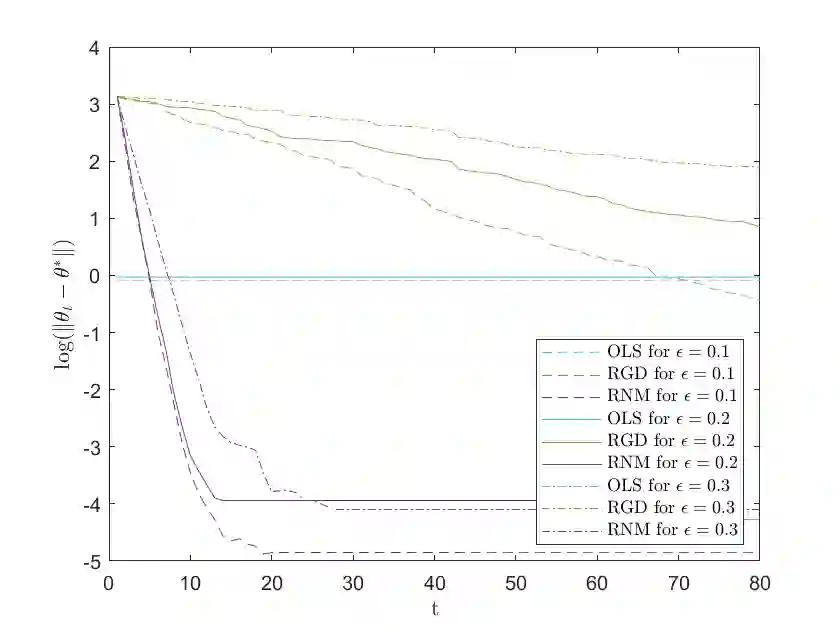
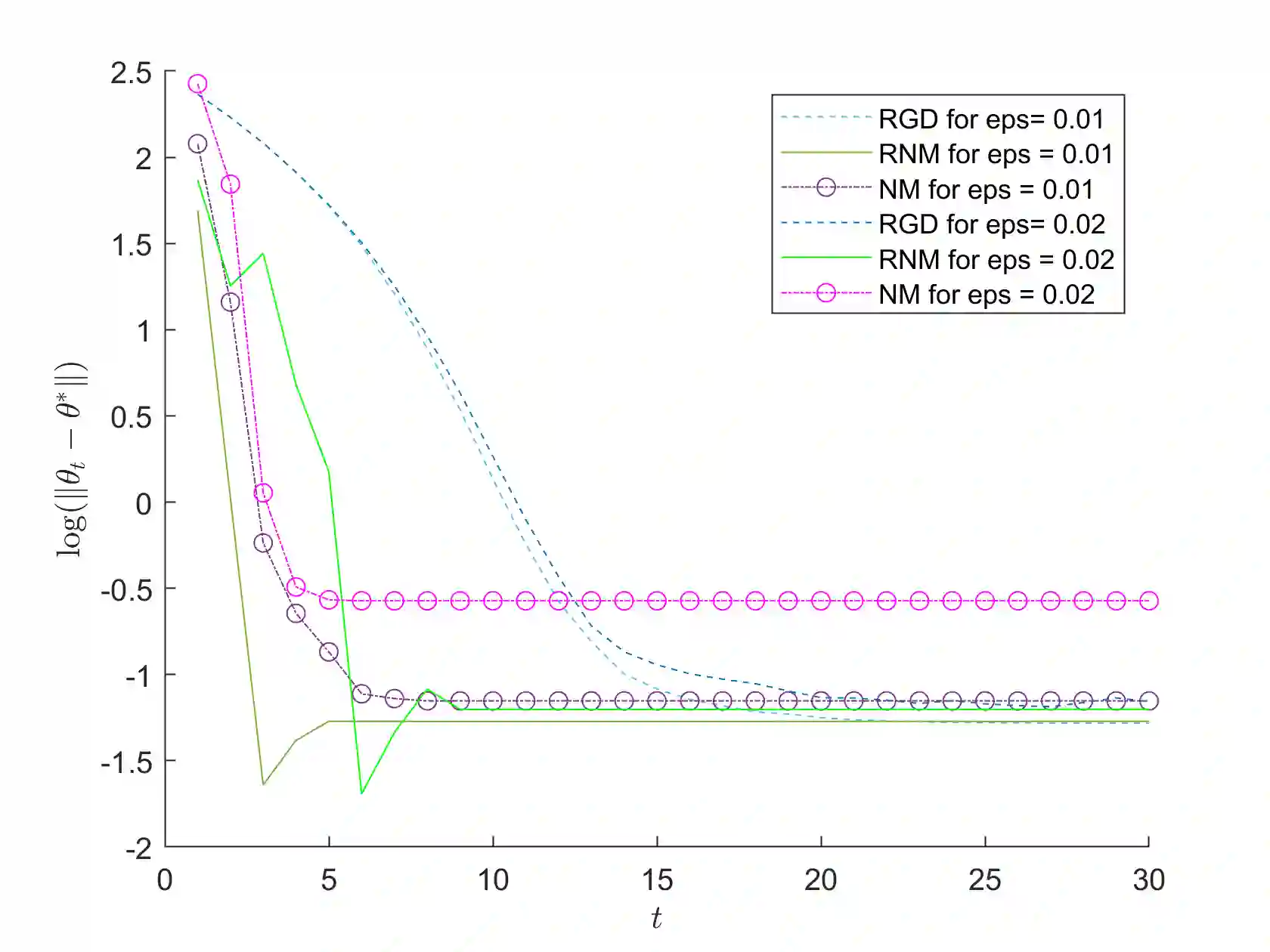
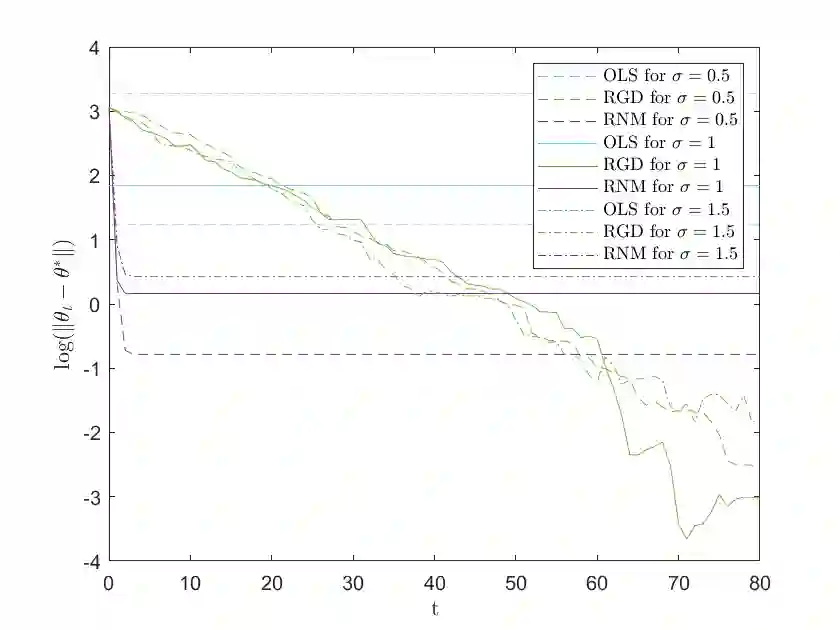
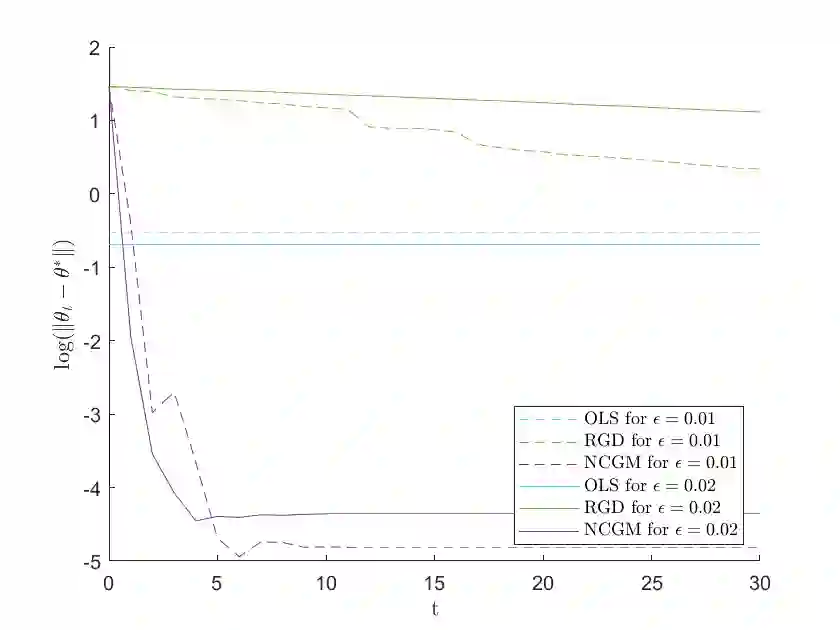
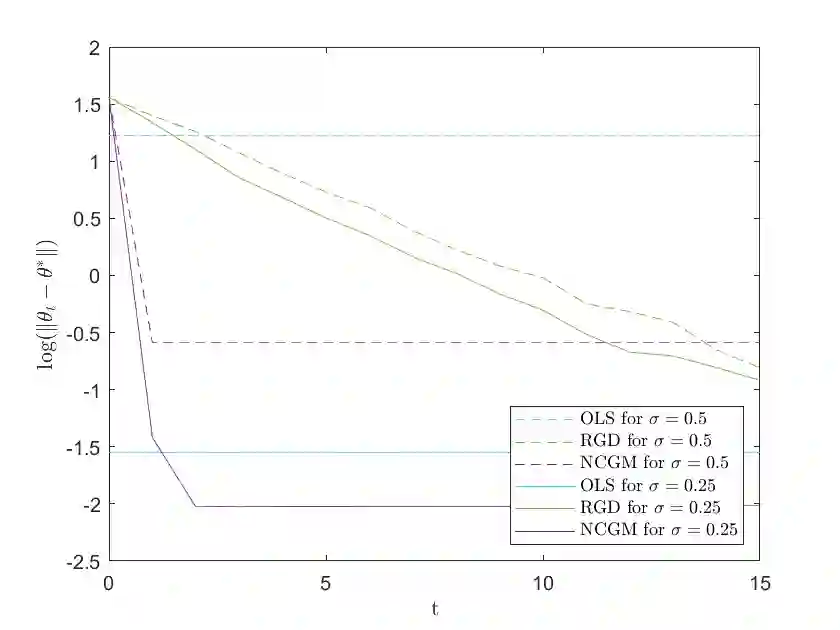
We study a variant of Newton's method for empirical risk minimization, where at each iteration of the optimization algorithm, we replace the gradient and Hessian of the objective function by robust estimators taken from existing literature on robust mean estimation for multivariate data. After proving a general theorem about the convergence of successive iterates