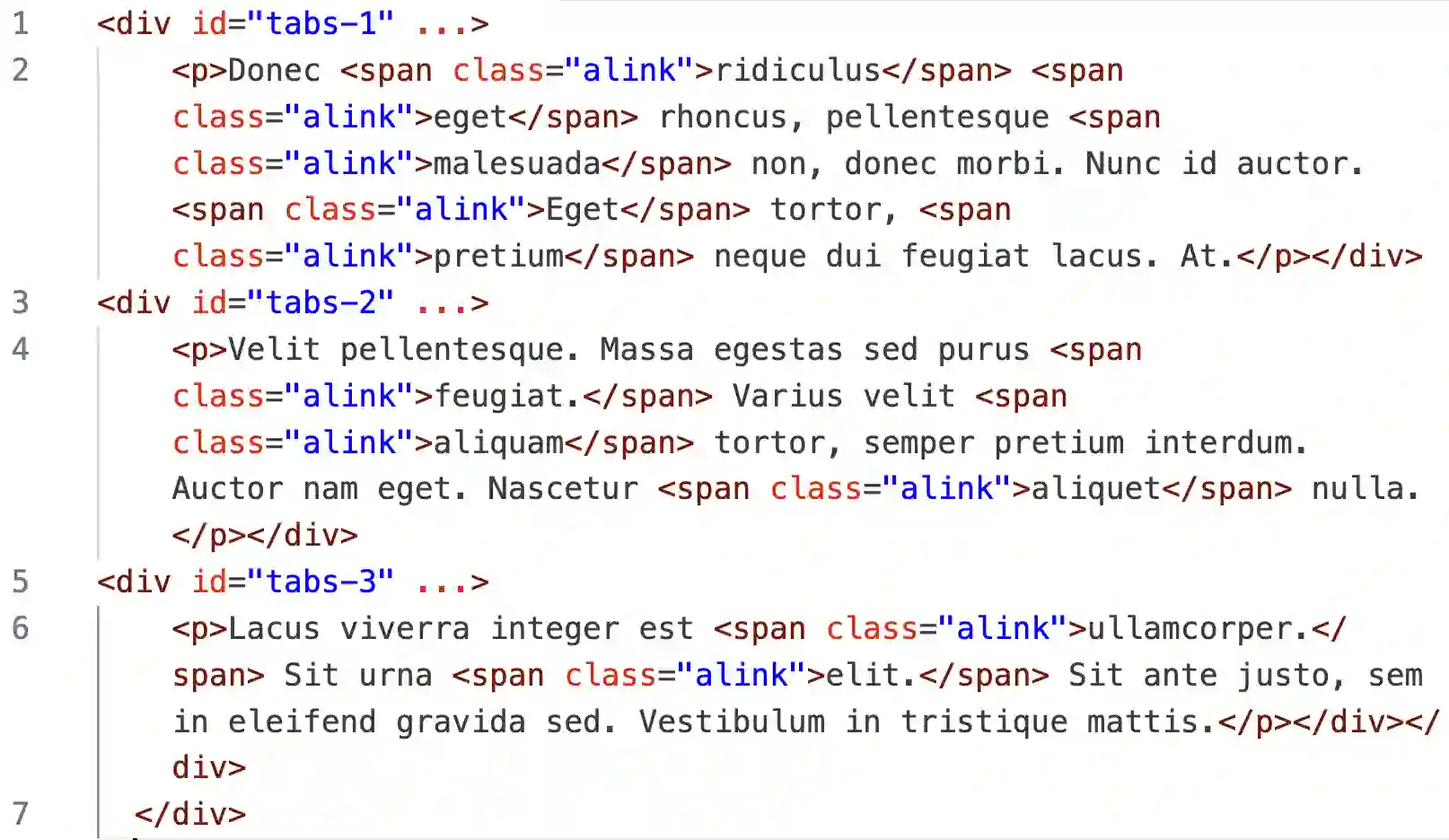
Large language models (LLMs) have shown increasing capacity at planning and executing a high-level goal in a live computer environment (e.g. MiniWoB++). To perform a task, recent works often require a model to learn from trace examples of the task via either supervised learning or few/many-shot prompting. Without these trace examples, it remains a challenge how an agent can autonomously learn and improve its control on a computer, which limits the ability of an agent to perform a new task. We approach this problem with a zero-shot agent that requires no given expert traces. Our agent plans for executable actions on a partially observed environment, and iteratively progresses a task by identifying and learning from its mistakes via self-reflection and structured thought management. On the easy tasks of MiniWoB++, we show that our zero-shot agent often outperforms recent SoTAs, with more efficient reasoning. For tasks with more complexity, our reflective agent performs on par with prior best models, even though previous works had the advantages of accessing expert traces or additional screen information.
翻译:大型语言模型在实时计算机环境(如MiniWoB++)中规划和执行高层目标的能力日益增强。现有方法通常要求模型通过监督学习或少量/多样本提示学习任务轨迹样例才能完成任务。若缺乏轨迹样例,代理如何自主学习和改善计算机控制能力仍是一项挑战,这限制了代理执行新任务的能力。本文提出一种无需专家轨迹样例的零样本代理方法。该代理在部分可观测环境中规划可执行动作,通过自我反思和结构化思维管理识别并学习自身错误,从而迭代推进任务进程。在MiniWoB++简单任务中,我们的零样本代理不仅以更高效的推理模式超越近期最先进方法,在复杂度更高的任务中,即使此前方法具备访问专家轨迹或补充屏幕信息的优势,我们的反思代理仍能达到与先前最优模型相当的性能。