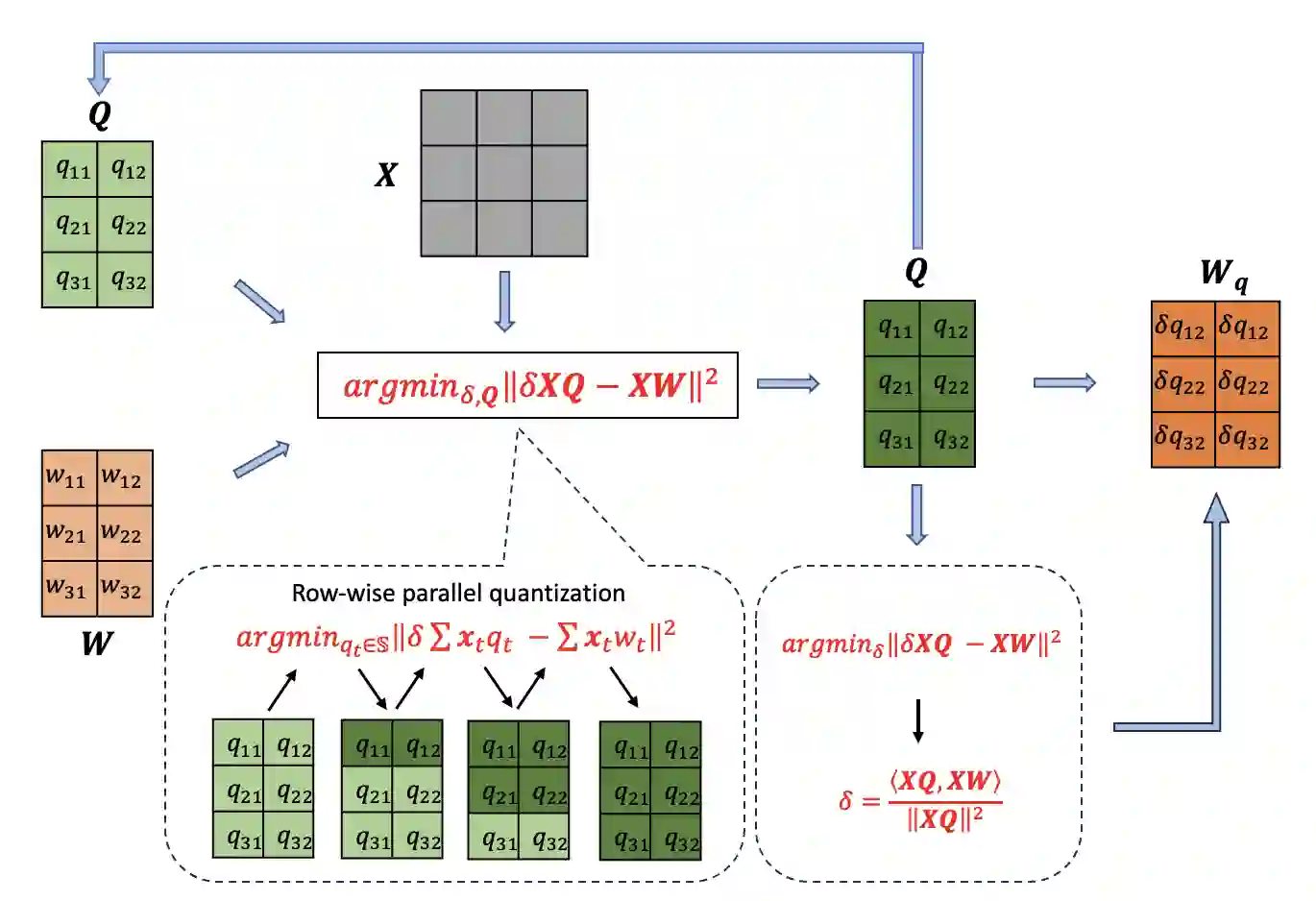
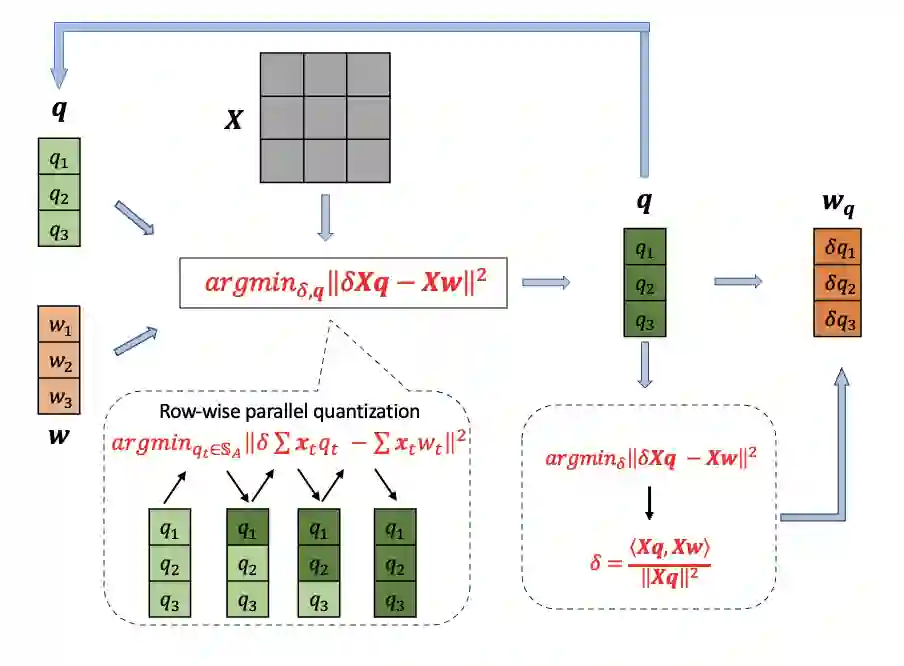
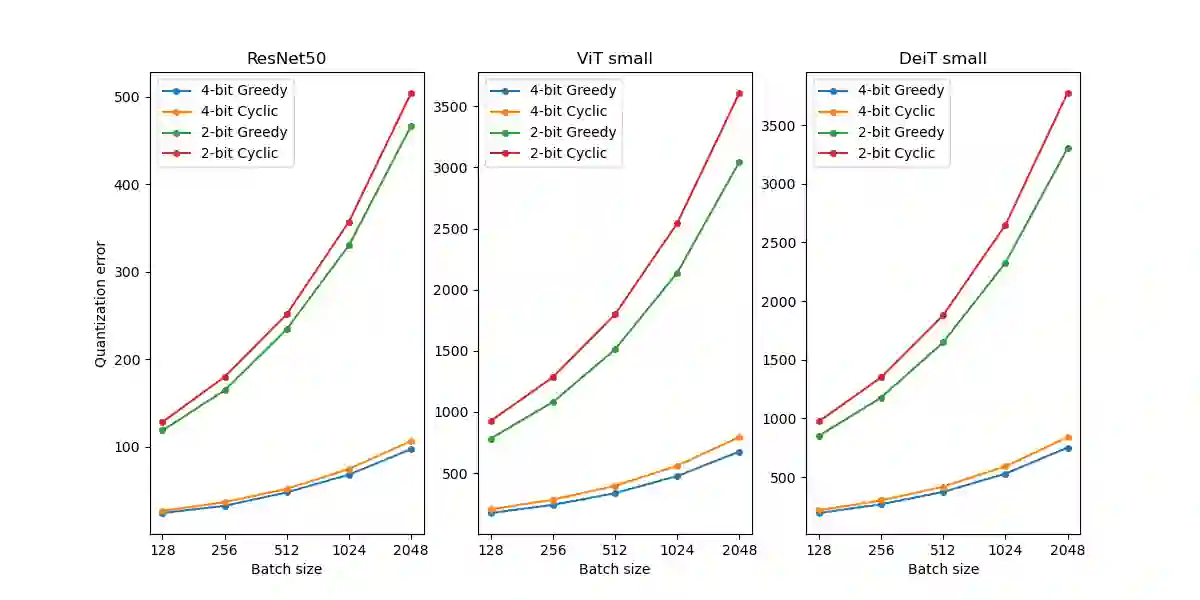
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
翻译:训练后量化(PTQ)已成为压缩大型神经网络的一种实用方法,使其在部署时具有极高的效率。然而,如何在不损害原始准确性的前提下,有效地将这些模型压缩为低比特版本,仍然是一个关键挑战。本文提出了一种创新的PTQ算法,称为COMQ,该算法通过逐层顺序执行重构误差的坐标最小化来实现量化。我们考虑广泛使用的整数量化,其中每个量化权重可以分解为一个共享的浮点标量和一个整数比特码。在固定层内,COMQ将所有缩放因子和比特码视为重构误差的变量。每次迭代沿单个坐标改进此误差,同时保持所有其他变量不变。COMQ易于使用,无需超参数调优,仅涉及点积和舍入操作。我们按照精心设计的贪心顺序更新这些变量,从而显著提高了准确性。COMQ在4位视觉Transformer量化方面取得了显著成果,Top-1准确率损失可忽略不计(小于1%)。在卷积神经网络的4位INT量化中,COMQ保持了近乎无损的准确性,Top-1准确率仅下降0.3%。