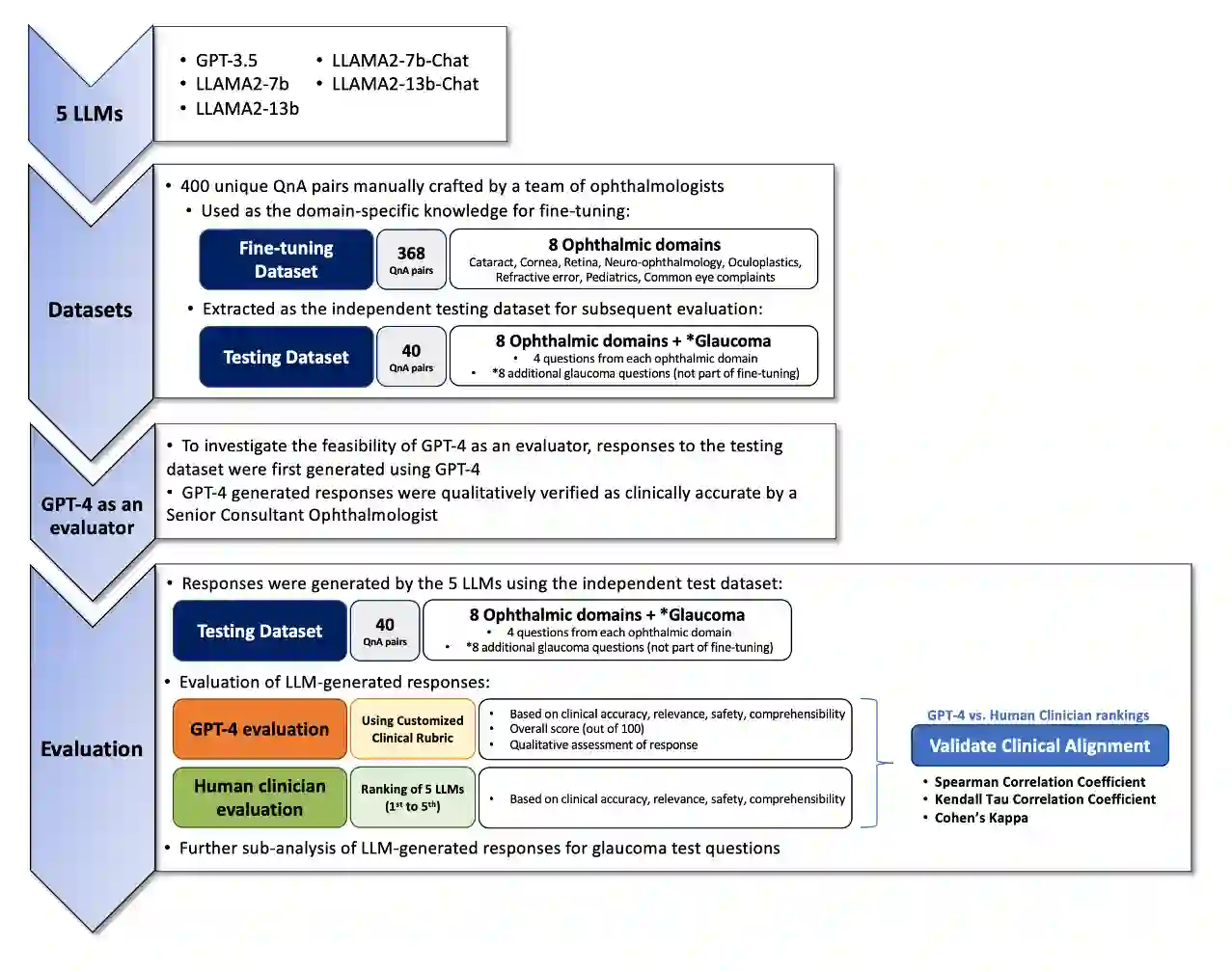
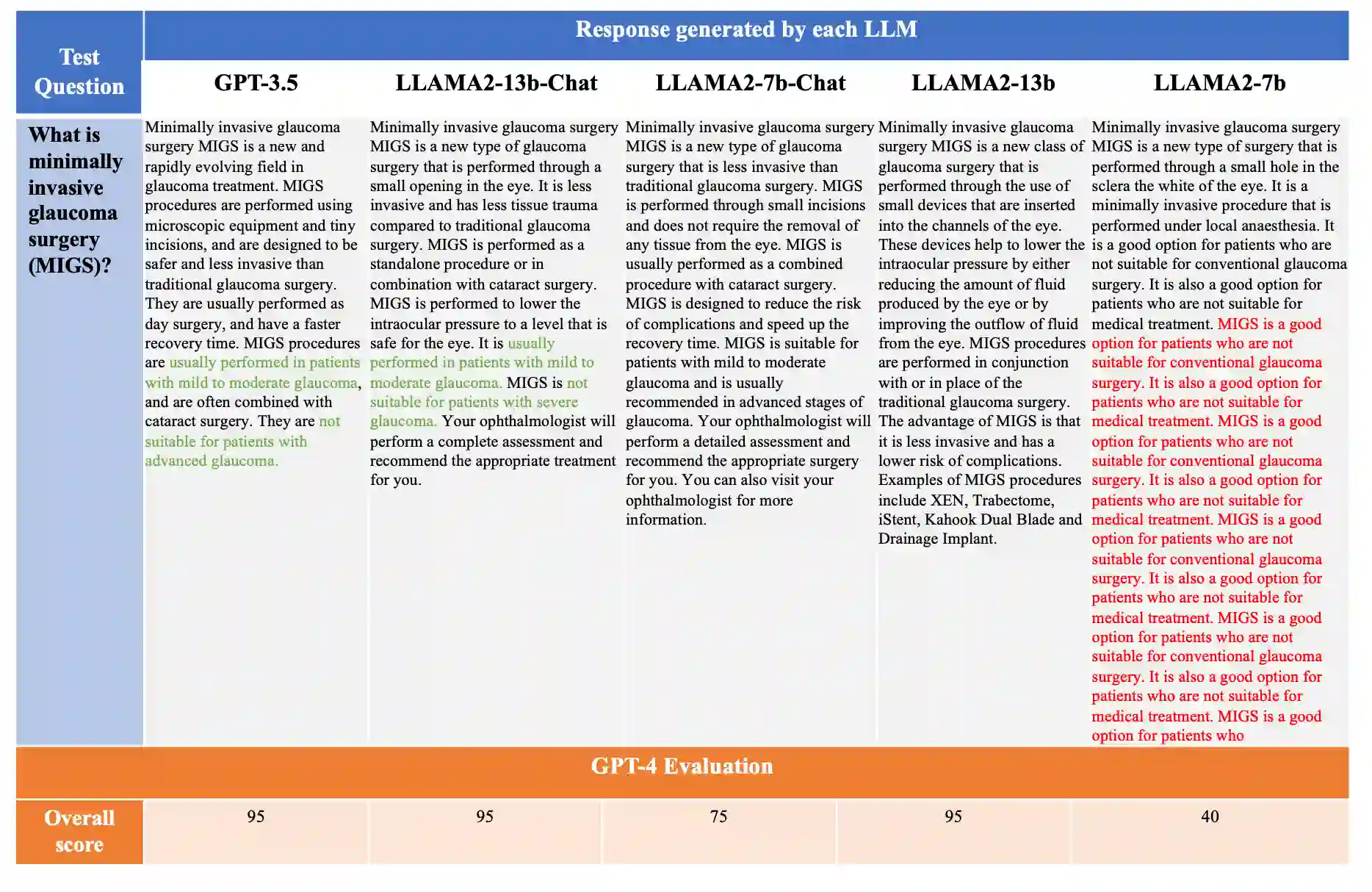
Purpose: To assess the alignment of GPT-4-based evaluation to human clinician experts, for the evaluation of responses to ophthalmology-related patient queries generated by fine-tuned LLM chatbots. Methods: 400 ophthalmology questions and paired answers were created by ophthalmologists to represent commonly asked patient questions, divided into fine-tuning (368; 92%), and testing (40; 8%). We find-tuned 5 different LLMs, including LLAMA2-7b, LLAMA2-7b-Chat, LLAMA2-13b, and LLAMA2-13b-Chat. For the testing dataset, additional 8 glaucoma QnA pairs were included. 200 responses to the testing dataset were generated by 5 fine-tuned LLMs for evaluation. A customized clinical evaluation rubric was used to guide GPT-4 evaluation, grounded on clinical accuracy, relevance, patient safety, and ease of understanding. GPT-4 evaluation was then compared against ranking by 5 clinicians for clinical alignment. Results: Among all fine-tuned LLMs, GPT-3.5 scored the highest (87.1%), followed by LLAMA2-13b (80.9%), LLAMA2-13b-chat (75.5%), LLAMA2-7b-Chat (70%) and LLAMA2-7b (68.8%) based on the GPT-4 evaluation. GPT-4 evaluation demonstrated significant agreement with human clinician rankings, with Spearman and Kendall Tau correlation coefficients of 0.90 and 0.80 