to a small ball around the population-level minimizer, we study consequences of our theory in generalized linear models, when data are generated from Huber's epsilon-contamination model and/or heavy-tailed distributions. We also propose an algorithm for obtaining robust Newton directions based on the conjugate gradient method, which may be more appropriate for high-dimensional settings, and provide conjectures about the convergence of the resulting algorithm. Compared to the robust gradient descent algorithm proposed by Prasad et al. (2020), our algorithm enjoys the faster rates of convergence for successive iterates often achieved by second-order algorithms for convex problems, i.e., quadratic convergence in a neighborhood of the optimum, with a stepsize that may be chosen adaptively via backtracking linesearch.
翻译:我们研究了一种用于经验风险最小化的牛顿法变体,其中在优化算法的每次迭代中,我们使用来自多变量数据鲁棒均值估计现有文献中的鲁棒估计量替换目标函数的梯度和黑塞矩阵。在证明了连续迭代收敛到总体最小化器附近一个小球的通用定理后,我们研究了该理论在广义线性模型中的结果,其中数据来自Huber的ε污染模型和/或重尾分布。我们还提出了一种基于共轭梯度法获取鲁棒牛顿方向的算法,该算法可能更适合高维场景,并给出了该算法收敛性的猜想。与Prasad等人(2020年)提出的鲁棒梯度下降算法相比,我们的算法在凸问题中通常具有二阶算法所实现的连续迭代更快收敛速度,即在最优解附近达到二次收敛,且步长可通过回溯线搜索自适应选择。