respectively; while correlation based on Cohen Kappa was more modest at 0.50. Notably, qualitative analysis and the glaucoma sub-analysis revealed clinical inaccuracies in the LLM-generated responses, which were appropriately identified by the GPT-4 evaluation. Conclusion: The notable clinical alignment of GPT-4 evaluation highlighted its potential to streamline the clinical evaluation of LLM chatbot responses to healthcare-related queries. By complementing the existing clinician-dependent manual grading, this efficient and automated evaluation could assist the validation of future developments in LLM applications for healthcare.
翻译:目的:评估基于GPT-4的评估与临床人类专家评价之间的一致性,以评估经微调的大语言模型(LLM)聊天机器人针对眼科患者常见问题生成的回答质量。方法:由眼科医师创建400组眼科相关问题及其配对答案,代表患者常见疑问。数据集分为微调集(368组,占92%)和测试集(40组,占8%)。我们微调了5种不同的大语言模型,包括LLAMA2-7b、LLAMA2-7b-Chat、LLAMA2-13b和LLAMA2-13b-Chat。测试集额外纳入8组青光眼问答对。5种微调后的LLM模型针对测试集生成200个回答以供评估。采用定制化临床评估量表引导GPT-4评估,该量表基于临床准确性、相关性、患者安全性和易理解性四大维度。随后将GPT-4评价结果与5位临床医师的排序结果进行临床一致性比较。结果:在所有微调后的LLM模型中,基于GPT-4评估,GPT-3.5得分最高(87.1%),其次依次为LLAMA2-13b(80.9%)、LLAMA2-13b-chat(75.5%)、LLAMA2-7b-Chat(70%)和LLAMA2-7b(68.8%)。GPT-4评估与人类临床医师排序呈现显著一致性:斯皮尔曼相关系数为0.90,肯德尔等级相关系数为0.80;但基于Cohen's Kappa系数的一致性较低(0.50)。值得注意的是,定性分析和青光眼亚组分析揭示了LLM生成回答中的临床不准确性,而GPT-4评估能够准确识别这些问题。结论:GPT-4评估展现的显著临床一致性凸显其简化LLM聊天机器人医疗相关问答临床评估流程的潜力。通过补充现有依赖临床医师的人工评分体系,这种高效的自动化评估方法可助力验证LLM在医疗领域应用的未来发展。